BC/NW 2010; №2 (17):10.1
РАСШИРЕНИЕ ЯЗЫКА PASCAL ДЛЯ ПРЕДСТАВЛЕНИЯ
АСИНХРОННЫХ АВТОМАТНЫХ СХЕМ
Калинина Г.А., Кузнецов Д.С., Мороховец Ю.Е.
(Московский энергетический
институт (технический университет), Россия)
В [1] предлагается
модель распределенной обработки данных, основанная на понятии асинхронной
автоматной схемы. В модели предусмотрено графическое представление схем,
которое на практике не всегда удобно. Для текстового представления асинхронных
автоматных схем может быть использован простой, базирующийся на Pascal’е язык, включающий минимальное число семантически очевидных конструкций.
Описание
асинхронной автоматной схемы на предлагаемом языке состоит из двух
взаимосвязанных частей – описания шаблонов автоматных компонентов и собственно
описания схемы.
Описания
шаблонов компонентов определяют функционирование реальных автоматных
компонентов, используемых в схеме. Для достижения наглядности этих описаний в
дополнение к [1] примем соглашение, запрещающее множественное подчинение
процедур обработки данных состояниям компонента.
Группой
состояния s Î S назовем
структуру, включающую состояние s вместе с подчиненными ему процедурами обработки данных. Процедуры,
образующие группу состояния, назовем ветвями обработки данных.
С каждой
группой состояния (или state-группой) свяжем множество управляющих входов, таких,
что ситуации именно на этих входах влияют на выбор ветвей обработки данных в
группе. State-группы, имеющие не пустые множества управляющих
входов, назовем управляемыми state-группами; в противном будем говорить о неуправляемых state-группах.
Неуправляемые state-группы имеют одну единственную ветвь обработки
данных, дискриминант и маска которой не определены.
С
синтаксической точки зрения описание шаблона состоит из заголовка, локальных
описаний и тела шаблона. Общий синтаксис спецификации шаблона компонента имеет
вид:
<шаблон> ::= <заголовок
шаблона><локальные описания><тело шаблона>
<заголовок шаблона> ::= templet<имя
шаблона>
([input<описания
входов>][output<описания
выходов>]);
<тело шаблона> ::= begin<state-группа>{<state-группа>}end;
<state-группа> ::= <управляемая
state-группа>|<неуправляемая
state-группа>
<управляемая state-группа> ::= state<метка состояния>:<when-оператор>{<when-оператор>}
<метка состояния> ::= <pascal-идентификатор>
<when-оператор> ::= when<условие
выбора ветви>
[using<список используемых входов>]do<ветвь обработки данных>
<условие выбора ветви> ::= <операнд>{(and|or|xor)<операнд>}
<операнд> ::= <элементарный
операнд>|<not<элементарный
операнд>
<элементарный операнд> ::= <вызов
функции emp>|<вызов функции nem >|
(<условие выполнения ветви>)
<ветвь обработки данных> ::= <templet-оператор>;{<templet-оператор>;}
<templet-оператор> ::= <next-оператор>|<stop-оператор>|<pascal-оператор>
<next-оператор> ::= next<имя
состояния>
<stop-оператор> ::= stop<имя
состояния>
<неуправляемая state-группа> ::= state<имя состояния>:<ветвь
обработки данных>
Заголовок
шаблона начинается ключевым словом templet, за которым
следует имя шаблона и заключенные в скобки описания его входов и выходов.
Синтаксис описаний входов и выходов аналогичен синтаксису описаний формальных
параметров процедур и функций в базовом языке.
Тело шаблона
представляет собой последовательность state-групп.
Управляемая state-группа состоит из метки состояния, за которой следует
последовательность when-операторов, содержащих альтернативные ветви обработки
данных. Неуправляемая state-группа содержит одну ветвь обработки данных, поэтому
за меткой состояния в ней сразу же следует непустая последовательность
операторов расширенного языка Pascal – templet-операторов.
Метка
состояния состоит из ключевого слова state, за которым следует имя состояния. When-оператор начинается ключевым словом when, за которым следует условие выполнения ветви, определяющее дискриминант и
маску входов (список используемых входов) ветви. За ключевым словом do в when-операторе следует непустая последовательность templet-операторов, образующих ветвь обработки данных. Список используемых в ветви
входов может быть указан явно при помощи using-конструкции.
Условие
выполнения ветви – логическое выражение, включающее в качестве элементарных
операндов вызовы предопределенных булевских функций emp и nem. Значение функции emp(x,…), где x,… – список имен входов, равно true, если буферы ассоциированные с входами x,… пусты, и false – в противном случае. Наоборот, значение функции nem(x,…) равно true, если буферы ассоциированные
с входами x,… не пусты, и false – в
противном случае.
Выполнение
тела шаблона начинается с state-группы непосредственно следующей за ключевым словом begin. Семантика выполнения state-групп
определяется моделью обработки данных, представленной в [1].
Для
иллюстрации введенных обозначений рассмотрим пример шаблона компонента
непрерывного действия, реализующего унарное преобразование, зависящее от двух
параметров c1, c2:
if pi(x1)
then y1:=E(c1,x1)
else y2:=E(c2,x1), (1)
где pi – логическая функция, а E – функция,
при вычислении которой, в зависимости от значения pi(x1), применяется либо параметр c1, либо параметр c2.
Шаблон имеет
пять входов X = {x1, x2, x3, x4, x5} и два выхода
Y = {y1, y2}; все входы и выходы – вещественного типа.
Работа
реальных компонентов, отвечающих шаблону, заключается в приеме блоков данных из
буфера на входе x1, их
преобразовании и выдаче результатов в буферы на выходах y1 или y2; а также в приеме блоков данных из буферов на входах x2 и x3, x4 и x5, обеспечивающих вычисление параметров c1, c2, соответственно. Значения параметров преобразования хранятся во внутренней
памяти компонента. Начальные и все последующие значения параметров c1, c2 вычисляются
операторами
c1:= E1(x2,x3), c2:= E2(x4,x5), (2)
где E1 и E2 – заданные функции. Выполнение операторов (2) обусловливается наличием
блоков данных одновременно в буферах на входах x2 и x3, x4 и x5, причем частота поступления данных в эти буферы значительно меньше частоты
поступления блоков данных в буфер на входе x1. Сложность вычисления функций E1 и E2 превосходит сложность вычисления функции E.
В начале
работы вычисляются значения параметров c1, c2, и только затем компонент переходит в основной режим, в котором периодически, при поступлении данных в буфер
на входе x1, выполняется
преобразование (1), и
осуществляется пересчет значений параметров c1, c2 (2) , при поступлении блоков данных в буферы на соответствующих входах.
Вход x1 имеет самый низкий приоритет. Блоки данных принимаются через него лишь
тогда, когда отсутствуют данные на входах x2 и x3 или x4 и x5. Взаимный приоритет пар входов x2 и x3, x4 и x5 не
фиксирован – их приоритеты меняются таким образом, что обслуженной паре входов
назначается более низкий приоритет.
Диаграмма
переходов для рассматриваемого случая показана на рис. 1.
Начальное
состояние внутренней памяти компонента характеризуется следующими значениями
переменных: c1 = c2 = 0; g = false, где g – вспомогательная переменная логического типа.
Дискриминанты
и алгоритмы выполнения ветвей обработки данных для состояний, изображенных на
рис. 1, имеют следующий вид.
Состояние s0:
D01 = D(s0,f1) =
{01100,01101,01110,11100,11101,11110};
ветвь f 01: {j01 =
01100} c1 := E1(x2,x3); g
:= true; next(s0);
D02 = D(s0,f2) =
{00011,00111,01011,01111,10011,10111,11011,11111};
ветвь f 02: {j02 =
00011} c2 := E2(x4,x5); if not(g) then next(s1) else next(s3);
Состояние s1:
D11 = D(s1,f1) =
{00011,00111,01011,10011,10111,11011};
ветвь f 11: {j11 =
00011} c2 := E2(x4,x5); next(s1);
D12 = D(s1,f2) =
{01100,01101,01110,01111,11100,11101,11110,11111};
ветвь f 12: {j12 =
01100} c1 := E1(x2,x3); next(s2);
Состояние s2:
D21 =D (s2,f1) =
{10000,10001,10010,10100,10101,10110,11000,11001,11010};
ветвь f 21:
{j21 = 10000} if pi(x1) then y1:=E(c1,x1) else y2:=E(c2,x1); next(s2);
D22 = D(s2,f2) = D01 = {01100,01101,01110,11100,11101,11110};
ветвь f 22:
{j22 = 01100} c1 :=
E1(x2,x3); next(s2);
D23 = D(s2,f3) = D02 =
{00011,00111,01011,01111,10011,10111,11011,11111};
ветвь f 23:
{j23 = 00011} c2 := E2(x4,x5); next(s3);
Состояние s3:
D31 = D(s3,f1) =
{10000,10001,10010,10100,10101,10110,11000,11001,11010};
ветвь f 31:
{j31 = 10000} if pi(x1) then y1:=E(c1,x1) else y2:=E(c2,x1); next(s3);
D32 = D(s3,f2) = D11 = {00011,00111,01011,10011,10111,11011};
ветвь f 32:
{j32 = 00011} c2 :=
E2(x4,x5); next(s3);
D33 = D(s3,f3) = D12 =
{01100,01101,01110,01111,11100,11101,11110,11111};
ветвь f 33:
{j33 = 01100} c1 := E1(x2,x3); next(s2).
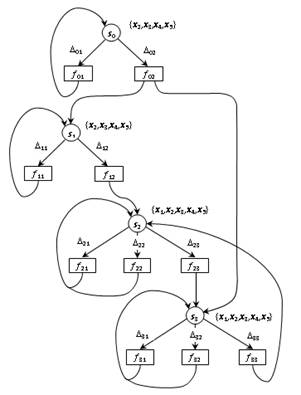
Рис. 1. Диаграмма переходов автоматного
компонента
Сечение области
определения функции q, соответствующее
состоянию s3, показано на рис. 2.
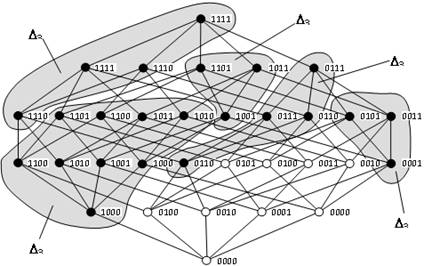
Рис. 2. Сечение области
определения функции выбора ветви
Здесь изображена
плоская проекция 5-мерного куба, являющаяся графическим представлением частично
упорядоченного множества á{0,1}5, £ñ [2]. Вершины куба соответствуют значениям
вектора ситуации на входах X. Темными точками изображены рабочие ситуации, для которых функция выбора
ветвей q определена. Множества D31, D32, D33 – дискриминанты ветвей f31, f32, f33, подчиненных состоянию s3, представлены на рис.
2 в виде затемненных областей.
Описание шаблона
рассмотренного автоматного компонента имеет вид:
templet sigma(input x1,x2,x3,x4,x5:real
output y1,y2:real);
var
{инициализация памяти компонента}
c1,c2:real=0;
g:boolean=false;
function E(par1,par2:real):real;
{описание функции E}
. . .
function E1(par1,par2:real):real;
{описание функции E1}
. . .
function E2(par1,par2:real):real;
{описание функции E2}
. . .
function pi(par:real):boolean; {описание функции pi}
. . .
begin
{начало тела шаблона}
state s0: {управляемая state-группа s0}
when nem(x2,x3)and(emp(x4)or emp(x5))using x2,x3 do {ветвь f01}
c1:=E1(x2,x3);
g:=true;
next s0;
when nem(x4,x5) do {ветвь f02}
c2:=E2(x4,x5);
if not g then next s1 else next s3;
state s1: {управляемая state-группа s1}
when nem(x4,x5)and(emp(x2)or emp(x3))using x4,x5 do
{ветвь f11}
c2:=E2(x4,x5);
next s1;
when nem(x2,x3) do {ветвь f12}
c1:=E1(x2,x3);
next s2;
state s2: {управляемая state-группа s2}
when
nem(x1)and(emp(x2)or emp(x3))and(emp(x4)or emp(x5))
using x1 do {ветвь f21}
if pi(x1) then
y1:=E(c1,x1); {подключение выхода y1}
else
y2:=E(c2,x1); {подключение выхода y2}
next s2;
when nem(x2,x3)and(emp(x4)or emp(x5))using x2,x3 do {ветвь f22}
c1:=E1(x2,x3);
next s2;
when nem(x4,x5) do {ветвь f23}
c2:=E2(x4,x5);
next s3;
state s3: {управляемая state-группа s3}
when
nem(x1)and(emp(x2)or emp(x3))and(emp(x4)or emp(x5))
using x1 do {ветвь f31}
if pi(x1) then
y1:=E(c1,x1); {подключение выхода y1}
else
y2:=E(c2,x1); {подключение выхода y2}
next s3;
when nem(x4,x5)and(emp(x2)or emp(x3))using x4,x5 do {ветвь f32}
c2:=E2(x4,x5);
next s3;
when nem(x2,x3) do {ветвь f33}
c1:=E1(x2,x3);
next s2;
end; {templet sigma} {конец тела шаблона}
Следует отметить, что
опциональная using-конструкция использовалась в ветвях, имеющих
сложные условия выбора, когда трудно понять какие входы компонента могут быть
использованы в алгоритме ветви.
С
синтаксической точки зрения описание асинхронной автоматной схемы состоит из
заголовка, глобальных описаний, описаний шаблонов, буферов и компонентов.
Описания буферов и компонентов, по сути дела, определяют структуру схемы.
Общий
синтаксис схемы имеет вид:
<схема> :: = <заголовок
схемы><глобальные описания> <описания
шаблонов>
[<описания
буферов>]<описания компонентов>end
<заголовок схемы> ::= scheme<имя
схемы>
<описания шаблонов> ::= <шаблон>{<шаблон>}
<описания буферов> ::= buf
<буферы>{<буферы>}
<буферы> ::= <имя
буфера>{,<имя буфера>}: <тип>[<размер>];
<описания компонентов> ::= comp
<компонент>{<компонент>}
<компонент> ::= <имя компонента>:<имя шаблона>([in <список входных буферов>]
[out
<список выходных буферов>]);
<список входных буферов> ::= <список
буферов>
<список выходных буферов> ::= <список
буферов>
<список буферов> ::= <имя
буфера>{,<имя буфера>}
Заголовок
схемы начинается ключевым словом scheme, за которым
следует имя схемы.
Глобальные
описания – это принятые в базовом языке Pascal описания
констант, типов, переменных, процедур и функций, используемых в шаблонах
компонентов.
Описания
буферов схемы, если они есть, начинаются ключевым словом buf. Элемент описания содержит список имен буферов, за
которым следует их тип и размер.
Описания
компонентов схемы начинаются ключевым словом comp. Описание компонента содержит его собственное имя и имя шаблона, в
соответствии с которым он построен и функционирует. Вслед за именем шаблона в
круглых скобках перечисляются входные и выходные буферы компонента, если они
есть. При перечислении входных и выходных буферов должно быть обеспечено их
соответствие входам и выходам, указанным ранее в описании шаблона компонента.
В качестве
примера приведем описание схемы, приведенной в работе [1] на рис. 3.
Спецификация имеет вид:
scheme example;
const {глобальные
описания}
n = 8;
type
arr = array[1..n]of real;
dataBlock = record
m:integer;
a:arr;
end;
templet sigma1(output y1,y2:real);
{описания шаблонов}
. . .
templet sigma2(input x1,x2:real;x3,x4:dataBlock output y1:arr);
. . .
templet sigma3(input x1,x2:real;x3:arr output
y1,y2:arr);
. . .
templet sigma4(input x1:arr output y1:dataBlock);
. . .
buf {описания буферов}
b1,b2,b3,b4:real[4];
b5,b6,b7:arr[1];
b8,b9:dataBlock[2];
comp {описания компонентов}
p1:sigma1(output b1,b3);
p2:sigma1(output b2,b4);
p3:sigma2(input b1,b2,b8,b9 output b5);
p4:sigma3(input b3,b4,b5 output b6,b7);
p5:sigma4(input b6 output b8);
p6:sigma4(input b7 output b9);
end
{конец
схемы example}
Приведенные
в настоящем докладе синтаксические расширения сделаны для базового языка Pascal. Однако, эти расширения могут быть выполнены для любых других
алгоритмических языков высокого уровня, например для языков С# или Fortran.
ЛИТЕРАТУРА
1. Калинина Г.А., Мороховец Ю.Е. Модель асинхронной автоматной обработки данных // Вестник МЭИ. 2008. № 5. С. 57-61.
1. Фролов А.Б., Андреев А.Е., Болотов А.А., Коляда К.В. Прикладные задачи дискретной математики и сложность алгоритмов. М.: Издательство МЭИ, 1997. – 312 с.