BC/NW 2007, №2, (11) :10.4
Параллельное программирование в MATLAB
Чернецов А.М., Печенкин Р.В.
(Москва, Московский энергетический институт (технический университет), Вычислительный центр имени А.А. Дородницына Российской академии наук, ЗАО “Силовые машины”, Россия)
В данном докладе рассматривается технология распределенных и параллельных вычислений, реализованная компанией MathWorks с помощью двух взаимосвязанных пакетов расширений (toolbox): MATLAB Distributed Computing toolbox [1] и MATLAB Distributed Computing Engine [2].
На рис. 1 представлена общая схема работы с произвольной задачей.
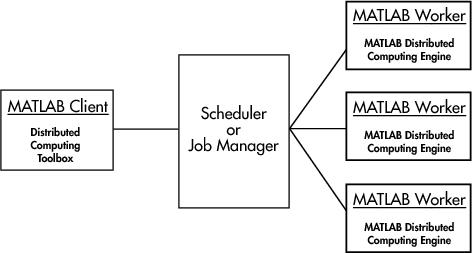
Рис. 1. Общая схема распределенных вычислений MATLAB.
Клиент через планировщик Scheduler запрашивает ресурсы рабочих процессов (workers). В его качестве может выступать как узел кластера, так и процессор SMP-системы. Все взаимодействия происходят через запущенную на каждом узле службу MDCE. В качестве планировщика выступает либо фирменный MathWorks Job Manager, либо можно использовать довольно широкий набор других планировщиков [3].
Межпроцессные обмены реализованы средствами библиотеки MPI mpich2 v. 1.0.3. Вместо этой реализации можно использовать другие, удовлетворяющие определенным требованиям (см . [3]). В данном докладе рассматривается стандартная реализация.
Для запуска параллельной задачи необходимо иметь запущенными на клиенте службу MDCE, планировщик Job Manager. Для каждого узла, на котором запущены рабочие процессы, необходимо иметь запущенную службу MDCE и рабочий процесс worker. Подробно все эти процедуры описаны в [1-3]. Здесь мы укажем лишь их названия и выполняемые действия.
|
Название |
Действие |
|
mdce start mdce stop |
Запуск службы MDCE Останов службы MDCE |
|
startjobmanager stopjobmanager |
Запуск планировщика Job Manager Останов планировщика Job Manager |
|
startworker stopworker |
Запуск рабочего процесса Останов рабочего процесса |
|
nodestatus |
Запрос информации о запущенных процессах и планировщиках |
Методология MathWorks выделяет отдельно распределенные (distributed) и параллельные (parallel) задачи. Примером первых является распределенное LU-разложение матрицы, когда матрица разделяется на блоки автоматически средствами MATLAB. Ко вторым относятся задачи, в которых межпроцессные обмены заданы явно с использованием специальных процедур, аналогичных средствам MPI [1, 3].
В данном докладе распределенные процедуры не рассматриваются, поскольку большая их часть ничем не отличается от стандартных последовательных процедур MATLAB. С документацией по этой теме можно ознакомиться в [1].
В MATLAB в настоящее время существует два подхода для
решения параллельных задач. Первый подход основан непосредственно на процедуре
отправки задания Job Manager, в
инструкциях (.m - файле) которой описана последовательность команд, которая
будут выполняться рабочими процессами. В этом .m файле помимо основных команд
MATLAB могут быть использованы функции MPI для коммуникаций между рабочими
процессами. Второй подход для решения параллельных задач основан на режиме
pmode. С помощью этого режима непосредственно из командного окна MATLAB
становится возможным обращение к процессам workers, просмотр их локальных
переменных, обмен данными между ними. В режиме pmode команды, вводимые в
рабочем окне MATLAB, будут исполняться всеми рабочими процессами,
ассоциированными с соответствующим jobmanager.
Режим pmode, по мнению авторов, следует использовать
исключительно с двумя целями: как удобный пользовательский режим,
предназначенный для первоначального знакомства с элементами параллельного
программирования и как средство отладки параллельных программ. В [3] рассмотрен пример параллельного вычисления числа p.
Используемые команды:
|
pmode start |
Запустить режим pmode |
|
pmode suspend |
Вернуться в клиентскую сессию |
|
pmode resume |
Восстановить режим pmode |
|
Labindex |
ID процесса |
|
Numlabs |
Число процессов |
|
gplus(x) |
Суммирование |
|
pmode lab2client |
Вернуть значение переменной из процесса в клиентскую сессию |
Более интересные примеры можно рассмотреть, использовав первый подход.
Приведем основные функции передачи сообщений в MATLAB и их аналоги в MPI.
|
Функция/переменная MATLAB |
Функция/переменная MPI |
|
Numlabs |
MPI_Comm_size(size)
|
|
Labindex |
MPI_Comm_rank(rank, MPI_COMM_WORLD) |
|
LabBarrier()
|
MPI_Barrier(MPI_COMM_WORLD)
|
|
Shared_data=LabBroadcast(root,buffer)
|
MPI_Bcast(void* buffer, int count, MPI_Datatype datatype, int root, MPI_COMM_WORLD)
|
|
LabSend(buf,dest) MPI_Send(void *buf, int count, LabSend(data,dest,tag)
|
MPI_Send(void *buf, int count, int tag, MPI_COMM_WORLD)
|
|
data=LabReceive(source,tag) MPI_Recv(void*buf,int count, data=LabReceive('any',tag)
|
MPI_Recv(void *buf, int count, MPI_COMM_WORLD, MPI_Status *status)
|
|
is_data_available=LabProbe(source,tag)
|
MPI_Probe(int source, int tag, MPI_COMM_WORLD, MPI_Status *status)
|
В [3] рассмотрена параллельная реализация в среде MATLAB задач линейной алгебры – матричного умножения и решения СЛАУ методом Гаусса. Вторая задача решалась на кластере ВЦ РАН [4]. График полученного ускорения для размерности 1024 приведен на рис. 2.
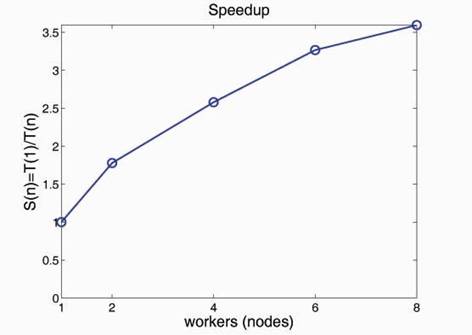
Рис. 2. Ускорение метода Гаусса.
Полученные плохие значения ускорения при n >4 объясняются тем, что задача дробится на слишком мелкие подзадачи, взаимодействие между которыми осуществляется через Job Manager, написанный на Java.
Последняя на момент написания работы версия MATLAB 2007a расширяет возможности параллельного программирования. Появился параллельный отладчик, функции ядра MATLAB для многопроцессорных и многоядерных систем стали автоматически распараллеливаться с использованием нитей.
В заключение авторы выражают благодарность департаменту MathWorks компании Softline за возможность ознакомиться и протестировать технологические возможности, заложенные в MATLAB Distributing Computing Engine.
ЛИТЕРАТУРА
1. http://www.mathworks.com/access/helpdesk/help/pdf_doc/distcomp/distcomp.pdf
2. http://www.mathworks.com/access/helpdesk/help/pdf_doc/mdce/mdce.pdf
3. Оленев Н.Н., Печенкин Р.В, Чернецов А.М. “Параллельное программирование в MATLAB”, М.: ВЦ РАН, 2007, 117 с.
4. Михайлов Г.М, Копытов М.А., Рогов Ю.П., Самоваров О.И., Чернецов А.М. “Параллельные вычислительные системы в локальной сети ВЦ РАН”, М., Издательство ВЦ РАН, 2003, 75 с.