BC/NW 2007, №2, (11) :3.2
ВАРИАНТЫ РАСШИРЕНИЯ АРХИТЕКТУРЫ
ПАРАЛЛЕЛЬНОЙ МУЛЬТИКОМПЬЮТЕРНОЙ СЕТИ
Дзегеленок И.И., Ильин П.Е.
(Московский Энергетический Институт, Москва, Россия)
В настоящее время одним из направлений развития информационных технологий являются распределенные вычисления, которые позволяют повысить эффективность решения ряда задач за счет обработки данных по месту их возникновения. Однако переход к распределенным вычислениям создает ряд новых проблем, отсутствовавших при централизованной обработке данных. В частности, к таковым относятся отслеживание доступных вычислительных ресурсов, организация обмена данными на уровне логических номеров параллельных процессов для обеспечения независимости от конфигурации сети, обеспечение возможности проводить асинхронные обмены данными, удаленный запуск процессов и задач, а также обработка ошибочных ситуаций (отказов одного из компьютеров, участвующих в вычислениях или каналов связи с ним).
Решение этих проблем является типичным для подавляющего большинства реализаций распределенных задач. Это делает целесообразным создание программной среды, которая взяла бы на себя решение перечисленных выше проблем и обеспечивала бы многозадачный режим работы с разделением времени.
Вариантом такой среды является параллельная мультикомпьютерная сеть (ПМК-сеть), которая представляет собой множество неспециализированных компьютеров (в дальнейшем именуемых вычислителями), соединенных между собой каналами связи, и специализированного программного обеспечения, которое и выполняет поставленные перед ПМК-сетью задачи по управлению распределенными вычислениями [1 – 3]. Особенностью ПМК-сети является необходимость регулярного отслеживания затрат времени на передачу данных между компьютерами, входящими в сеть, и учет их неравнозначности с точки зрения этих затрат на этапе распределения параллельных задач по компьютерам.
Программное обеспечение ПМК-сети состоит из нескольких компонент: координирующего процесса, локального диспетчера, клиентской библиотеки и средств мониторинга.
Схема архитектуры ПМК-сети (без средств мониторинга) представлена на рис. 1.
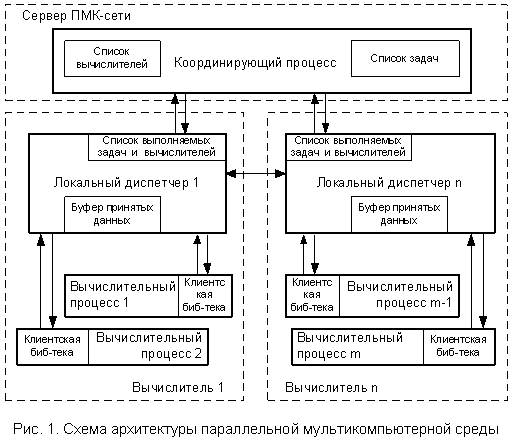
Задачи координирующего процесса – это хранение информации о доступных вычислительных ресурсах, списка всех выполняемых задач, распределение задач по вычислителям и сбор информации о ходе выполнения вычислительных процессов для отладки и мониторинга. В решении самих вычислительных задач координирующий процесс не участвует.
Локальный диспетчер запускается на каждом вычислителе и выполняет следующие функции: установку соединения с координирующим процессом и передачу ему информации о доступных вычислительных ресурсах, запуск выполняемых задач по команде, полученной от координирующего процесса, получение от координирующего процесса списка вычислителей для конкретной задачи и установление соединений с этими вычислителями для обменов данными, а также промежуточную буферизацию передаваемых данных.
Задачи клиентской библиотеки – установление соединения с локальным диспетчером, передача ему данных о требованиях запускаемой задачи, осуществление обмена данными с другими параллельными процессами.
Средства мониторинга подключаются к координирующему процессу ПМК-сети и получают от него информацию, необходимую для мониторинга состояния ПМК-сети в целом и мониторинга выполнения отдельных задач.
Важно отметить, что логическая организация вычислительных процессов внутри задачи не связана напрямую с архитектурой территориально-распределенной сети и может определяться разработчиком прикладной задачи произвольно.
Однако в ряде случаев возможны ситуации, когда распределенные вычисления оказываются неприменимыми из-за того, что производительность отдельного вычислителя оказывается недостаточной, а дальнейшее распараллеливание на ПМК-сети неэффективно из-за большого количества обменов данными. В то же время возврат к классическому централизованному варианту оказывается также малоэффективным вследствие необходимости передавать большой объем данных от источников данных на центральный компьютер. В этих случаях эффективным решением является комбинированный подход: использование кластеров в качестве узлов ПМК-сети.
Можно выделить несколько вариантов реализации такого комбинированного подхода:
а) интегрированный. На каждый узел кластера устанавливается локальный диспетчер ПМК-сети, после чего каждый узел становится обычным вычислителем. Это самый простой вариант по реализации, однако на практике он применим лишь в том случае, когда кластер участвует в вычислении только тех же задач, что и ПМК-сеть, и имеется возможность установки на него произвольного программного обеспечения. Кроме того, при таком подходе производительность кластера оказывается несколько более низкой из-за того, что его узлы вынуждены работать в многозадачном режиме с разделением времени (что обычно в кластерных системах не применяется), и из-за промежуточной буферизации данных в локальном диспетчере.
б) статический. Для интеграции кластера с ПМК-сетью используется отдельный компьютер (или управляющий компьютер кластера, если есть такая возможность), на который устанавливается специализированная версия локального диспетчера, которая отображает кластер как один виртуальный вычислитель с достаточно высокой производительностью. Далее на данном виртуальном вычислителе запускаются процессы-посредники, с которыми другие параллельные процессы решаемых задач взаимодействуют так же, как если бы это были обычные вычислительные процессы ПМК-сети. Назначение такого процесса-посредника состоит в следующем: 1) ожидание прихода всех необходимых данных, 2) их передача кластеру (средства для взаимодействия с кластером могут предоставляться клиентской библиотекой ПМК-сети), 3) запуск подзадачи обработки этих данных на кластере, 4) ожидание завершения задачи, 5) получение результатов с кластера и их рассылка другим вычислителям ПМК-сети. Этот вариант более сложен в реализации и требует специальных действий с точки зрения разработчиков прикладной задачи – написания процесса-посредника, однако он применим практически в любых ситуациях. Недостатком этого варианта является необходимость ожидания всех используемых в процессе решения подзадачи данных.
в) динамический. Подход во многом аналогичен статическому, однако специализированный локальный диспетчер обязательно должен выполняться на управляющем узле кластера. При этом процессы-посредники разрабатываются с использованием как клиентской библиотеки ПМК-сети, так и интерфейса взаимодействия узлов кластера (например, MPI), в результате чего они могут напрямую взаимодействовать как с другими процессами задачи, выполняемыми на ПМК-сети, так и с узами кластера. Этот вариант реализации – самый сложный с точки зрения разработчика, однако он снимает те ограничения, которые накладывались статическим вариантом, в итоге данные и результаты могут передаваться с ПМК-сети на кластер и обратно по мере готовности с минимальными задержками.
Таким образом, вышеописанные варианты позволяют объединить вычислительные ресурсы распределенной среды и кластера, что дает возможность использовать как преимущества распределенных вычислений, так выигрыш в эффективности за счет мелкоблочного распараллеливания на кластере. В настоящее время на кафедре ВМСиС ведется разработка ПМК-сети, в которой будет возможна реализация такой интеграции.
ЛИТЕРАТУРА
1. Дзегеленок И.И., Ильин П.Е. и др. Декомпозиционный подход к осуществлению GRID-технологий// Научно-технический журнал «Информационная математика». – М.: Изд-во «АСТ-Физико-математическая литература», № 1(5), 2005. – С. 110-119.
2. Дзегеленок
И.И., Ильин П.Е. Проект глобально-распределенной мультикомпьютерной среды для
реализации декомпозиционных моделей управления. Труды III Международной
конференции «Параллельные вычисления и задачи управления» PACO'2006 памяти И.В.
Прангишвили. Москва, 2 –4 октября
3. Ильин П.Е.
Стратегия распределения параллельных процессов в глобально-распределенной
мультикомпьютерной среде с учетом многозадачности. Труды III Международной
конференции «Параллельные вычисления и задачи управления» PACO'2006 памяти И.В.
Прангишвили. Москва, 2 – 4 октября