BC/NW
2011; №1 (18):3.2
Определение возможности автоматического извлечения табличных данных из html-страниц.
В.В. Роман, И.И. Дзегеленок,
Московский энергетический институт (Технический
университет)
В настоящее время все большую актуальность обретает
проблема извлечения информации из html-страниц
в рамках получающей все большее признание технологии Web Mining [1]. В
общем случае эта проблема неразрешима. Однако при определенных ограничениях
можно приблизиться к ее решению. Так, для многочисленных инженерных приложений
интерес представляют табличные данные, вытекающие из рассмотрения упрощенной
модели предметной области. Определению этой возможности и посвящена данная
работа.
В настоящее время существуют лишь общие подходы к
извлечению данных. Среди них: 1.) анализ DOM-деревьев; 2.) использование регулярных выражений; 3.)
предварительное преобразование html-страницы в xml-формат. Эти подходы в основном опираются на
человеческий фактор. Возможность автоматизации процесса извлечения табличных
данных может быть достигнута за счет совместной реализации первых двух
подходов.
Исходная модель предметной области может быть
представлена в виде древовидного графа, в узлах которого отображаются имена
определяемых понятий (например, «процессор», «частота», «кол-во ядер»), а ветви
соответствуют отношениям типа «часть-целое», например, как это показано на рис.
1.
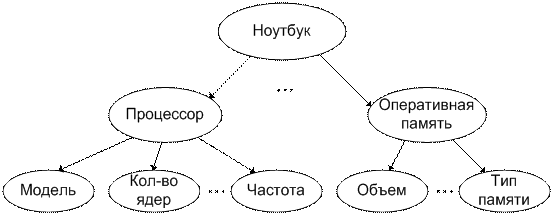
Рис. 1. Пример упрощенной модели предметной области
Предлагаемый механизм основан на построении так
называемого DOM-дерева (от англ. Document Object Model) [2], с помощью которого
осуществляются переходы по тегам документа, что позволяет последовательно
зафиксировать местоположение узлов графов в html-странице и соответствующие им искомые значения в виде
записей (например, «2200 МГЦ» - найденное значение частоты процессора, «2» -
кол-во ядер процессора).
На
основании результатов, полученных при осуществлении переходов по узлам дерева,
можно сделать выводы о наличии данных для записей. Причем, одинаковая
последовательность тегов, полученных, при движении от разных понятий модели
предметной области, и равенство значений «всего» от первого до предпоследнего тега, а
также разные значения «место» для предпоследнего тега свидетельствуют о схожем
расположении ключевых слов. Отображение процесса поиска и возможный результат
показаны в таблице 1, где «table», «tr», «td» - теги
форматирования, «Частота» - ключевое слово, принадлежащее модели предметной
области, «всего» - степень разветвления тега, «место» - порядковый номер
расположения тега.
|
|
table |
tr |
td |
Частота |
||
|
место: |
1 |
7 |
1 |
2000 МГЦ |
||
|
всего: |
1 |
10 |
|
|
Для реализации указанной последовательности действий можно
воспользоваться библиотеками, например: Html
Agility Pack [3] для платформ .NET или
Beautiful Soup [4], в случае, если программа будет написана на языке Python.
Для локализации области поиска в html-странице, а также исключения лишней информации из
данных результатов целесообразно воспользоваться механизмом регулярных
выражений.
Проведенные эксперименты подтвердили возможность
автоматического извлечения табличных данных на пополняемой модели предметной
области.
Литература
1.
Дзегелёнок
И. И., Филипьев И. В. Подход к созданию интеллектуального агента согласованного
информационного поиска в Интернет. 9-я Национальная конференция по
Искусственному Интеллекту – КИИ-2004 (28 сентября – 2 октября). Труды
конференции. Том 2. – М.: Физматлит, 2004, с.715-722
2. http://www.w3.org/DOM/ – собрание материалов Document Object Model
3. http://www.htmlagilitypack.codeplex.com – описание и
исходный код библиотеки Html Agility Pack
4. http://www.crummy.com/software/BeautifulSoup/ – описание и
исходный код библиотеки Beautiful Soup