BC/NW 2011; №2 (19):2.1
КОММУНИКАТОР
МНОГОПРОЦЕССОРНОЙ ВЫЧИСЛИТЕЛЬНОЙ СИСТЕМЫ
Мороховец Ю.Е., Шполянский М.И.
(Национальный исследовательский университет «МЭИ», Россия)
На сегодняшний день для параллельных вычислений широко применяются
многопроцессорные и многомашинные вычислительные системы. В то время как
процессорные модули и машины считаются центральными компонентами таких систем,
ключевыми устройствами, позволяющих наладить их совместную работу, являются
коммутаторы. Коммутаторы обеспечивают параллельную работу процессорных модулей
и вычислительных машин в системах. Коммутаторы могут быть реализованы как
единое целое, так и состоять из отдельных компонентов, так называемых
коммутационных модулей. Они могут осуществлять передачу данных как с промежуточным
хранением (буферизацией) пакетов, так и без него [1]. Коммутаторы с
буферизацией передаваемых пакетов называются коммуникаторами.
В работе рассматривается коммуникатор для многопроцессорных
вычислительных систем, построенный на основе кольцевой ассоциативной памяти –
закольцованного массива ячеек c0,
…, ci, ci+1, …, cn-1, содержимое
которых циклически сдвигается в соответствии с правилом if i<n–1 then ci→ci+1 else ci→c0. Доступ к содержимому
ячеек по записи и чтению ассоциативный, предполагающий сравнение ключевых
разрядов ячеек с данными находящимися в точках доступа, называемых портами
(рис. 1).
В процессе работы коммуникатора, процессорный модуль PM формирует заявки на передачу пакетов
– дескрипторы пакетов с данными об их объеме, адресе процессорного модуля
отправителя и адресе процессорного модуля получателя. Пакет представляет собой
последовательность кадров, причем каждый
отдельно взятый кадр может храниться в ячейке кольцевой ассоциативной памяти MOM. Заявка и сам пакет поступают в
модуль памяти ММ.
Емкость модуля памяти достаточна для хранения всех пакетов, соответствующих
дескрипторам в буфере заявок, включая случай, когда этот буфер заполнен
полностью.
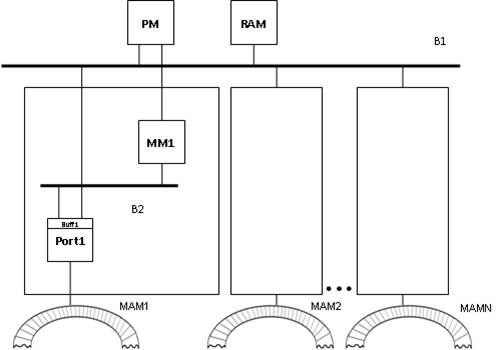
Рис. 1. Структура коммуникатора
PM – процессорный модуль; RAM – запоминающее устройство с произвольной
выборкой; MM – модуль памяти; Buff – буфер кадров порта; Port – порт; SM – коммутационный модуль; MAM
– модуль кольцевой ассоциативной памяти
Параллельно с этим, по сигналу процессорного модуля, при условии, что
буфер Buff не полон, кадр (либо
кадры, в зависимости от доступного места в буфере Buff) поступают по шине В2 из ММ в порт.
Порт осуществляет взаимодействие процессорного модуля PM с модулем ассоциативной памяти МАМ. МАМ представляет
собой закольцованный массив ячеек, содержимое которых циклически сдвигается
такт за тактом. Порты, подключенные к модулю МАМ в равноудаленных точках кольца, имеют возможность просматривать
содержимое ячейки, через которую последовательно, цикл за циклом проходит весь
массив кадров. Как уже было сказано, запись и чтение содержимого ячейки,
просматриваемой портом, осуществляются ассоциативно. Расстояние (число ячеек)
между портами определяет размер сектора кольца и связано с объемом передаваемых
пакетов. Кадры из порта размещаются в ячейках кольцевой ассоциативной памяти по
мере поступления их из буфера кадров, в зависимости от того, занята ли ячейка
памяти, просматриваемая портом, или нет. Важно отметить, что в случае, если
буфер запросов переполнен, то работа
процессорного модуля прекращается в случае необходимости передачи очередного
пакета.
Интенсивности потоков пакетов различны для каждого из портов кольца.
При этом логическая структура потоков представима в виде полного графа, где
каждая вершина (процессорный модуль) соединена со всеми остальными вершинами
графа.
Следует отметить, что принципы построения MAM делают возможным множественный доступ к массиву хранимых в ней
кадров и, что самое главное, гарантируют отсутствие коллизий при доступе к
памяти с увеличением числа процессорных модулей, невозможность одновременного
доступа к одним и тем же кадрам с различных направлений. Это позволяет
рассматривать отдельно взятый кадр как критический ресурс, доступный
одновременно только одному процессорному модулю, связанному с определенным
портом доступа.
Рассматриваемый подход к организации передачи пакетов между
процессорными модулями является интересным в первую очередь благодаря
перспективам дальнейшего развития и совершенствования. По мере продвижения
разработки становится ясно, что предлагаемая концепция может позволить,
используя множество доступных на сегодняшний день вычислительных устройств и
устройств памяти, создавать высокопроизводительные вычислительные системы с
числом процессорных модулей порядка 28 – 210 штук. Кроме
того, перспективным является возможность эффективного использования стандартной
программной системы передачи сообщений MPI
[2] при разработке прикладного программного обеспечения многопроцессорных
систем, построенных на базе кольцевой ассоциативной памяти.
ЛИТЕРАТУРА
1. Дерюгин А.А. Коммутаторы вычислительных
систем – М.: Издательский дом МЭИ, 2008. – 112 с.
2.
Антонов
А.С. Параллельное программирование с использованием технологии MPI. – М.: Изд-во МГУ, 2004. – 71 с.