BC/NW 2008, №2 (13): 4.1
ТЕХНОЛОГИИ СОГЛАСОВАННОГО ВЫДЕЛЕНИЯ
РЕСУРСОВ И
ПЛАНИРОВАНИЯ ВЫЧИСЛЕНИЙ
В
РАСПРЕДЕЛЕННЫХ СРЕДАХ
Топорков В.В.
(Москва, Московский энергетический институт (ТУ), Россия)
Работа выполнена при финансовой поддержке РФФИ (проект № 06-01-00027).
Введение. Основные проблемы организации вычислений в распределенных средах обусловлены разнородностью состава ресурсов и большим количеством событий, связанных с их доступностью [1]. Это заставляет использовать методы прогнозирования освобождения и занятия ресурсов, предварительного резервирования [2, 3] и опережающего планирования.
В настоящей работе рассматривается подход к формированию различных типов стратегий коаллокаций (согласованного выделения ресурсов) с учетом структуры задания, разнотипности и сложности составляющих его задач, а также особенностей политики репликации и хранения данных в распределенной неоднородной среде с динамично изменяющимся составом вычислительных узлов [3-5]. В качестве базовой концепции выбрана схема «метапланировщик – локальные системы пакетной обработки», в наибольшей степени отражающая коллективный характер использования распределенных ресурсов в рамках виртуальных организаций.
Можно выделить два различных подхода к организации решения больших задач в распределенных средах. Один из них рассчитан на использование доступных распределенных неоднородных ресурсов, когда не предполагается наличия какого-либо регламента в их предоставлении. Пример реализации – система X-Com (НИВЦ МГУ, http://X-Com.parallel.ru) [6]. Другой подход ориентирован на Грид-системы и образование виртуальных организаций, в рамках которых устанавливаются определенные правила предоставления и использования ресурсов [7]. Чаще всего и в том, и другом подходах информационная структура задания и неоднородность составляющих его задач не принимаются во внимание. Так, в X-Com модель вычислений строится в рамках парадигмы Master/Slaves, когда процессы-рабочие обмениваются данными лишь с процессом-мастером. Что касается Грид-систем, то ряд современных программных платформ позволяет работать со структурированными заданиями. Так, система управления заданиями WLMS в составе комплекса gLite (http://www.glite.org) оперирует с заданиями разных типов: простыми и составными. Модель составного задания – ориентированный бесконтурный граф (DAG), вершины которого соответствуют отдельным заданиям, а дуги – связям между ними. При этом, однако, не оговаривается ни сложность, ни разнотипность составляющих заданий по требуемым вычислительным ресурсам. В проблеме коаллокации неоднородных распределенных ресурсов для сложно структурированных заданий учет этих аспектов важен.
В данной работе предложены и исследованы три типа стратегий коаллокаций для выполнения составных заданий на основе имитационной модели метапланировщика [8]:
– с высокой степенью распределенности вычислений в сочетании с политикой активной репликации данных;
– с высокой степенью распределенности вычислений при удаленном доступе к данным (отсутствием динамичной репликации);
– с крупноблочным разбиением заданий и статичным хранением данных на удаленных узлах.
Изучено влияние стратегий коаллокаций на показатели качества обслуживания:
– среднюю загрузку и «цену» использования неоднородных процессорных узлов;
– время выполнения неодинаковых по вычислительной сложности задач;
– время «жизни» стратегии в условиях динамично изменяющегося состава вычислительной среды;
– отклонение запрашиваемого времени запуска задания (при предварительном резервировании) от фактического времени доступа к ресурсам.
Подбор базового состава ресурсов и распределение задания на число узлов не более десятка в рассматриваемом подходе реализуются жадными алгоритмами [9] за время, несоизмеримо меньшее затрат на планирование в известных подходах [10, 11]. Использование заранее подготовленной стратегии делает затраты на планирование значительно менее трудоемкими в сравнении с построением расписаний алгоритмами имитации отжига [10] и GDA [11]. Методы формирования иерархических стратегий предложены и описаны в работах [12-14].
Имитационное моделирование стратегий коаллокаций. Имитационная модель (рис. 1) позволяет формировать поток заданий от пользователей.
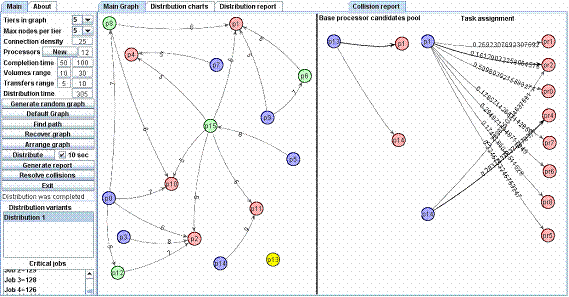
Рис. 1. К функциональным
возможностям метапланировщика
Исследованы показатели эффективности трех типов стратегий коаллокаций:
– S1 – с высокой степенью распределенности вычислений, активной репликацией и перемещением данных в узлы, где они необходимы для дальнейших вычислений;
– S2 – с высокой степенью распределенности вычислений, удаленным доступом к данным, отсутствием активной репликации;
– S3 – с крупноблочным разбиением задания, статичным хранением данных на удаленных узлах.
При построении стратегии S1 для каждой из задач бралась наихудшая и наилучшая из возможных оценок времени исполнения (на самом «медленном» и самом производительном узлах), для стратегий S2, S3 планы формировались во всем диапазоне оценок для отобранных базовых узлов. Число узлов в распределенной среде – 20...30. Базовые процессорные узлы, отбираемые метапланировщиком, разделялись на четыре типа N1, ... , N4 по производительности: относительная производительность узла N1 – 1, узлов N2, N3 и N4 – соответственно 0.5, 0.33 и 0.25. Исследовано более 3000 заданий с различной степенью информационной связности задач. Время решения задач и соответствующие относительные объемы вычислений различались в 2...3 раза. При формировании стратегий с укрупнением задач обработки соответствующие оценки параметров задач исходной модели задания суммировались. При моделировании очереди локальной системы пакетной обработки заданий принималась дисциплина обслуживания в порядке поступления (FCFS).
Результаты сравнительного анализа показателей качества стратегий S1, S2 и S3 приведены на рис. 2.
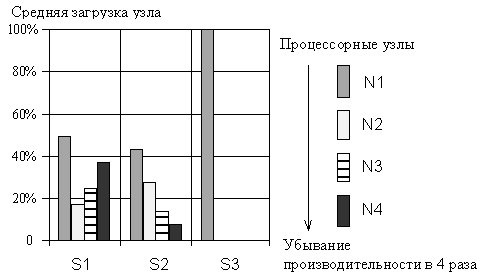
а
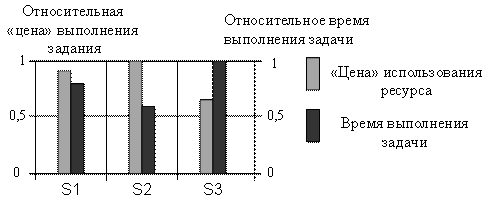
б
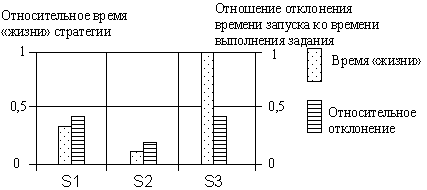
Рис. 2. Сравнение стратегий по показателям качества обслуживания
Стратегия S1 (с активным перемещением данных в среде) обеспечивает в целом сбалансированную загрузку процессорных узлов различной производительности (см. рис. 2, а), в то время как в стратегиях S2, S3 с удаленным доступом к данным имеется явный перекос в сторону загрузки наиболее производительных узлов из-за заметных задержек передачи данных. Особенно характерно это проявляется в стратегии S3 с крупноблочным разбиением задач. Подобные стратегии практически во всех случаях пытаются «захватить» самые производительные узлы, не загружая более медленные, с тем чтобы избежать временных потерь, связанных с удаленным доступом к данным.
При этом стратегии типа S3 оказываются и самыми «медленными» (см. рис. 2, б): время выполнения задачи в S3 с крупноблочным разбиением задания в 1.25…1.7 раза больше чем в стратегиях S1, S2 с высокой степенью распределенности вычислений. Меньшее время решения задач в S2 по сравнению с S1 объясняется тем, что планы в S1 строятся на наихудших и наилучших оценках времени выполнения задач, а в S2 – на оценках во всем спектре отобранных базовых узлов. В этом смысле планы в S2 являются более точными, а сама стратегия S2 – более полной по отношению к S1, поскольку охватывает больше вариантов возможных ситуаций с состоянием загрузки узлов. Однако формирование подобных стратегий может быть весьма трудоемким и неоправданным при инструментальной реализации метапланировщика, поскольку необходимо учитывать затраты времени на планирование, отбор опорных планов, а также динамично изменяющиеся состояния узлов.
На рис. 2, б приведены также диаграммы относительной «цены» стратегий. «Цена» измеряется как сумма отношений объемов вычислений ко времени фактической загрузки узла задачей. Как видно из диаграммы на рис. 2, б, самой «дешевой» оказывается самая «медленная» стратегия S3, а затраты на S1, S2 соизмеримы.
В экспериментах оценивался и такой показатель как среднее время «жизни» стратегии, т.е. тот интервал времени, на котором планы вычислений остаются актуальными (приемлемыми) с учетом динамики загрузки ресурса и отклонений фактического времени запуска задачи от запрашиваемого метапланировщиком (рис. 2, в).
Результаты экспериментов показывают, что наиболее «живучими» являются самые «медленные» стратегии S3, а наименее устойчивы к динамике изменений – полные и «быстрые» стратегии типа S2. Это вполне объяснимо. Стратегии S3 всегда пытаются монопольно захватить самый производительный ресурс, минимизировать затраты на обмен данными, что, кстати, и обуславливает большее, чем в более точной стратегии S2, отклонение времени старта задания от фактического предоставления ресурса (см. рис. 2, а и в). Более полный спектр оценок ожидаемого времени выполнения задач в S2, с одной стороны, позволяет учесть большее число возможных событий, связанных с загрузкой ресурсов, а с другой, делает их наиболее уязвимыми с позиций «живучести».
Сравнительный анализ трех типов стратегий позволяет заключить, что предпочтительными, в том числе, и с позиций инструментальной реализации, являются стратегии типа S1, поддерживающие политику репликации и активного перемещения данных в среде. Они обеспечивают сбалансированную загрузку процессорного ресурса, занимают промежуточное положение по «цене», времени выполнения задач, временной устойчивости между «быстрыми» и «дорогими» (S2) и «медленными», но «дешевыми» (S3) типами стратегий. Однако в условиях ограниченности доступного процессорного ресурса предпочтительнее оказываются стратегии S3, а активная динамика изменения состава узлов приводит к необходимости формирования полных и более точных стратегий типа S2, ориентированных на больший охват возможных событий в распределенной среде.
Проблемы блокировок вычислений. Сложные информационные взаимосвязи между задачами, различные размеры блоков данных, формируемых и запрашиваемых задачами обработки в произвольные моменты времени, могут быть источниками блокировок распределенных вычислений.
На рис. 3, а приведен пример маркированного графа, соответствующего модели задания. Маркировка позиций вершин соответствует числу производимых и потребляемых задачами блоков данных. Когда соответствующие данные формируются в произвольные (случайные) моменты времени, в ситуации, показанной на рис. 3, а, может возникнуть тупик: задачи D, E никогда не смогут стартовать даже после завершения выполнения задач B и C.
Анализу и предотвращению возможных блокировок распределенных вычислений в различных стратегиях планирования посвящена работа [15]. В ней предложены маркированные сети специального вида, адекватно описывающие поведение распределенных программ с буферным обменом сообщениями в MPI. Этот аппарат основан на поиске стационарной и неизбыточной разметки сети и позволяет не только обнаруживать тупики, но и выполнять эквивалентные преобразования графа задания, предотвращающие блокировки вычислений. Так, репликация задач обработки (рис. 3, б) в исходной модели задания исключает возможность тупиков. Стационарная разметка графа задания получается в результате применения алгоритмов квадратичной сложности как функции от числа составляющих задач.
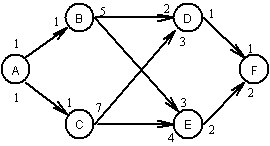
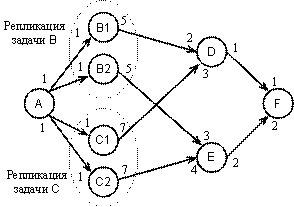
а б
Рис. 3. Структура задания (а), при которой возможны блокировки вычислений; репликация вычислений (б), исключающая возможность блокировок
Заключение. В работе проанализированы показатели качества трех типов стратегий коаллокаций для выполнения составных заданий с различной степенью распределенности вычислений в сочетании с политикой активной репликации данных и отсутствием динамичной репликации.
Предложен подход к исключению тупиков в модели буферного обмена сообщениями, поддерживаемого MPI, на основе репликации (тиражирования) вычислений – задач составного иерархически организованного задания, представленного ацикличным графом.
ЛИТЕРАТУРА
1. Kurowski K., Nabrzyski J., Oleksiak A. et al. Multicriteria aspects of Grid resource management
// Grid Resource Management. State of the Art and Future Trends / Ed. by J. Nabrzyski ,
J.M. Schopf, J. Weglarz. Kluwer Acad. Publ., 2003. P.
271-293.
2.
Ioannidou M.A., Karatza H.D.
Multi-site scheduling with multiple job reservations and forecasting methods //
ISPA 2006 / Ed. by M. Guo et al. Lecture Notes in Computer Science. Springer-Verlag
Berlin Heidelberg, 2006. Vol. 4330. P. 894-903.
3.
Ranganathan K., Foster I. Decoupling computation and data
scheduling in distributed data-intensive applications // Proc. of the 11th IEEE
Int. Symp. on High
Performance Distributed Computing. 2002. http://www.globus.org/research/paper.
4.
William
H.B. et. al. Optor Sim – a Grid simulator for
studying dynamic data replication strategies // Int. J. on HPC Appl. 2003. Vol. 17, No 4. P. 403-416.
5.
Tang
M. et. al. The impact of data
replication on job scheduling performance in the data Grid // Future Generation
Computing Systems. 2006. Vol. 22, No 3. P. 254-268.
6. Воеводин Вл. В. Решение больших задач в распределенных вычислительных средах // АиТ. 2007. № 5. С. 32-45.
7. Коваленко В.Н. Комплексное программное обеспечение Грида вычислительного типа. Препринт № 10. М.: ИПМ им. М.В. Келдыша РАН, 2007. 39 с.
8. Топорков В.В., Целищев А.С., Бобченков А.В., Рычкова П.В. Проект метапланировщика: генерация сценариев распределенной обработки // Научный сервис в сети Интернет: многоядерный компьютерный мир. 15 лет РФФИ: Труды Всероссийской научной конференции (24-29 сентября 2007 г., г. Новороссийск). - М.: Изд-во МГУ им. М.В. Ломоносова, 2007. С. 27-30.
9. Топорков В.В. Потоковые и жадные алгоритмы согласованного выделения ресурсов в распределенных системах // Известия РАН. ТиСУ. 2007. № 2. С. 109-119.
10.
Fidanova S. Simulated annealing for Grid scheduling
problem // IEEE John Vincent Atanasoft Int. Symp. on Modern Computing
(IVA'06). 2006. P. 41-45.
11.
McMullan
P., McCollum B. Dynamic job scheduling on the Grid environment using the Great
Deluge algorithm // Proc. of the 9th Int. Conf. on Parallel Computing
Technologies (PaCT 2007). Lecture Notes in Computer
Science. Springer-Verlag
Berlin Heidelberg, 2007. Vol. 4671. P. 283-292.
12. Топорков В.В. Многоуровневые стратегии согласованного выделения ресурсов в распределенных вычислениях с контрольными сроками // АиТ. 2007. № 12. С. 131-146.
13. Топорков В.В. Управление ресурсами при организации распределенных вычислений на основе опорных планов // Избранные доклады III междунар. конф. «Параллельные вычисления и задачи управления» PACO'2006 памяти И.В. Прангишвили. Москва, 2-4 октября 2006 г. Ин-т проблем управления РАН. М.: ИПУ РАН, 2006. С. 49-58.
14.
Toporkov V. Multicriteria
scheduling strategies in scalable computing systems // Proc. of the 9th Int.
Conf. on Parallel Computing Technologies (PaCT 2007).
Lecture Notes in Computer Science.
15.
Toporkov V.V. Dataflow analysis of distributed programs
using generalized marked nets // Proc. of the 2nd Int. Conf. on Dependability
of Computer Systems (DepCoS-RELCOMEX'07). IEEE CS, 2007. P. 73-80.