BC/NW
2012; №2 (21):10.2
АЛГОРИТМ ФОРМИРОВАНИЯ БАЗЫ
ДАННЫХ ДЛЯ ФРАГМЕНТАРНОГО МЕТОДА СЖАТИЯ ВИДЕОПОТОКА БЕЗ ПОТЕРЬ
Огнев И.В., Огнев А.И., Горьков А.Г.
Разработка методов, алгоритмов и аппаратных сред сжатия видеоизображений является одним из важнейших направлений современных информационных технологий. Сжатие видео позволяет уменьшить объём данных, необходимый для передачи видео или его хранения.
На сегодняшний день разработаны довольно эффективные методики сжатия видео с потерями. Для многих приложений возникающие потери и артефакты (блочность, замыливание и т.д.) незначительны, но существует широкий круг задач в которых потери недопустимы. К задачам, где потери недопустимы, можно отнести системы видеонаблюдения, научные видеоданные, архивные записи (например записи выборов).
На текущий момент существуют способы сжатия видео без потерь (кодеки CorePNG, FFV1, Huffyuv, MSU Lossless Video Codec и другие), но обеспечиваемая ими степень сжатия и время их работы пока недостаточны для их широкого внедрения.
В данной статье рассматривается перспективный подход к сжатию видео без потерь.
Основные определения
При описании работы алгоритма мы будем оперировать следующими понятиями:
·
Видеопоток (фильм) можно рассматривать
как одномерный массив кадров. Мощность массива кадров равна количеству кадров в
фильме, причём индекс в этом массиве является временной меткой. Длиной
видеопотока будем называть число ![]() ,
равное количеству кадров в видеопотоке. Подробно структура видеопотока показана
на Рис. 1.
,
равное количеству кадров в видеопотоке. Подробно структура видеопотока показана
на Рис. 1.
·
Кадр
– набор всех видимых пикселей (с заданными в них значениями яркости) в
конкретный момент времени. Кадр можно рассматривать, как двумерный массив
высотой![]() пикселов и шириной
пикселов и шириной![]() пикселов.
пикселов.
· Пиксел – минимальная единица изображения. Каждый пиксел хранит информацию о собственном цвете, причём цвет может быть представлен различными способами: это могут быть и сведения об интенсивности каждого из базовых цветов, и цветоразностные компоненты, и некоторые другие способы.
·
Окно – прямоугольная область пикселов высотой ![]() пикселов и шириной
пикселов и шириной ![]() пикселов.
пикселов.
· Фрагмент – часть кадра, ограниченная окном. Иногда для удобства хранения и операций фрагмент может быть представлен двоичной строкой.
· Разность – результат применения операции исключающего ИЛИ к двум фрагментам, соответствующим одному окну в двух соседних кадрах.
· База данных элементов – набор всех элементов (и их частот), которые реально встречаются в сжимаемом видеопотоке в соответствующих окнах. База элементов может формироваться как из фрагментов, так и из их разностей
· Код элемента – двоичный код, позволяющий однозначно идентифицировать элемент в базе. Самые частые элементы получают самые короткие коды.
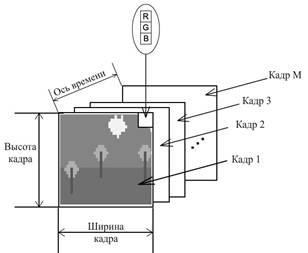
Рис. 1. Структура видеопотока
Сжатие без потерь возможно, потому что кадры почти никогда не являются полностью случайными. Более того, зачастую различия между соседними кадрами весьма незначительны. В пределах одного кадра изображение тоже далеко неслучайно. Именно эта "неслучайность" позволяет сжимать видеопоток. Большинство существующих алгоритмов идёт по одному из двух путей:
· Каждый кадр сжимается независимо (для этого используются известные алгоритмы сжатия без потерь, например, deflate);
· Сжимаются похожие соседние кадры.
Предложенный алгоритм использует идеи обоих методов: за счёт того, что элементы кодируются своими короткими кодами, уменьшается объём каждого кадра в отдельности, и соседние похожие кадры кодируются меньшим числом бит (при формировании базы разностей нулевая разность самая частая, поэтому кодируется самым коротким кодом).
Особенностью предлагаемого метода является то, что похожие элементы ищутся в пределах всего видеопотока, т.е. сжимается весь фильм целиком, а не только соседние кадры.
Выбор характеристик видеопотока
Из описания структуры видеопотока, приведённого выше, видно, что видеопоток обладает множеством характеристик. Это, как минимум, размер кадра и формат хранения цвета. На самом деле характеристик много больше:
· Частота кадров – это число кадров, сменяющих друг друга при показе 1 секунды видеопотока и создающих эффект движения объектов на экране. Для алгоритма сжатия видеопотока исходная частота несущественна. Единственное ограничение – достаточная скорость восстановления кадров при воспроизведении видео.
· Стандарт разложения (развёртка) видеосигнала может быть прогрессивным (построчным) или чересстрочным. При прогрессивном разложении все горизонтальные линии (строки) изображения отображаются поочередно одна за другой. При чересстрочном разложении показываются поочерёдно то все чётные, то все нечётные строки. Описываемый алгоритм более эффективен при прогрессивной развёртке, т.к. получаемые при чересстрочной развёртке полукадры хуже сжимаются.
· Соотношение сторон — важнейший параметр в любом видеоматериале. С 1910 года кинофильмы имели соотношение сторон экрана 4:3 (4 единицы в ширину к 3 единицам в высоту). Чтобы приблизить форму кадра к естественному полю зрения человека был введён стандарт 16:9. К концу XX века, после ряда дополнительных исследований стали появляться более радикальные соотношения сторон кадра, например, 21:9. Разработанный алгоритм сжатия нечувствителен к соотношению сторон видеопотока. Весь экспериментальный видеоматериал был представлен с соотношением сторон 4:3, т.к. именно оно на текущий момент является наиболее распространённым.
·
Разрешение видеосигнала (вертикальное и
горизонтальное) измеряется в пикселах. При этом разрешение плотно связано с
соотношением сторон. Например, VGA-режим
![]() соответствует соотношению сторон
соответствует соотношению сторон ![]() .
Для экспериментов был выбран широко используемый стандарт разрешения QVGA (
.
Для экспериментов был выбран широко используемый стандарт разрешения QVGA (![]() ).
).
· Цветовое разрешение — это количество цветов в видеоматериале определяется числом бит, отведённым для кодирования цвета каждого пикселя (англ. bits per pixel, bpp). Для упрощения экспериментов значение bpp было установлено равным 4. Это означает, что в видеопотоке, каждый пиксел может отображать 16 градаций серого цвета.
Всё дальнейшее описание верно для видеопотока с
прогрессивной развёрткой, разрешением ![]() и 16 градациями серого цвета.
и 16 градациями серого цвета.
Предварительная обработка видеопотока
Для приведения видеопотока в соответствие с этими требованиями использовался популярный редактор видео VirtualDub. Этот редактор обладает обширным набором быстрых и хорошо отлаженных фильтров.
Рассмотрим процесс предварительной обработки на примере
первой серии сериала Star Trek:
TOS. Этот фильм изначально полноцветный и представлен в
разрешении ![]() .
Чтобы преобразовать его в нужный формат мы добавляем два видео-фильтра:
.
Чтобы преобразовать его в нужный формат мы добавляем два видео-фильтра:
·
resize – изменение размеров кадра. Мы преобразуем кадр к размеру ![]() пикселов. Важно заметить, что соотношение
сторон при это не меняется (
пикселов. Важно заметить, что соотношение
сторон при это не меняется (![]() );
);
· grayscale – преобразование цветного фильма в фильм в градациях серого.
На Рис. 2 показан пример обработки одного изображения:
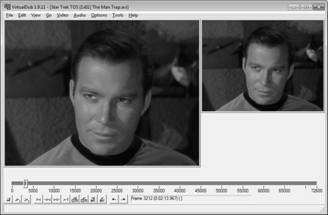
Рис. 2. Изображение до и после обработки в VirtualDub
После обработки этими фильтрами у нас есть фильм в градациях
серого, при этом для кодирования яркости одного пиксела отводится 8 бит. Для задачи
сбора базы нам необходим фильм, в котором яркость пиксела кодируется 4 битами. Средствами VirtualDub
эту задачу
решить невозможно, поэтому понижение цветности до 4 бит на пиксел выполняется
во время сжатия при получении каждого нового кадра.
Каждый
пиксел в зависимости от своей яркости получает одно из 16 возможных значений. Какое
именно значение получит пиксел, определяется с помощью серии последовательных
сравнений. Порядок сравнений представлен на Рис. 3, а пример обработки
изображения на рис. 4.
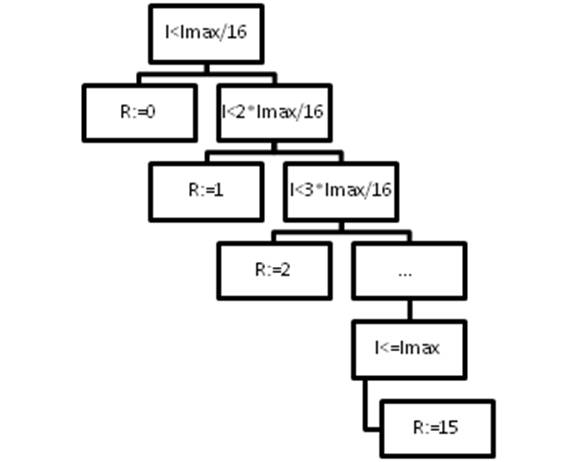
Рис. 3. Порядок
сравнений при понижении цветности
При этом ![]() – максимально возможная яркость пиксела (белый
цвет),
– максимально возможная яркость пиксела (белый
цвет), ![]() - яркость текущего пиксела,
- яркость текущего пиксела, ![]() - значение, которое пиксел примет после
анализа.
- значение, которое пиксел примет после
анализа.
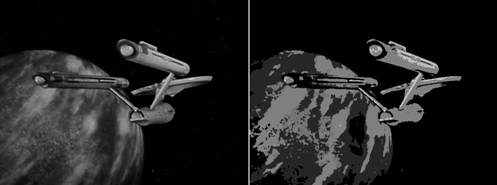
Рис.
4. Изображение до и после понижения цветности до 4 бит на пиксел
Алгоритм сжатия видеопотока
Алгоритм сжатия состоит из трёх этапов:
1. Формирование базы элементов. На этом этапе для всех окон вычисляются все элементы, реально встречающихся в видеопотоке.
2. Построение коротких кодов для элементов. Для получения кодов строится кодовое дерево;
3. Кодирование фильма. Для каждого окна соответствующий элемент кодируется полученным на 2 шаге коротким кодом.
В данной работе изложен алгоритм формирования базы разностей.
Формирование базы разностей
Формирование базы разностей состоит из двух этапов:
1.
Создание локальных баз разностей;
2. Слияние локальных баз разностей.
Локальные базы создаются с целью повышения быстродействия. Размеры баз разностей очень велики. Зачастую они становятся настолько большими, что хранение их в ОЗУ не представляется возможным.
Если базы хранить и создавать напрямую на диске, то тогда процесс поиска и добавления значений будет расходовать слишком много времени (т.к. обращения к диску намного медленнее, чем к ОЗУ). Можно также собирать базы в памяти, пока объём ОЗУ позволяет это делать. При исчерпании ёмкости ОЗУ такая частичная (локальная) база сохраняется на диск, и в ОЗУ начинается сбор новой локальной базы.
Исследования показали, что создание и последующее объединение нескольких локальных баз оказывается гораздо более эффективным, чем сбор одной базы на диске.
Создание локальных баз разностей
Создание локальной базы начинается с получения базы кадра. Два соседних кадра сканируются окном, и для каждого положения окна вычисляется разность, которая заносится в базу разностей кадра.
При просмотре окно сдвигается на ![]() пикселов по ширине и на
пикселов по ширине и на ![]() пикселов по высоте. На Рис. 5 приведён пример кадра
пикселов по высоте. На Рис. 5 приведён пример кадра ![]() строк на
строк на ![]() столбцов, просмотр выполняется с помощью
квадратного окна
столбцов, просмотр выполняется с помощью
квадратного окна ![]() .
Тонкими линиями выделены отдельные пикселы, толстыми линиями показаны границы
окна, цифры внутри окна – порядковый номер при просмотре.
.
Тонкими линиями выделены отдельные пикселы, толстыми линиями показаны границы
окна, цифры внутри окна – порядковый номер при просмотре.

Рис. 5. Сканирование кадра окном 5*5
|
Рис. 6. Кадр i |
Рис. 7. Кадр i+1 |


После сканирования окном кадров ![]() (Рис. 6) и
(Рис. 6) и ![]() (Рис. 7) получается база разностей кадра,
представленная в таблице 1.
(Рис. 7) получается база разностей кадра,
представленная в таблице 1.
Таблица 1 База разностей кадра
|
Номер окна |
Разность |
Количество |
|
1 |
0 |
1 |
|
2 |
0 |
1 |
|
3 |
0 |
1 |
|
4 |
Р4 |
1 |
|
5 |
Р5 |
1 |
|
6 |
Р6 |
1 |
|
7 |
0 |
1 |
|
... |
0 |
1 |
|
13 |
Р13 |
1 |
|
14 |
Р14 |
1 |
|
15 |
Р15 |
1 |
|
16 |
0 |
1 |
|
... |
0 |
1 |
|
54 |
0 |
1 |
Полученная база сортируется алгоритмом быстрой сортировки [2] и уплотняется. Т.е. 48 нулевых разностей будут объединены в 1 запись. Уплотнённая база будет выглядеть следующим образом:
Таблица 2 Уплотнённая база разностей кадра
|
Разность |
Количество |
|
0 |
48 |
|
Р4 |
1 |
|
Р5 |
1 |
|
Р6 |
1 |
|
Р13 |
1 |
|
Р14 |
1 |
|
Р15 |
1 |
Уже уплотнённая база разностей кадра добавляется к локальной базе разностей. Т.е. база разностей состоит из уплотнённых баз, полученных для рассмотренных ранее кадров.
Описанный процесс повторяется до тех пор, пока в локальной базе есть место. Когда место подходит к концу, локальная база упорядочивается и уплотняется. В таком виде она записывается на диск, и начинается процесс сбора новой локальной базы. Наглядно этапы создания локальной базы разностей представлены на рис. 8.
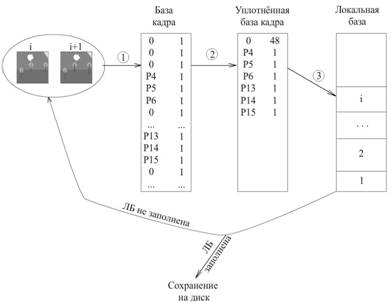
Рис. 8. Этапы создания локальной базы разностей
Слияние локальных баз разностей
Слияние локальных баз разностей – итоговый этап построения общей базы разностей по фильму. Перед началом данного этапа у нас имеется множество локальных баз, собранных на предыдущем этапе. На этапе слияния выполняется объединение этих баз в одну итоговую базу.
Слияние выполняется парами, т.е. на входе у нас имеется две
базы ![]() ,
наша задача объединить их в итоговую базу
,
наша задача объединить их в итоговую базу ![]() .
Рассмотрим алгоритм объединения[1][2].
.
Рассмотрим алгоритм объединения[1][2].
Введём
дополнительные параметры: флаги ![]() ,
значение 1 в этих переменных указывает, что база доступна для чтения. В
начальный момент
,
значение 1 в этих переменных указывает, что база доступна для чтения. В
начальный момент ![]() .
Пока не достигнут конец хотя бы одной базы выполняется чтение разностей в
переменные
.
Пока не достигнут конец хотя бы одной базы выполняется чтение разностей в
переменные ![]() и
и ![]() (чтение выполняется с учётом значений
(чтение выполняется с учётом значений ![]() ).
Далее возможно три варианта:
).
Далее возможно три варианта:
·
![]() , тогда в итоговую базу
, тогда в итоговую базу ![]() записывается
записывается ![]() , а флаги получают следующие
значения:
, а флаги получают следующие
значения: ![]()
·
![]() , тогда в итоговую базу
, тогда в итоговую базу ![]() записывается
записывается ![]() (при этом в счётчик записывается суммарное
количество этих разностей в
(при этом в счётчик записывается суммарное
количество этих разностей в ![]() ), а флаги принимают следующие
значения
), а флаги принимают следующие
значения ![]()
·
![]() , тогда в итоговую базу
, тогда в итоговую базу ![]() записывается
записывается ![]() , а флаги получают следующие
значения:
, а флаги получают следующие
значения: ![]()
После того, как одна из баз исчерпалась, нам необходимо
убедиться в том, что разности ![]() и
и ![]() (считанные перед исчерпанием базы) записаны в
итоговую базу, а потом скопировать остаток той базы, которая не исчерпалась в
(считанные перед исчерпанием базы) записаны в
итоговую базу, а потом скопировать остаток той базы, которая не исчерпалась в ![]() .
На этом алгоритм слияния заканчивается.
.
На этом алгоритм слияния заканчивается.
Остаётся
решить только один вопрос о порядке слияний. Договоримся, что базу, полученную
на основе кадра ![]() ,
будем называть
,
будем называть ![]() .
Проще всего реализовать следующую стратегию слияний: слить
.
Проще всего реализовать следующую стратегию слияний: слить ![]() с
с ![]() ,
полученную базу слить с
,
полученную базу слить с ![]() ,
полученную базу слить с
,
полученную базу слить с ![]() и т.д. Эта стратегию показана на рис. 9:
и т.д. Эта стратегию показана на рис. 9:
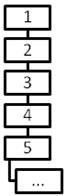
Рис. 9.
"Простой" порядок слияний
Однако,
предложенная стратегия недостаточно эффективна. Итоговый этап слияния – это
копирование остатка той базы, которая не исчерпалась. Очевидно, что с каждой
итерацией этот остаток будет только увеличиваться, т.е. количество бесполезных
копирований будет постоянно расти, а стоимость дисковых операций весьма высока.
Гораздо эффективнее оказывается следующая стратегия: слить ![]() с
с ![]() (итоговую базу назвать
(итоговую базу назвать ![]() ),
слить
),
слить ![]() с
с ![]() (итоговую базу назвать
(итоговую базу назвать ![]() ),
…, слить
),
…, слить ![]() с
с ![]() (итоговую базу назвать
(итоговую базу назвать ![]() )[3].
Потом слить полученные базы между собой и продолжать такие слияния далее, пока
не останется одна база. Таким алгоритмом слияния мы добиваемся того, что
сливаются базы примерно одного размера, т.е. количество бесполезных копирований
уменьшается. Эта стратегия показана на рис. 10:
)[3].
Потом слить полученные базы между собой и продолжать такие слияния далее, пока
не останется одна база. Таким алгоритмом слияния мы добиваемся того, что
сливаются базы примерно одного размера, т.е. количество бесполезных копирований
уменьшается. Эта стратегия показана на рис. 10:
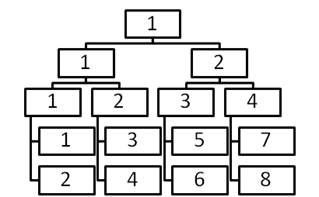
Рис. 10. Эффективный
порядок слияний
После выполнения этапа слияний, база разностей полностью сформирована и пригодна для дальнейшей обработки.
Заключение
В статье описан разработанный авторами алгоритм, позволяющий собрать базу элементов для эффективного сжатия видеопотока без потерь.
В данной работе не рассматривается вопрос выбора оптимальной конфигурации окна, хотя, проведённые авторами исследования показывают, что правильный выбор окна сканирования позволяет повысить степень сжатия в 4 и более раза.
Литература
1. Кнут Д.Э., Искусство программирования, том 3: сортировка и поиск, -М.: ООО "И.Д. Вильямс", 2007. -832с.
2. Кормен Т., Лейзерсон Ч., Ривест Р., Штайн К., Алгоритмы построение и анализ, -М.: Издательский дом "Вильямс", 2010. -1296 с.
3. Вирт Н., Алгоритмы и структуры данных. Новая версия для Оберона +CD. -М.: ДМК Пресс, 2010. -272 с.: ил.