BC/NW 2009; №2 (15):3.4
РАЗРАБОТКА КОМПИЛЯТОРА FPTL-ПОДОБНОГО ФУНКЦИОНАЛЬНОГО ЯЗЫКА ПАРАЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ
Нехай И. В.
(ГОУВПО
"Московский энергетический институт (технический университет)",
Россия)
В докладе описаны некоторые аспекты реализации компилятора функционального языка параллельного программирования. Язык программирования аналогичен описанному в [1] языку FPTL. Язык FPTL основан на работах В. П. Кутепова и В. Н. Фалька в области моделей асинхронного вычисления значений функций и разработки функциональных языков программирования.
Кроме языка программирования, в [1] описана разрабатываемая на кафедре прикладной математики МЭИ система функционального параллельного программирования, включающая средства интерпретации программ на языке FPTL.
Система, описанная в данном докладе, имеет ряд сходств с системой [1]:
- Общность свойств функционального языка программирования.
- Вытекающая из неё общность идей реализации.
- Однако, имеется и ряд отличий:
- Более лаконичный синтаксис языка по сравнению с [1]
- Компиляция программы вместо интерпретации
- Меньшая зависимость от программно-аппаратной платформы
Поводом к разработке описанного компилятора послужило желание получить компилятор программ на функциональном языке программирования, обладающий следующими свойствами:
1. Генерация исполняемого exe-файла.
2. Детальные сообщения о синтаксических ошибках компилируемых программ.
3. Возможность настройки компилятора на различные варианты программного и аппаратного окружения, в котором выполняется результирующая программа.
Свойство 1 позволяет использовать разработанный компилятор для профилирования программ стандартными средствами профилирования приложений. Средства профилирования позволяют получать отчёты по количеству вызовов и затратам времени для функций, содержащихся в исполняемом файле.
Подобная статистика для интерпретатора отображает особенности реализации общей модели интерпретатора; установить какое-либо соответствие этой статистики и инструкций интерпретируемой программы затруднительно или невозможно, поскольку имена функций интерпретатора не связаны с инструкциями программы.
В отличие от интерпретатора, компилятор позволяет обеспечить связь имён функций исполняемого файла с именами функций программы на исходном языке, что приводит к получению от средств профилирования программ качественно иных отчётов. Данные отчёты непосредственно отражают статистику работы функций компилируемой программы на функциональном языке.
Свойство 2 приводит к значительному упрощению и ускорению разработки программ. При разработке заданы два основных требования:
1. Сообщения об ошибках должны идентифицировать участок программы, где предполагается наличие синтаксической ошибки, и наиболее вероятную причину ошибки.
2. Обнаружение одной ошибки не должно прекращать процесса поиска ошибок; за один сеанс компиляции необходимо обнаруживать максимально возможное число ошибок.
Выполнение этих требований облегчает работу программиста – пользователя компилятора и уменьшает количество циклов компиляции/исправления ошибок, требуемых для достижения результата.
Свойство 3 позволяет расширить компилятор для генерации программ для различных операционных систем или аппаратных средств, к примеру, видеокарт.
Исходный язык описываемой системы заимствует из FPTL основные семантические объекты – функции и данные – и операции композиции функций. Функции в FPTL рассматриваются как типизированные соответствия между данными. Для построения функций используются следующие четыре операции композиции:
операция последовательной композиции:
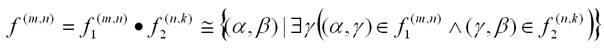
операция конкатенации:
![]()
операция условной композиции:
![]()
операция объединения графиков ортогональных функций:
![]()
Все операции композиции могут быть представлены в качестве фрагментов дерева в виде вершины (содержащей операцию) и двух дочерних вершин.
Определение функции является выражением, содержащим имена функций и параметров, константы и операции композиции. Для каждого определения может быть построено соответствующее ему дерево.
Процесс выполнения программы заключается в развёртывании дерева вычислений и последующем его свертывании. Развёртывание дерева заключается в подстановке дерева, соответствующего определению некоторой функции, вместо вершины дерева, соответствующей вызову этой функции.
Изначально дерево состоит из одной вершины, соответствующей вызову пользовательской функции со специальным именем (result), результат вычисления которой является результатом выполнения программы.
Параллелизм выполнения вычислений связан со свойствами операций композиции. После развёртывания некоторого узла дерева развёртывание и свёртывание (редукция) обоих поддеревьев данного узла может выполняться параллельно. Редукция вершин, соответствующих операциям условной композиции и объединения графиков ортогональных функций, может проводиться раньше, чем проведена редукция всех поддеревьев данных вершин (в общем случае редукция всех поддеревьев не является вычислимой).
В процессе редукции дерева необходимо организовать выбор редуцируемых поддеревьев и параллельную редукцию с использованием нескольких процессов/потоков, выполняемых на различных процессорах. Поскольку развёртывание и редукция проводятся для листовых вершин дерева вычислений, данная задача решается путём построения списка листовых вершин (образующих крону) дерева в порядке обхода дерева.
Вершины, находящиеся в списке, анализируются несколькими процессами, применяющими правила редукции. В многопоточной среде выполнения число элементов списка, разделённое на число исполняемых потоков, определяет расстояние между двумя элементами списка, обрабатываемыми в любой момент времени двумя потоками с последовательными номерами. Для организации доступа к списку и синхронизации используются примитивы синхронизации операционной системы.
Немаловажной частью компилятора, упрощающей работу программиста, является подсистема анализа типов данных функций. Подсистема анализа типов данных функций контролирует соответствие типов в определении и в точках вызова функций, генерируя сообщения об ошибках при обнаружении несоответствия, тем самым обеспечивая дополнительный уровень контроля корректности исходной программы.
Опишем формальные правила анализа типов данных. Пусть f1 – функция типа![]() ,
а f2 – функция
типа
,
а f2 – функция
типа![]() ,
где a, b, c, d – типовые переменные.
,
где a, b, c, d – типовые переменные.
Тогда выполняются следующие соотношения:
![]() если
b и
c – совместимые типы,
иначе ошибка.
если
b и
c – совместимые типы,
иначе ошибка.
![]() если
a и
c – совместимые типы,
иначе ошибка.
если
a и
c – совместимые типы,
иначе ошибка.
![]() если
a и
c – совместимые типы,
иначе ошибка.
если
a и
c – совместимые типы,
иначе ошибка.
![]() если
попарно совместимы типы a и c,
b и
d, иначе ошибка.
если
попарно совместимы типы a и c,
b и
d, иначе ошибка.
Далее, пусть f3
– функция типа![]() ,
а x, y – константы типов
a и
b соответственно.
Тогда:
,
а x, y – константы типов
a и
b соответственно.
Тогда:
![]()
![]()
Из этих определений ясно, что требуется определить понятие совместимых типов. Совместимыми типами будем называть такие типы данных, которые либо совпадают, либо находятся в отношении расширения. Например, совместимыми являются типы целых и натуральных чисел, целых и вещественных чисел и т.п. Согласованием типов будем называть процесс замены двух совместимых типов на менее широкий из них в месте каждого вхождения обоих типов.
Опишем алгоритм анализа типов функций программы.
1. Для
каждой функции по её определению построим её начальный тип, пользуясь
простейшим соотношением для операции конкатенации ![]() и объединения графиков
и объединения графиков ![]() если a и b совместимы. Вместо вхождений функций
подставим ссылки на их типы.
если a и b совместимы. Вместо вхождений функций
подставим ссылки на их типы.
2. Подставим однократно полученные начальные типы функций в места вхождений ссылок на них. Проведём согласование типов аргументов функций и их фактических параметров для операции последовательной композиции. Проведём все возможные оптимизации и согласования для прочих операций.
3. Если в результате 2 остались ссылки на типы каких-либо функций, повторим п. 2., иначе – конец.
В процессе работы приведённого алгоритма возможна ситуация
его «зацикливания» для рекурсивных конструкций, приводящая к построению типов
вида ![]() и более сложных. Такая ситуация должна
отслеживаться и приводить к выдаче сообщения об ошибке. Наиболее простой способ
отслеживания – задание ограничений на максимальное число аргументов функции,
длины цепочки конкатенаций и т.п. и генерация ошибки в случае превышения этих
ограничений.
и более сложных. Такая ситуация должна
отслеживаться и приводить к выдаче сообщения об ошибке. Наиболее простой способ
отслеживания – задание ограничений на максимальное число аргументов функции,
длины цепочки конкатенаций и т.п. и генерация ошибки в случае превышения этих
ограничений.
Реализация компилятора из функционального языка программирования напрямую в машинный код является неоправданно сложной задачей. Кроме того, получаемый в результате исполняемый модуль не будет обладать свойством переносимости. Существует схема, применяемая, к примеру, в компиляторе языка Haskell, Glasgow Haskell Compiler [2], при которой исходная программа преобразуется в её аналог на языке C++, для дальнейшей компиляции которого используются многочисленные промышленные компиляторы C++.
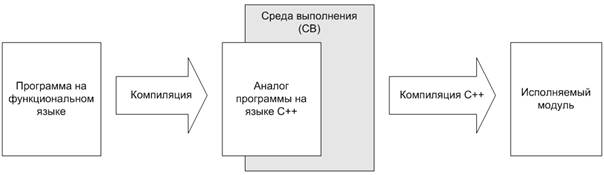
Рисунок 2. Процесс компиляции программы.
Описываемый компилятор построен по аналогичной схеме. Результатом компиляции программы на функциональном языке является модуль на языке C++, содержащий функции развёртывания деревьев в соответствии с правилами, описанными в программе, и моделью выполнения программы, основанной на формальной модели свёртывания и развёртывания деревьев.
Фактически, для каждой функции исходной программы создаётся функция программы на языке C++, заменяющая узел дерева, соответствующий вызову функции, на соответствующее функции поддерево.
Другим компонентом исполняемого модуля является среда выполнения (СВ), также реализованная на языке C++. Среда выполнения содержит реализацию основных алгоритмов выполнения программы: свёртывания деревьев, управления процессом выполнения, распределением задач по вычислительным узлам и т.п. Предполагается разработка нескольких сред выполнения, учитывающих специфику решения служебных задач на конкретных программно-аппаратных платформах – многопоточная реализация для многоядерных процессоров, реализация на основе MPI для кластеров, реализация на основе средств программирования для видеокарт и т.п.
Исходные коды среды выполнения распространяются совместно с компилятором и не модифицируются в процессе компиляции.
На данный момент разработан компилятор и многопоточная среда выполнения для ЭВМ на базе многоядерных процессоров. Дальнейшее развитие разработанной системы возможно путём разработки следующих компонентов:
- Среда выполнения для кластеров.
- Среда выполнения для видеокарт.
- Средства сбора статистики во время выполнения и динамической оптимизации программы.
- Подсистема генерации промежуточного кода на языке C++ на основе подключаемых шаблонов.
Литература
1. С.Е. Бажанов, В.П. Кутепов, Д.А. Шестаков. Язык функционального параллельного программирования и его реализация на кластерных системах. М: Известия РАН, Программирование, 2005, №5, стр. 18-51.
2. http://www.haskell.org/ghc/