BC/NW 2012; №2 (21):4.5
УСКОРЕНИЕ НАУЧНЫХ И
ИНЖЕНЕРНЫХ РАСЧЁТОВ ПУТЕМ ИСПОЛЬЗОВАНИЯ ВОЗМОЖНОСТЕЙ ГРАФИЧЕСКИХ ПРОЦЕССОРОВ
ВИДЕОАДАПТЕРОВ NVIDIA
Филатов А.В.
Ещё десять и более лет назад, производительность средств вычислительной техники увеличивалась во многом благодаря постоянному усовершенствованию технологии и повышению тактовой частоты. После достижения в начале 21-го века некоторого технологического предела, стали активно развиваться альтернативные способы повышения производительности вычислений. Широкое распространение стали получать мощные кластерные вычислительные системы, а большинству пользователей стали доступны многоядерные микропроцессоры, позволяющие выполнять вычисления одновременно несколькими параллельными потоками.
В данном докладе пойдет речь об одном новом, очень интересном, доступном большинству пользователей и активно развивающимся способе повышения производительности вычислений – использовании вычислительных возможностей графических процессоров. Графические процессоры являются основной составной частью видеоадаптеров (в просторечии – видеокарт) имеющихся почти в каждой современной вычислительной системе. Поскольку обработка современного видео (фильмы, игры и пр.) является довольно объёмным и непростым вычислительным процессом, разработчики видеоадаптеров вынуждены были снабдить их довольно мощными вычислительными устройствами. Изначально эти устройства, т.е. графические процессоры, были ориентированы только на выполнение некоторых специфических для графики операций. Однако в дальнейшем их возможности значительно расширились, а также появилась возможность их программировать. В результате, обычный пользователь может использовать имеющийся в его компьютере видеоадаптер в качестве сопроцессора для выполнения вычислений параллельно с основным центральным процессором (CPU). Правда следует заметить, что одна трудность всё же оставалась. Программирование графических процессоров (GPU) сильно отличается от программирования CPU. Чтобы устранить эту трудность, одна из фирм разработчиков видеоадаптеров – компания NVIDIA, создала и внедрила в свою продукцию (начиная с видеоадаптера NVIDIA GeForce 8800) специальный аппаратно-программный комплекс CUDA (Compute Unified Device Architecture). Этот комплекс позволяет программировать GPU привычным способом, как если бы программа писалась для CPU. С точки зрения программиста-пользователя, CUDA представляет собой надстройку над языками C и C++, из-за чего процесс освоения основ программирования GPU уже не представляет большой трудности.
Как устроен графический процессор NVIDIA? Он состоит из нескольких (их может быть 2, 4, 8, 10 и более) потоковых мультипроцессоров SMP. Каждый потоковый мультипроцессор содержит восемь ядер – потоковых процессоров SP. Каждый потоковый процессор может выполнять один или несколько вычислительных потоков. Если потоков на одном потоковом процессоре несколько, то они выполняются в режиме разделения времени, но при этом переключение между ними происходит очень быстро. Важной особенностью является то, что все восемь SP одного SMP работают под управлением одного управляющего модуля, т.е. в режиме SIMD (один поток команд – множество потоков данных). Важной особенностью GPU является то, что одиночный вычислительный поток на GPU слабее потока CPU, однако на всех SMP GPU может одновременно выполняться несколько сотен, а то и тысячи потоков. Во многих научных и инженерных расчётах можно разбить вычисления на такое количество потоков и именно это позволяет ускорить их выполнение. Ещё одной важной особенностью является простота и быстрота взаимодействия потоков. Взаимодействие параллельных потоков всегда было узким местом в эффективности параллельных вычислений. GPU NVIDIA содержит шесть видов памяти. Среди них, кроме классической ёмкой, но медленной глобальной (для всех SMP) памяти, в каждом SMP имеются небольшие, но быстродействующие модули так называемой shared памяти. Используя эту память, можно организовать достаточно эффективное взаимодействие между вычислительными потоками GPU.
С точки зрения пользователя-программиста дело обстоит следующим образом. Создаётся как бы классическая программа для основного процессора CPU. Периодически, по мере необходимости происходит вызов подпрограмм (так называемых функций-ядер), которые выполняются на GPU. Перед каждым вызовом функции-ядра, с помощью встроенных средств CUDA осуществляется запись (копирование) в память GPU исходных данных, а после выполнения функции-ядра из памяти GPU в память CPU копируются результаты. Сами функции-ядра пишутся на языках C и C++, и отличаются от обычных программ только некоторыми вставками расширений CUDA и, конечно же, создаются с учётом особенностей их выполнения на GPU. Последним важным моментом является то, что исходные тексты программы для CPU и функций-ядер для GPU представляют собой единый программный текст, и даже могут быть записаны в одном файле. При компиляции специальный диспетчер CUDA анализирует исходный текст и вызывает для компиляции разные компиляторы. Один компилятор транслирует свою часть программного текста в код для CPU, а другой программный текст функций-ядер в код для GPU.
Теперь рассмотрим результаты реального эксперимента. Для его проведения был использован процессор INTEL Core 2 Duo – CPU и графический процессор видеоадаптера NVIDIA GeForce 450 – GPU. Сразу необходимо сказать, что выбранный видеоадаптер является не только устаревшей моделью, но и довольно слабой. Использование более мощного видеоадаптера должно дать гораздо лучшие результаты.
Многих расчётные задачи требуют решения системы линейных уравнений. Существует несколько методов их решения. Для примера, автором был выбран метод – Гаусса-Зейделя. Метод Гаусса-Зейделя итерационный. Для эксперимента была выбраны системы из 64, 256 и 1024 уравнений.
На рис 1. приведен график зависимости коэффициента ускорения вычислений на GPU по сравнению с CPU от размера системы уравнений. Нетрудно заметить, что при малом числе уравнений в системе эффективнее использовать CPU, а при большом – GPU.
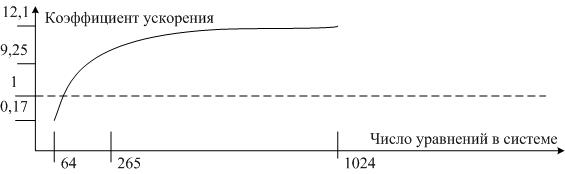
Рис. 1. Зависимость коэффициента ускорения вычислений на GPU по сравнению с CPU от размера системы уравнений
В заключение необходимо отметить, что, получив неплохие результаты, компания NVIDIA занялась разработкой специализированных мощных ускорителей, таких как Tesla, которые в основе своей имеют архитектуру обычного видеоадаптера, однако построены специально для эффективного проведения научных и инженерных расчётов. Эти ускорители находят всё большее применение. Стало популярно устанавливать их в качестве сопроцессоров в узлы кластерных вычислительных систем. Такими ускорителями, в частности, снабжены узлы суперкомпьютера «Ломоносов» (самый высокопроизводительный в России и СНГ) в МГУ и новейший суперкомпьютер Cray XK6. Для потребителей среднего уровня предлагаются серверы с установленными в них несколькими ускорителями с GPU от NVIDIA. Важно также отметить, что разработкой подобных ускорителей систем занялись многие другие известные фирмы.
Исходя из вышесказанного, автором данного доклада весной 2012 года был поставлен и читается специальный курс лекций по программированию и применению GPU в научных и инженерных расчётах для студентов трёх групп АВТИ кафедры ВМСиС. Проводятся лабораторные занятия. Занятия дополняют ранее приобретённые ими навыки по программированию и использованию кластерных вычислительных систем.
Литература
1. Сандерс Дж., Кэндрот Э., Технология CUDA в примерах: Введение в программирование графических процессоров: Пер. с англ. Слинкина А.А., научный редактор Боресков А.В. – М.: ДМК Пресс, 2011. – 232с.: ил.
2. Боресков А.В., Харламов А.А., Основы работы с технологией CUDA. – М.: ДМК Пресс, 2011. – 232 с.: ил.