BC/NW 2012; №2 (21):2.1
ядро
ПАРАЛЛЕЛЬНОЙ ПОТОКОВОЙ ВЫЧИСЛИТЕЛЬНОЙ СИСТЕМЫ С НЕСКОЛЬКИми МОДУЛями
АССОЦИАТИВНОЙ ПАМЯТИ
Цветков В.В.
Структура вычислительного конвейера ядра параллельной
потоковой вычислительной системы (ППВС) [1] представляет собой циклический
конвейер, включающий следующие блоки: модуль ассоциативной памяти (МАП), модуль
исполнительного устройства (ИУ), модуль хеширования (ХЕШ), буфер токенов (БТ), буфер пакетов (БП) и
внутренний коммутатор (ВК), осуществляющий связь ядра с коммуникационной
системой в многоядерном варианте параллельной системы.
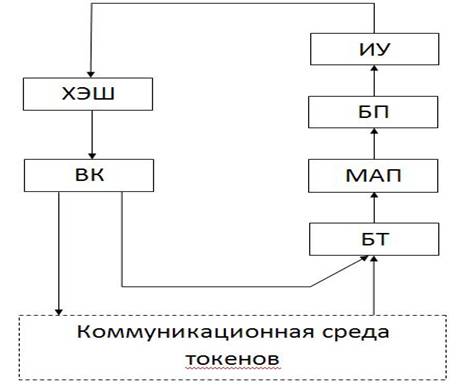
Рис.1 Структура ядра ППВС
При высоком уровне параллелизма в исполняемой
потоковой программе время выполнения программы определяется устройством с
наименьшей пропускной способностью [2]. В дальнейшем будем называть это
устройство «критическим устройством».
Модули ассоциативной памяти в параллельной потоковой вычислительной
системе (ППВС) при практической реализации системы могут ограничивать ее
производительность. Поэтому, представляется целесообразным рассмотреть
возможность организации параллельной работы модулей ассоциативной памяти на
уровне отдельного ядра ППВС.
Если построить зависимость времени выполнения
программы от времени выполнения операции в АП (tАП), то зависимость эта
будет представлена в виде линии, состоящей из горизонтального и наклонного
участков. Наклонный участок соответствует случаю, когда критическим устройством
конвейера является модуль АП. Время выполнения программы на этом участке
пропорционально времени выполнения операции в АП. Угол наклона прямой
определяется количеством токенов. Время выполнения программы на горизонтальном
участке не зависит от производительности АП и определяется устройством
конвейера, которое на этом интервале значений tАП является критическим.
Если время выполнения программы на этом участке определяется
ИУ, то, увеличивая производительность ИУ путем подключения дополнительных
параллельно работающих ИУ [3], мы можем
добиться сбалансированной работы блоков ИУ и БТ. Дальнейшее повышение производительности ИУ не приводит к
снижению времени выполнения программы, поскольку производительность конвейера будет
определяться производительностью БТ, который становится критическим устройством
в конвейере. Зависимость времени выполнения программы от времени выполнения
операции в АП при сбалансированной работе ИУ и БТ представлена на рис. 2.
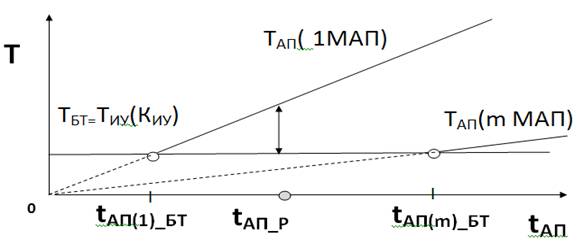
Рис. 2. Зависимость
времени выполнения программы от tАП
Время работы БТ обозначено на рисунке как ТБТ.
Время работы ИУ обозначено как ТИУ, а время работы МАП как ТАП.
Эти времена определяются интегральным
временем активной работы соответствующего модуля конвейера. Алгоритмы
вычисления времени активной работы каждого блока конвейера соответствуют
алгоритмам, принятым в блочно-регистровой модели ППВС [4]. Значение tАП(1)_БТ можно вычислить из условия ТАП = ТБТ.
Значение tАП(m)_БТ определяется из условия
равенства ТАП и ТБТ, когда в ядре работают m
модулей АП.
Добиться снижения времени выполнения программы
при значениях tАП, превышающих tАП(1)_БТ, можно если в ядре
организовать параллельную работу нескольких модулей АП. На рис. 2 увеличение
количества модулей АП соответствует уменьшению угла наклона прямой линии.
Обозначим через К коэффициент ускорения выполнения программы при подключении в
ядре m дополнительных модулей АП. Аналитически зависимость
К от параметра tАП можно описать на трех участках по
горизонтальной оси с интервалами изменения tАП : (0 ÷ tАП(1)_БТ ), (tАП(1)_БТ ÷ tАП(m)_БТ ) и (tАП(m)_БТ ÷ ∞). На первом
интервале ускорение работы ядра отсутствует, К=1. На интервале изменения tАП от tАП(1)_БТ до tАП(m)_БТ коэффициент ускорения
линейно растет с увеличением tАП и определяется выражением: К=ТАП/ТБТ.
В конце интервала, в точке tАП(m)_БТ , коэффициент ускорения
достигает своего максимального значения (КMAX), которое затем
остается неизменным при дальнейшем увеличении tАП.
При организации в ядре параллельной работы нескольких
модулей АП распределение токенов по модулям АП в ядре выполнялось аналогично
распределению токенов по ядрам многоядерной конфигурации системы, а именно по хеш-адресам,
сформированным в результате хеширования ключа токена.
Распределение токенов по модулям АП в ядре
выполняется с помощью коммутатора КМАП. Рассмотрим организацию формирования хеш-адресов
при организации многоядерной системы, включающей N ядер, в каждом из
которых может параллельно работать m модулей АП. Блок
хеширования в ядре вырабатывает m*N
хеш-адресов в диапазоне от 0 до m*N-1.
Через n обозначим порядковый номер ядра. Диапазон изменения n от
0 до N-1. Внутренний коммутатор каждого n-го ядра настроен таким
образом, что на коммутатор КМАП попадают токены, хеш-адреса которых заключены в
пределах от n*m до m*(n+1)-1.
Токены с другими хеш-адресами направляются в коммуникационную среду системы.
Коммуникационная система возвращает в ядро с номером n токены с хеш-адресами от
n*m до m*(n+1)-1.
Работа отдельного ядра, поддерживающего
параллельную работу нескольких модулей АП,
а также работа многоядерной системы построенной на базе таких ядер, была
промоделирована на блочно–регистровой модели системы при выполнении программы пространственного
фильтра 3х3 элемента на изображении размером 32х32 пикселя. Были использованы
два варианта программы с различными
алгоритмами работы (f1 и f2). На результаты
моделирования существенное влияние оказало различие в неравномерности
распределения токенов по модулям АП при исполнении эти двух вариантов программ
с одним и тем же алгоритмом хеширования.
Результаты моделирования выполнения программы f_1
на одном ядре приведены на рис.3.
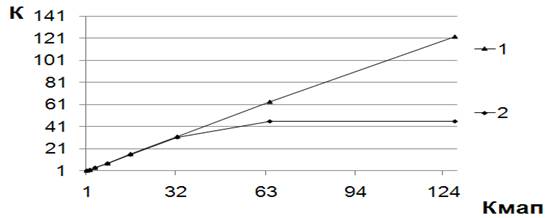
Рис. 3. Зависимость коэффициента ускорения от
количества МАП в ядре для программы f_1
Зависимость (1) представляет случай, когда буфер
токенов не ограничивает производительность конвейера на всем диапазоне
изменения значения параметра tАП. В этом случае
зависимость коэффициента ускорения от количества модулей АП остается
практически линейной на всем диапазоне изменения количества модулей АП в ядре.
Зависимость (2) получена при работе ядра в режиме ограничения времени выполнения
программы буфером токенов. Как видно из рисунка, при определенном количестве
модулей АП рост коэффициента ускорения прекращается, и зависимость выходит на
горизонтальный участок, соответствующий максимальному значению КMAX.
Была создана конфигурация многоядерной системы,
включающая 16 ядер, которые поддерживают работу в каждом ядре до 8 модулей АП и 8 модулей ИУ. Результаты моделирования и
аналитических расчетов времени выполнения программ f_1 и f_2
при различном количестве модулей АП (при значениях tАП превышающих tАП(m)_БТ)
в ядре приведены на рис.4 и рис.5. Результаты моделирования отмечены маркером
квадратной формы. При моделировании предполагалось, что коммуникационная среда
не ограничивает пропускную способность конвейера. Если работа конвейера
ограничивается пропускной способностью коммуникационной среды, то в качестве
критического устройства необходимо рассматривать не буфер токенов, а
критическое устройство в коммуникационной среде.
Зависимость коэффициента ускорения от количества
ядер в системе при различном количестве модулей АП в каждом ядре
экстраполировалась выражением, аналогичным выражению, описывающему закон Амдала:
![]() (1)
(1)
где
в качестве переменной, задающей количество
параллельно работающих модулей АП, использовалось произведение
количества ядер и количества модулей АП в каждом ядре. При этом, для каждой
программы устанавливалось значение параметра α, определенное по
результатам моделирования выполнения этой программы на одном ядре. Для
программы f_1, для которой характерно более равномерное распределение
токенов по модулям АП, значение параметра α составляет 0,003, а для
программы f_2 параметр α=0,017.
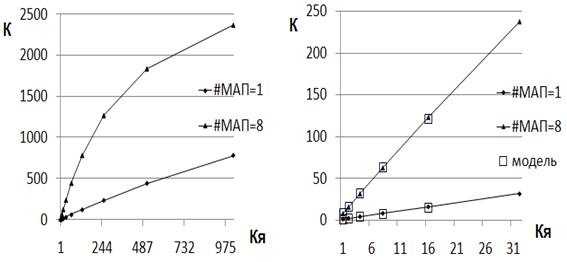
Рис. 4. Зависимости коэффициента ускорения от
количества ядер при различном количестве МАП в ядре для программы f_1
(α=0,003). Верхняя зависимость на обоих рисунках получена аналитически при
8 модулях АП в ядре, нижняя зависимость - при 1 модуле АП в ядре. Прямоугольным
маркером на правом рисунке отмечены значения К, полученные при моделировании.
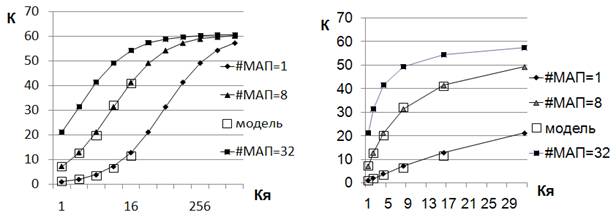
Рис. 5. Зависимости коэффициента ускорения от
количества ядер при различном количестве МАП в ядре для программы f_2
(α=0,017). Прямоугольным маркером отмечены значения К, полученные при
моделировании.
Результаты, приведенные на рисунках, показывают
хорошее совпадение результатов моделирования и расчетов. При установленных параметрах
устройств, при 8 модулях АП для программы f_1 достигается примерно
6-ти кратное увеличение коэффициента ускорения системы по сравнению с
конфигурацией ядра с 1 модулем АП, что позволяет в многоядерной конфигурации
системы достигнуть требуемого значения коэффициента ускорения при меньшем
количестве ядер.
Время
выполнения программы в многоядерной конфигурации системы определяется
произведением активного времени работы АП и коэффициента ускорения, определяемого
выражением (1). Поскольку ТАП, и параметры m и α в выражении
для коэффициента ускорения могут быть определены на этапе моделирования работы одного
ядра, то время выполнения программы на многоядерной конфигурации системы может
быть аналитически определено, используя только результаты моделирования
выполнения программы на простой одноядерной конфигурации.
Литература
1. А.Л. Стемпковский, Н.Н.
Левченко, А.С. Окунев, В.В. Цветков Параллельная потоковая вычислительная
система – дальнейшее развитие архитектуры и структурной организации
вычислительной системы с автоматическим распределением ресурсов. Информационные технологии №10, с. 2-7, 2008г.
2.
Цветков В.В.
Параллельная потоковая вычислительная система: анализ и моделирование работы
вычислительного конвейера. Труды ХVII Международной научно-технической
конференции «Информационные средства и технологии», Москва, Издательский дом
МЭИ, Т. 2, c.
242-248, 2009г.
3.
Цветков В.В., Змеев Д.Н. Параллельная работа
исполнительных устройств в ядре ППВС. Труды Третьей Всероссийской научной
конференции MCO
2009, Москва, с. 71-76, 2009г.
4. Левченко Н.Н., Окунев
А.С., Змеев Д.Н. Расширение возможностей поведенческой блочно-регистровой
модели параллельной потоковой вычислительной системы. Материалы Пятой
Международной молодежной научно-технической конференции «Высокопроизводительные
вычислительные системы (ВПВС 2008)», Таганрог, Россия, с. 371 – 374, 2008г.