Методология организации
эффективного использования
гипертекстовых систем для
корпоративных
вычислительных сетей
Л.И. Абросимов, И.О.
Хомерики
На основании анализа требований, предъявляемых к корпоративным вычислительным сетям, определяется роль гипертекстовых систем, обеспечивающих функционирование сетей и приводятся основные задачи, которые решаются предлагаемой методологией организации эффективного использования корпоративных вычислительных сетей.
Введение
В последние годы с особой остротой встают задачи
создания и модернизации таких сложных систем как корпоративные вычислительные
сети (КВС), с целью своевременной обработки и передачи все возрастающих потоков
информации, а также коллективного использования распределенных баз данных,
технических и программных средств. Актуальность проблемы развития методов
проектирования и управления, оценки производительности и эффективности
функционирования КВС определяется внутренне присущими им свойствами, такими как
большая размерность, многосвязность, сложность процессов управления и
функционирования при обеспечении обработки и передачи информации.
Информация становится
неотъемлемой частью производственного процесса, такой же как и материальная и
инструментальная составляющие технологического процесса. В тех случаях, когда
все производственные и информационные компоненты преследуют достижение единой
цели, когда все управляющие решения, в том числе и по организации
функционирования, допускают принятие решений по комплексному развитию
компьютерных технологий, можно получить максимальный эффект от
производственного процесса за счет использования интегрированного, комплексного
подхода к технологической и информационной обработке.
Требования к гипертекстовым системам
корпоративных вычислительных сетей.
Проблемы, которые возникают
при создании высокоэффективных вычислительных сетей, непосредственно
обслуживающих производственные процессы, вызваны необходимостью:
- хранения и обеспечения
доступа к мультимедийной информации,
- обеспечения доступа к
технологической информации в реальном времени,
- обеспечения
многопользовательского режима,
- обеспечения организации и
использования распределенных баз данных ,
- эффективного использования
сетевых ресурсов,
- принимать решения по
эффективному управлению обменом данных в распределенных вычислительных сетях,
характеризующихся структурной сложностью, большой размерностью и произвольной
топологической конфигурацией.
Таким образом, сформировался
широкий круг неисследованных проблем создания и развития корпоративных
вычислительных сетей (КВС).
Функционирование и развитие корпораций зависит от
того, как решена в корпорации проблема информационного обеспечения,
необходимого для решения задач управления и технологической поддержки.
При создании и развитии КВС в существенной степени
работу проектировщиков усложняют распределение отделений корпорации по
территории, количество пользователей и размерность требуемой информационной
базы.
Объем трафика, формируемого в подразделениях
корпорации отдельными пользователями, существенно влияет на затраты и формирует
повышенные требования к техническим, программным и организационным средствам
ККС.
При создании и развитии КВС трудно разрешимые
проблемы возникают из-за высоких требований к оперативности поиска и доставки
информации, необходимой для решения технологических, информационных и
управленческих задач корпорации.
Организационные средства КРВС обеспечивают повышение
качества функционирования, что позволяют решить многие проблемы корпорации.
Специалисты, занимающиеся разработкой вычислительных
сетей, и сетевые администраторы предъявляют три основных требования:
масштабируемость, производительность и управляемость.
Реальным
направлением решения выделенных проблем является
развитие и внедрение методологии, обеспечивающей эффективное комплексное решении
задач организации информационного обеспечения для различных уровней
детальности:
- гипертекстов, входящих в
состав базы данных (БД) одного файл-сервера,
- баз данных, входящих в
файл-серверы, распределенные по узлам КРВС.
Основным свойством гипертекстовых систем является возможность описания и
динамического изменения логических связей между отдельными информационными
модулями (гипертекстовыми документами). Указание связей в ГТС позволяет
требуемым образом организовать
информацию для ее эффективного использования. Возможности по организации ГТС
посредством целенаправленного установления связей между отдельными
информационными модулями можно рассматривать как ресурс для повышения
эффективности информационного обеспечения.
Комплексная методология организации эффективного
использования гипертекстовых систем
Эффективная организация ГТС КВС достигается
следующими средствами:
использованием свойств гипертекстовых систем (ГТС),
использованием возможности количественной оценки
трафика распределенных корпоративных вычислительных сетей,
использованием свойств унифицированности серверов
ГТС,
использованием свойства каналов связи распределенных
корпоративных вычислительных сетей.
Для повышения эффективности организация ГТС были
проведены исследования, которые позволили
разработать:
- методологию синтеза линейных текстов для уровня
локальной организации, которая включает: методику построения графа тематик,
методику анализа графа тематик, методику построения графа терминов в каждой
тематике и методику анализа графа терминов.
- методологию комплексного размещения гипертекстовых
систем для КРВС произвольной конфигурации, которая включает математическую модель для обеспечения
эффективности организации информационного обеспечения пользователей КРВС,
аналитическую модель для исследования влияния параметров КРВС на критерий
эффективности, алгоритм поиска эффективных организационных решений КРВС и
программные средства, реализующие разработанный алгоритм.
В настоящее время разработаны основы методологии эффективной организации ГС, основанные на
комплексе математических моделей, объединяющих:
математическую модель
взаимодействия гипертекстовых документов,
аналитическую модель
размещения гипертекстовых систем в равномерно-распределенном пространстве,
математическую модель размещения
гипертекстовых систем в распределенных вычислительных сетях, используемых в
корпоративных сетях для комплексного информационного обеспечения
производственных процессов.
Синтез линейных текстов для уровня локальной
организации
Методика синтеза линейных текстов с заданными
параметрами рассматривает задачу создания гипертекстов на основе синтеза
текстов, специально подготавливаемых для этой цели.
Нелинейный текст характеризуется множеством M
имеющихся в нем статей (m1 , m2 ,…me),которые назовем блоками
данных:
M =
{m1 , m2, ..., me )
Нелинейные и линейные тексты могут быть объединены
общим подходом в том случае, если любой нужный том разбить на небольшое
множество M небольших блоков данных, каждый из которых посвящен
какой-нибудь теме, событию, явлению, вещи, процессу. Такими блоками могут быть
параграфы, страницы и т.д. Разбиение на блоки данных происходит в результате
проводимого анализа текстов томов.
Наличие множества блоков данных позволяет выполнить
вторую задачу – определить множество N ассоциативных или
тематических взаимосвязей этих (n1 , n2, ...n f) блоков:
N =
(n1 , n2, ...n f)
В результате, любой тип текста превращается в
гипертекст – структуру, определяемую множествами блоков данных (M) их
взаимосвязей (N). Гипертекст целесообразно отображать в виде графа.
Граф, определяемый множествами M, N, показывает взаимосвязь
тем, описываемых блоками данных, который называется тематическим. В нем блоки
данных изображаются в виде концов, прямоугольников либо окружностей. Каждая
односторонняя связь двух блоков представляется стрелкой, а двусторонняя –
линией.
Создание гипертекста определяет (рис. 1) первый,
подготовительный этап преобразования структур. Его выполнение позволяет перейти
ко второму, главному этапу, который заключается в создании новых линейных
текстов, представляющих искомую информацию.
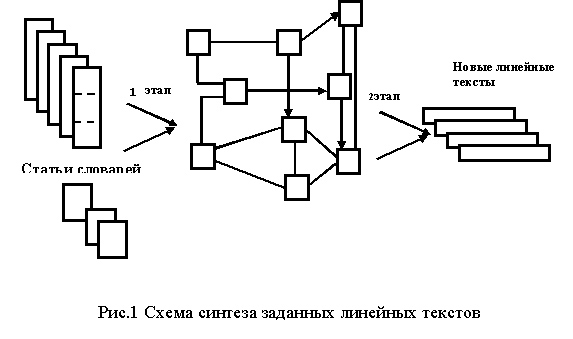
Методов построения этих структур может быть очень
много. Они определяются поставленной целью, подбором и последовательностью
компоновки блоков данных. Однако, наиболее эффективно эта компоновка
осуществляется путем использования ассоциативных или тематических взаимосвязей.
Методика определения маршрута просмотра тематических документов.
Гипертекстовая система содержит большое число блоков
информации, представленных в виде отдельных статей. В этой связи возникло
понятие ”география информационного пространства”, которое соответствует не
столько физическому, сколько логическому пространству взаимосвязи отдельных
событий, явлений, объектов процессов.
В каждой статье гипертекстовой системы даются
ссылки, определяющие ассоциативные (тематические) связи с другими статьями. Эти
связи можно изобразить в виде единичного элемента графа. Совмещая единичные
элементы графа друг с другом, получаем граф тематики. Примеры графов тематик
представлены на рис. 2, 3.
Рис. 2. Граф тематики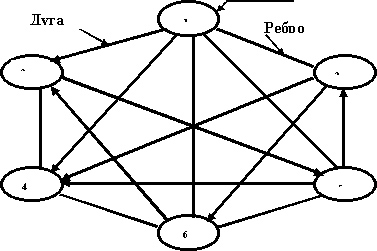
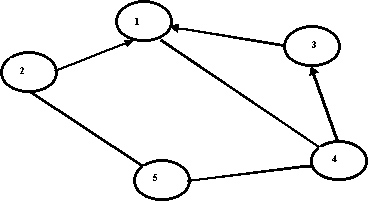
Рис. 3. Граф с взаимоисключающими маршрутами
Определение маршрута движения пользователя при
обучении происходит в два этапа. На первом из них строится граф тематики, охватывающий заданный перечень статей. На втором
этапе осуществляется прокладка маршрута
движения по графу.
Для определения маршрута в графе на первом шаге
отмечаются вершины, в которые должен попасть пользователь. Вторым шагом является
выбор начальной вершины, которая определяется, исходя из того, чтобы двигаясь
из нее можно было пройти максимум вершин, переходя каждую из них только один
раз. На третьем шаге производится выделение дуг и ребер, образующих
последовательность соединения возможно большего числа выделенных вершин. При
этом образуется q не связанных друг с другом множеств вершин (в
редких случаях q=1). На четвертом, последнем шаге, полученные
множества вершин соединяются между собой. Для этого необходимо по графу
проложить между этими множествами такой маршрут, чтобы к выделенным вершинам
добавилось минимальное число дополнительных вершин. В результате получаем общую
последовательность вершин, определяющую маршрут следования пользователя по
графу в процессе обучения.
Методика обучения терминологии в гипертекстовых системах
Представив рассматриваемые термины вершинами, а их
взаимосвязь –дугами, получаем граф
терминов. Граф повторяющий этапность определения взаимосвязи незнакомых
терминов, назовем исходным.
Построенный исходный граф необходимо перестроить по следующим правилам. Вершины
исходного графа поделить по множествам так, чтобы в первое множество попали
только те вершины ( g1 ), в которые в исходном графе не входит не
одна дуга. Они представляют термины, в определениях которых нет ни одного
незнакомого термина. Второе множество образуют вершины ( g2 ), в которые входят дуги
только из вершины g1. Эти вершины представляют термины, в определениях
которых используются только термины, представленные вершинами g1. В третье множество
включаются вершины, в которые входят дуги из вершин g1, g2 Формирование множеств продолжается до тех пор, пока
все вершины исходного графа будут разделены по множествам. В результате получим
нормальный граф терминов, который является ориентированным ациклическим графом.
Чаще всего нормальный граф терминов содержит более
одной вершины. Поэтому в подавляющем большинстве случаев нельзя познакомится с
определением только одного термина. Пользователь вынужден сразу изучить группу
терминов, представленных графом терминов. И лишь в том случае, когда граф
содержит только одну вершину, пользователь может познакомиться с определением
одного термина.
Таким образом, Проведенный анализ функций, которые
необходимо выполнять при создании гипербаз, позволяет определить алгоритмы их
реализации. Важнейшая из рассмотренных функций описывается алгоритмом
подготовки статей как основных блоков гипертекста. Предложена методика введения
новых статей в гипертекст и удаления из него тех статей, которые устарели
или оказываются ненужными.
Комплексное размещение гипертекстовых систем для
КРВС
Корпоративные сети, могут включать в свой состав
широкий набор технических решений и образовывать сложные структуры (см. рис. 4.
)
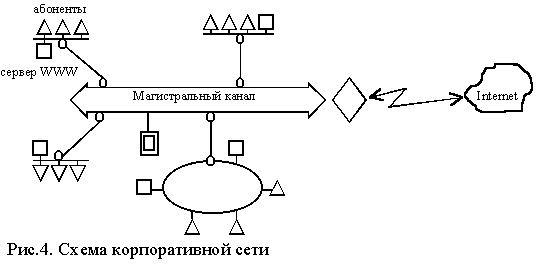
В процессе функционирования абоненты сети
взаимодействуют с информационными ресурсами, размещенными в серверах.
Задачу, комплексного размещения гипертекстовых
систем (КРГС), возникающую при проектировании, можно сформулировать следующим
образом.
Задана связная транспортная сеть произвольной конфигураций
S с числом узлов N. Каждому пользователю, расположенному
при узле сети aj , в течение
периода Т необходимо установить fjr сеансов с
процессом Рr, (r=![]() ) каждый из которых может располагаться в серверах, устанавливаемых в узлах ai . Каждый процесс Рr
в сети может иметь несколько реализаций Рrm
(m=
) каждый из которых может располагаться в серверах, устанавливаемых в узлах ai . Каждый процесс Рr
в сети может иметь несколько реализаций Рrm
(m=![]() ).
).
Требуется определить количество m реализаций процессов Рrm , распределить процессы Рrm по узлам сети и по
серверам, чтобы затраты на организацию размещения, передачу и обработку
информации были минимальными.
Эффективность функционирующей КРВС определяется
общими затратами С, состоящими из
затрат СП на передачу
информации запроса и ответа, затрат CХ
на хранение программного и информационного обеспечения и затрат СО на технические средства,
выполняющие вычислительные и логические операции при обработке запросов, т.е.
С = СП
+ СХ + СО.
(3)
Затраты CП
на передачу информации в КРВС можно определить по соотношению:
![]() (4)
(4)
где Lijrm=
lrmij + lrmji


Затраты СХ
определяются суммой затрат ![]() на хранение программ и информационных массивов объемом Vr, обеспечивающих одну
реализацию процесса Рr,
которые располагаются в серверах узлов ai
и рассчитываются по соотношению:
на хранение программ и информационных массивов объемом Vr, обеспечивающих одну
реализацию процесса Рr,
которые располагаются в серверах узлов ai
и рассчитываются по соотношению:
![]() .
(5 Отсюда приведенные затраты CO на вычислительные средства
могут быть определены по соотношению:
.
(5 Отсюда приведенные затраты CO на вычислительные средства
могут быть определены по соотношению:
![]() ,
(6)
,
(6)
где 
Целевая функция математической модели
рассматриваемой задачи размещения может быть записана с учетом (3), (4),
(5), (6) в виде:
![]() [(
[(![]() )+(
)+(![]() )+ +(
)+ +(![]() ] (7)
] (7)
При минимизации целевой функции (7) необходимо учитывать следующие ограничения. Во-первых, каждый
процесс Рr должен
размещать во всех узлах {аi} не менее одного дубля массива:
![]() (8)
(8)
Во-вторых, если узлу аj в течение периода Т
требуется установить с процессом Рr
число сеансов fjr > 0, то узел аj должен обслуживаться одной из групп Гrm, т.е. ![]() , следовательно,
, следовательно, ![]() (9)
(9)
Проведены
исследования для теоретического обоснование алгоритма решения задачи КРГС.
В рамках предложенной методологии :
- вначале проводится анализ с целью обоснования
существования минимального значения ![]() для выведенного
функционала (7);
для выведенного
функционала (7);
- излагается обоснование базисных принципов
алгоритма поиска решения;
предлагается пошаговый алгоритм, обеспечивающий
поиск решения;
- проводятся исследования сложности предложенного
алгоритма обеспечивающего поиск решения.
Обоснование существования оптимального решения
Варьируемые булевские переменные ![]() ,
, ![]() являются независимыми и на включение в допустимое решение
каждого из них накладываются простейшие ограничения вида (8),
(9), что в незначительной степени
ограничивает число возможных комбинаций в вариантах решения.
являются независимыми и на включение в допустимое решение
каждого из них накладываются простейшие ограничения вида (8),
(9), что в незначительной степени
ограничивает число возможных комбинаций в вариантах решения.
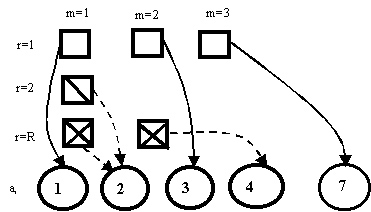
Для фрагмента вычислительной сети, приведенном
рис.5, каждая булевская переменная связана с номером узла ![]() и номером
процесса
и номером
процесса ![]() , при этом
, при этом ![]() =1 означает, что процесс
=1 означает, что процесс ![]() расположен при узле
расположен при узле ![]() ,
,
П
р
о
ц
е
с
с
ы
![]()
Рис. 5. Размещение
процессов ![]() при узлах
при узлах ![]()
Значение ![]() = 1 указывает на принадлежность узла
= 1 указывает на принадлежность узла ![]() группе
группе ![]() обслуживания
процессом
обслуживания
процессом ![]() , что иллюстрируется фрагментом сети, представленном на рис.6
и содержащем в своем составе группы: Г1,1,
Г1,2, Г1,3, Г2,1, ГR,1, ГR,2
, что иллюстрируется фрагментом сети, представленном на рис.6
и содержащем в своем составе группы: Г1,1,
Г1,2, Г1,3, Г2,1, ГR,1, ГR,2
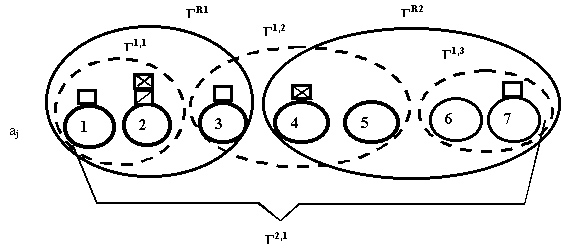
Рис. 6. Объединение узлов в группы обслуживания
Таким образом, любое допустимое решение можно
записать в виде двух трехмерных матриц X и Y.
Проведенный анализ равномерно-распределенных
вычислительных сетей (РРВС) позволил сформулировать основные принципы,
положенные в основу предложенного алгоритма задачи КРГС, который обеспечивает
отыскивать решение для корпоративных сетей реальной размерности.
Разработанный в соответствии с предложенными и
теоретически обоснованными в диссертации принципами эвристический алгоритм
представлен на рис. 7.
исследования точности разработанного алгоритма
основана на генерации наборов исходных данных, для каждого из которых задача
размещения гипертекстовых систем решается с применением разработанного и
точного алгоритмов. Точность предложенного алгоритма КРГС определяется как
усредненная относительная точность для всех наборов исходных данных.
По результатам проведения вычислительных экспериментов
для оценки точности алгоритма КРГС вычислены основные статистические
характеристики.
Средняя арифметическая точность алгоритма КРГС
определяется значением: ![]() = 103,67%
= 103,67%
Средняя квадратическая ошибка, определяющая степень
точности вычисления средней арифметической точности алгоритма КРГС определяется
значением: ![]() = 5,886
= 5,886
Точность средней арифметической характеризуется
средней квадратической ошибкой: ![]() = 0,6239
= 0,6239
Возможная предельная ошибка оценивается как: ![]() = 1,8717
= 1,8717
Экспериментально установлено, что средняя
арифметическая точность алгоритма КРГС укладывается в 104%.
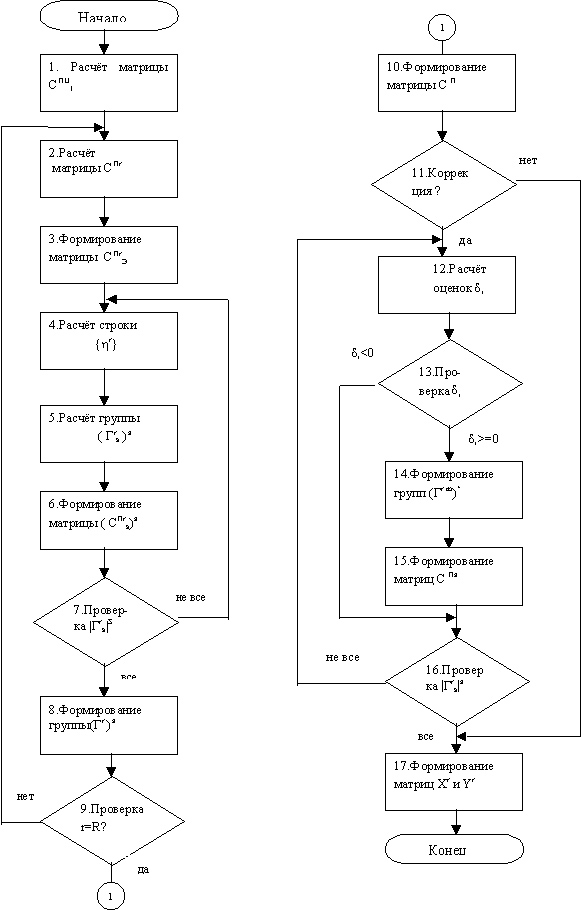
Рис.7. Алгоритм комплексного
размещения гипертекстовых систем
Заключение
Разработанная методология
позволила реализовать решение следующих исследовательских задач:
1. Предложить критерии оценки
эффективности принимаемых решений по организации БД. [1, 6, 11, 12]
2. Разработать комплексную
математическую модель, описывающую связи варьируемых параметров и характеристик
гипертекстовых документов, взаимодействующих между собой при обслуживании
поисковых запросов.[1, 2, 3, 4, 5]
3. Разработать комплексную
математическую модель, описывающую связи варьируемых параметров и характеристик
функционирования корпоративной сети.[6, 11, 12]
4. Разработать алгоритмы
поиска эффективных решений оптимизационной задачи, сформулированной на основе
математической модели.[9, 11, 12]
5. Разработать методы и
средства для проверки адекватности математической модели.[7, 9,10]
6. Разработать средства и
произвести проверку точности алгоритма поиска эффективных решений.[10]
Таким
образом, разработанная методология, базирующаяся на созданном комплексе
прикладных программ, позволяет успешно разрешить существенную часть проблем,
которые возникают у разработчиков корпоративных вычислительных сетей.
ЛИТЕРАТУРА
1. Хомерики И.О. - Проблемы гипертекста. -
Грузинский технический университет. Научные труды. №3 (414). 1997. Тбилиси.
с.270-277;
2. Хомерики И.О. - Обучение терминологии в
гипертекстовых системах. - Грузинский технический университет. Научные труды.
№5 (416). 1997. Тбилиси. с.149-157;
3. Хомерики И.О. - Синтез текстов в гипертекстовых
системах. - Грузинский технический университет. Научные труды. №1 (417). 1998.
Тбилиси. с.175-185;
4. Хомерики И.О. - Структура гипертекста. Сообщения АН Грузии. - 1998. Том 157, №2. -
с. 277-279;
5. Хомерики И.О. Гипертекст в информатике
(монография). - Изд.-во “Технический университет”. Тбилиси. 1999. c.102;
6. Хомерики И.О. - Размещение гипертекстовых систем
в распределенных вычислительных сетях. - Журнал “Интелекти” № 3 . 1999.
Тбилиси. с.90-94;
7. Хомерики И.О. - Методика иерархической оценки
сложности алгоритмов. - Труды международного симпозиума “Информация,
автоматизация, управление”. Тбилиси – 2000. с.36-39;
8. Хомерики И.О. - Оптимизация организации
информационного обслуживания в равномернo распределенных вычислительных сетях.
- Труды международного симпозиума “Информaция, автоматизация, управление”.
Тбилиси – 2000. с.39-43;
9. Хомерики И.О. - Реализуемость эвристических
алгоритмов комбинаторных задач. - “Инженерные новости Грузии“, 2000, №4., с.
21-35;
10. Хомерики И.О. - Методика оценки точности
эвристических алгоритмов комбинаторных задач. - “Автоматизация и современные
технологии“, №6, 2001, Москва. с. 22-24;
11. Хомерики И.О. - Размещение массивов
коллективного пользования в корпоративных вычислительных сетях. - “Инженерные
новости Грузии“, 2001, №1., с. 27-32;
12. Мясников В.А., Мельников Ю.Н., Абросимов Л.И.
Методы автоматизированного проектирования систем телеобработки данных. Учебн.
пособие для вузов. М.: Энергоатомиздат 1992