BC/NW 2008, №2 (13): 12.5
ОБНАРУЖЕНИЕ НАЧАЛА И КОНЦА СЛОВ И ПАУЗ НА
ИЗОЛИРОВАННЫХ СЛОВАХ И В СЛОВОСОЧЕТАНИЯХ ВЬЕТНАМСКОГО ЯЗЫКА
Евсеев А.И., Нгуен Ван Хунг
(Москва, Московский энергетический
институт(технический университет), Россия)
Введение
В настоящее время научное сообщество вкладывает
гигантское количество денег в развитие ноу-хау и научно-исследовательские
разработки для решения проблем автоматического распознавания и понимания речи.
Для того чтобы выполнит задачу распознавания речи, в первую очередь, необходимо
определить моменты начала и окончания входного слова и пауз внутри него.
Процедура обнаружения моментов начала и окончания фразы существенно уменьшает
число арифметических операций, если обрабатывать только те сегменты, в которых
имеется речевой сигнал. Вследствие этого скорость обработки будет
увеличиваться.
Проблема определения начала и окончания речи очень
сложна из-за существования окружающего шума. Даже в случае высококачественной
записи, выполненной в заглушенной камере или звуконепроницаемой комнате, электрический
шум в электронных приборах исключить невозможно. Шум представляет чрезвычайную
трудность при распознавании. Часто бывают случаи, в которых очень трудно
разделить сигнал и шум в начале или конце речи. Можно сказать, что задача
отделения речи в значительной степени заключается в
преодолении проблемы шума.
В этой статье рассмотрен алгоритм определения начала и
окончания речевых команд и пауз внутри них. Для определения момента начала
команды определяется порог фонового шума и пороги, вероятность преодолеть
которые за счёт только шума мала. Определение момента окончания команды
определяется из условия, что динамический диапазон речи обычно не превышает 30
Дб.
Алгоритм определения крайних точек слова
Речь записывается с частотой дискретизации 11025 Гц, и
разрядностью квантования равной 16 битам, типа моно. Входной сигнал запишем как
последовательность отсчётов si.
![]() где ( i = 1, 2, . . .)
где ( i = 1, 2, . . .)
Речевой сигнал разобьём на фреймы (окна) по 256
отсчетов без перекрытия. Тогда речь можно представить в следующем виде:
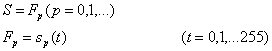
Сначала определим, в каких фреймах содержатся моменты
начала и окончания входного слова. Далее, путём анализа перепадов амплитуд
сигнала будут уточнены граничные точки. В этом случае, погрешности в вычислении
начала и конца речевого участка составили 3 ¸ 6 миллисекунд.
1. Определение точки начала слова
Допустим, что в интервале 250мс с момента включения
микрофона имеется только шум (на практике такое допущение обычно выполняется),
тогда можно определить характеристики шумов. Используем 10 первых фреймов.
Проведём для них быстрое преобразование Фурье (БПФ) [1]:
![]()
Из-за симметрии рассмотрим ![]() , где i = 0,1,…,127.
, где i = 0,1,…,127.
Далее, считаем арифметическое среднее значение [2]:

Значение средне квадратичного отклонения считаем по
формуле:
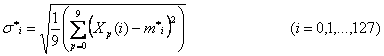
Порог для фона шумов считаем по формуле:
![]()
где ![]() ,
, ![]() .
.
Получим
128 значений порогов шума. Если 15 порогов превышены, то считаем, что в этом
фрейме происходит начало слова, т.к. превышение 7 порогов соответствует 5%
выполняемости этого события ( 0.05 x 127 » 7 ) только
за счёт шума. Если учесть, что минимум ширины спектра умеет место у звука «ы» (около
6 отсчётов), то чтобы увеличить надежность определения начала слова потребуем
превышения 15 порогов не менее чем у двух фреймов подряд. Эксперимент показал,
что все начала слов хорошо определяются для выбранных команд (словосочетаний).
Таким образом, найдём фрейм начала слова с точностью в
23 мс ![]() . Далее, в этом фрейме определим более точно место начала
слова.
. Далее, в этом фрейме определим более точно место начала
слова.
Разобьём его на 8 интервалов, в каждом из них
содержится 32 отсчёта, что соответствует интервалу в 2,90249 » 3 мс. 2560 начальных отсчётов шума (s0, s1 … s2559)
разделим на 80 интервалов для вычисления модуля средней амплитуды шума:

где ![]() ,
, ![]() .
.
Затем сравним среднее значение модуля отсчётов каждого
интервала sN*
во фрейме начинающим слово с порогом ÕN. Если значение sN*
этого и следующего интервала выше чем порог ÕN, то считаем, что в этом интервале происходит начало
слова.
Рисунок 1 иллюстрирует блок-схему алгоритма
определения начала слова.
Алгоритм
уточнения интервала, в котором происходит начало слова, представлен на рисунке
2.
2-
Определение точки окончания слова или начала паузы внутри слова
Определим наибольшее значение спектральной
составляющей для всех фреймов после фрейма, соответствующего началу слова.
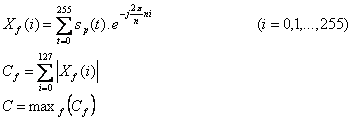
Если
![]() а
а ![]() и
и ![]() , то это соответствует фрейму, соответствующему моменту
окончания слова или начала паузы в нём.
, то это соответствует фрейму, соответствующему моменту
окончания слова или начала паузы в нём.
Рисунок 3 иллюстрирует блок-схему алгоритма для
определения окончания слова или начала паузы внутри слова.
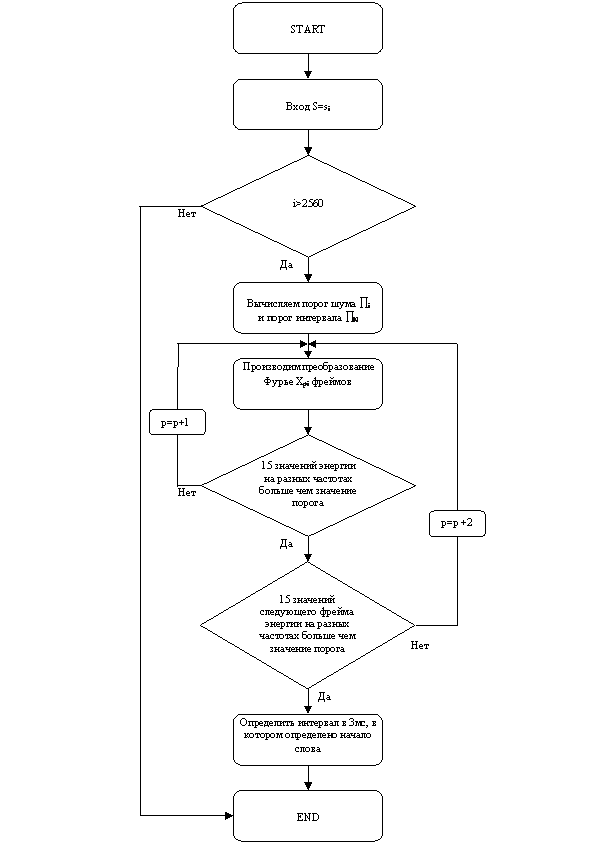
Рисунок 1
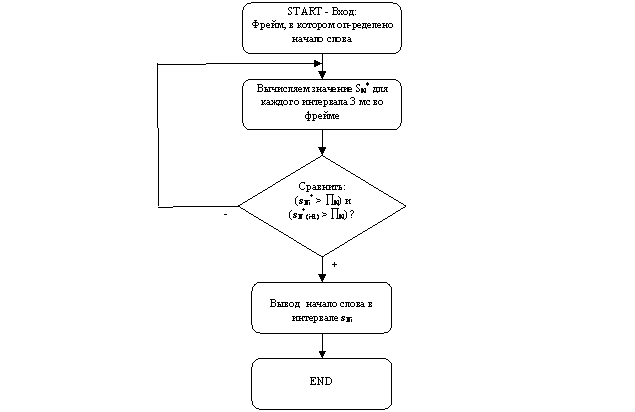
Рисунок 2
Результаты
экспериментов
На основе принципов и подходов, описанных выше,
следующий рисунок представляет пример, в котором определены моменты начала и
окончания входного вьетнамского словосочетания “Bắt đầu” (Начать). На рисунке 4, Н1, Н2 – это точки начала
слов, а К1, К2 – точки начала пауз. Рисунки отображают реальные сигналы в
пропорции 1 : 8 ( 8 отсчётов ~ 1 пиксел).
Следующий рисунок 5 представляет пример, в котором
определены моменты начала и окончания входного вьетнамского словосочетания “Kết thúc” (Кончить).
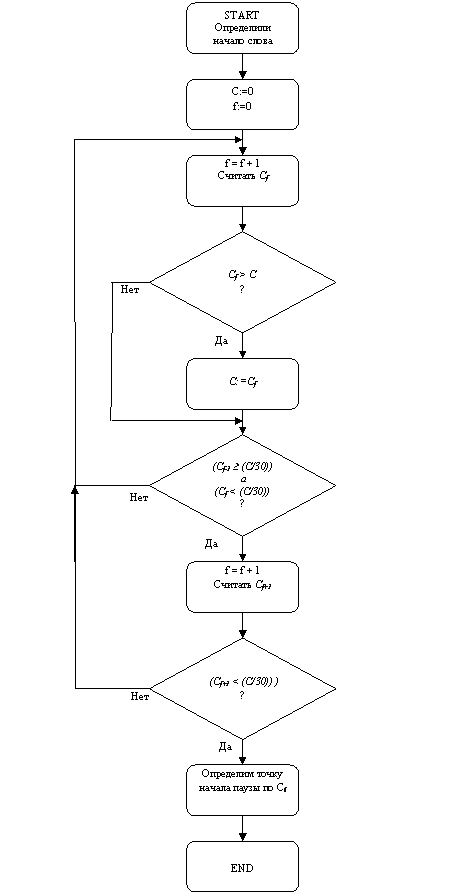
Рисунок 3

Рисунок 4

Рисунок 5
Начало слов и пауз и окончание слов в 74 словах
(словосочетаниях) вьетнамской речи от трёх дикторов определены с точностью до 3
¸ 6 мс по началу
слова и 23 мс по окончании слов и началу пауз. Дальнейшие исследования могут
быть направлены на определение работоспособности метода при уменьшении
соотношения сигнал – шум и на других дикторах. В экспериментах это соотношение
составляло 40 - 50 Дб.
ЛИТЕРАТУРА
1.
Теория применение
цифровой обработки сигналов, Л. Рабинер, Б. Гоулд, 394 - 483. Перевод с
английского А. Л. Зайцева, Э. Г. Назаренко, Н. Н. Тетёкина. Изд. «Мир», Москва
1978.
2. Теория вероятностей и её инженерные приложения. Е.С. Вентцель, Л.А. Овчаров. -г-е изд. стереомип. Москва, Выстая школа, 2000.