BC/NW 2013, №2 (23):10.2
КЛАССИФИКАЦИЯ РЕЧЕВЫХ ОБРАЗОВ НА ОСНОВЕ АНАЛИЗА РАСПРЕДЕЛЕНИЙ ИХ ЛОКАЛЬНЫХ ЭКСТРЕМУМОВ
Огнев И.В., Огнев А.И., Парамонов П.А.
(ФГБОУ ВПО «Национальный исследовательский университет «МЭИ», Москва, Россия)
Первым
этапом работы любой системы распознавания речи является выделение признаков
входного сигнала. При этом преследуются две цели: во-первых, повышение качества
распознавания – получившаяся выжимка, называемая вектором признаков,
содержит такие характеристики речи, которые позволяют провести классификацию
речевых образов; во-вторых, благодаря отбрасыванию незначащей информации
происходит сжатие данных [1]. Существуют различные подходы к составлению
вектора признаков [1, 2]: нахождение спектральных характеристик сигнала
(мел-кепстральных коэффициентов, коэффициентов линейного предсказания и др.)
либо сбор данных во временной области (такие как распределение интервалов
прохода сигнала через ноль [3]). Наибольшее распространение получил первый
подход, в основе которого лежит преобразование Фурье. Тем не менее, он же имеет
и нерешенные проблемы: его вычислительная сложность не ниже![]() , а получаемые признаки
зависят от параметров речевого тракта (дикторозависимые).
, а получаемые признаки
зависят от параметров речевого тракта (дикторозависимые).
В данной работе предлагается принципиально новый подход к извлечению признаков, использующий только представление сигнала во временной области. Получающийся вектор признаков представляет собой плотность распределения значений экстремумов входного сигнала. Работоспособность подхода была проверена на примере классификации гласных фонем русского языка с использованием нейронных сетей. Помимо собственно возможности находить признаки, годные для распознавания, новый подход обладает низкой по сравнению с Фурье-анализом сложностью – линейной.
Рассмотрим
участок речевого сигнала, изображенный на рисунке 1. Отсчеты под номерами 1, 4,
5, 9, 10, 11 являются экстремумами. Обозначим через ![]() общее число экстремумов на
участке. Максимально возможное значение экстремума
общее число экстремумов на
участке. Максимально возможное значение экстремума ![]() (и, вообще говоря, любого
отсчета) определяется разрядностью отсчета
(и, вообще говоря, любого
отсчета) определяется разрядностью отсчета ![]() :
:
![]()
Например,
в данной работе все речевые образы были оцифрованы с ![]() , а
, а ![]() . Обозначим через
. Обозначим через ![]()
![]() -й интервал значений
экстремумов, так что ширина интервалов равна
-й интервал значений
экстремумов, так что ширина интервалов равна ![]() :
:
![]()
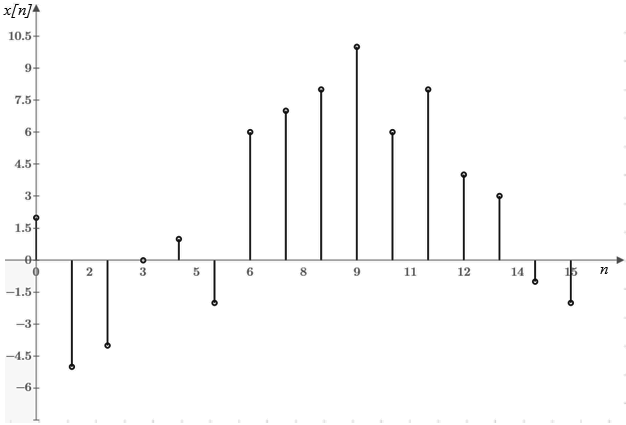
Рис. 1. Пример участка дискретного речевого сигнала с шестью экстремумами
Теперь
введем величину ![]() ,
обозначающую количество экстремумов, попавших в интервал
,
обозначающую количество экстремумов, попавших в интервал ![]() :
:
![]()
Функция
![]() определяет,
попал ли экстремум
определяет,
попал ли экстремум ![]() в
интервал
в
интервал ![]() :
:
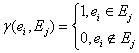
Наконец,
обозначим ![]() долю
экстремумов, попавших в интервал
долю
экстремумов, попавших в интервал ![]() , от общего числа
, от общего числа ![]() :
:
![]()
Таким
образом, для каждого речевого образа можно построить вектор распределения
экстремумов ![]() ,
в котором
,
в котором ![]() –
это вероятность того, что значение экстремума попадет в интервал
–
это вероятность того, что значение экстремума попадет в интервал ![]() , при этом
, при этом ![]() . Получившийся вектор
. Получившийся вектор
![]() и есть
вектор признаков, который можно подавать на распознаватель.
и есть
вектор признаков, который можно подавать на распознаватель.
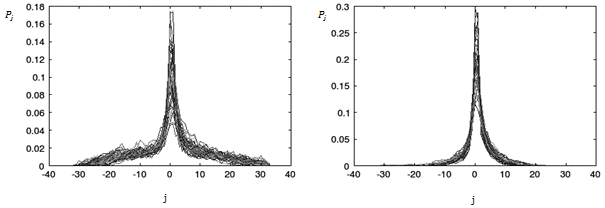
На рисунке 2 приведены распределения экстремумов для шести гласных звуков русского языка. При этом на одном графике наложены пятьдесят распределений для фонем одного типа. Чтобы проверить пригодность такого признака для распознавания, был проведен следующий эксперимент. Многослойная полносвязная нейронная сеть была обучена на обучающей выборке, включающей двадцать образов (распределений) каждого класса (т.е. совокупная обучающая выборка составляла 120 образов, по двадцать для шести фонем). Затем эта нейронная сеть использовалась для распознавания трехсот образов – по пятьдесят для каждого из шести классов. Параметры нейронной сети следующие: входной слой включает шестьдесят шесть нейронов, скрытый слой – тридцать нейронов, выходной слой – шесть нейронов. Результат оценивался как доля верных ответов сети (точность распознавания) и ошибочных (ошибка распознавания). Средняя ошибка распознавания достигла 20%, а точность – 80%. Подробные результаты эксперимента приведены в таблице 1.
Таблица 1.
Результаты применения распределения экстремумов в качестве вектора признаков для распознавания гласных фонем русского языка.
|
Фонема |
Ошибка |
Точность |
|
/а/ |
14% |
86% |
|
/и/ |
28% |
72% |
|
/о/ |
20% |
80% |
|
/у/ |
22% |
78% |
|
/э/ |
10% |
90% |
|
/ы/ |
24% |
76% |
|
Итого |
20% |
80% |
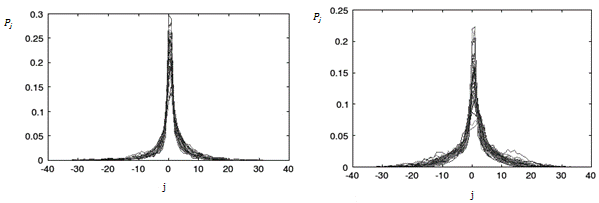
a) б)
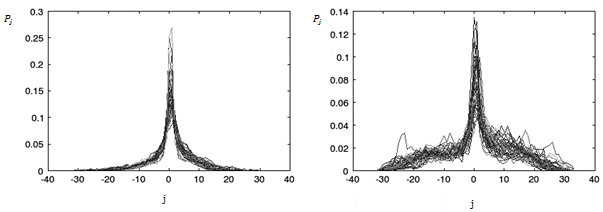
в) г)
д) е)
Рис. 2. Распределения экстремумов для шести гласных фонем русского языка, по пятьдесят примеров для каждого звука
В работе предложен принципиально новый характеристический признак речевого сигнала, основанный на распределении его экстремумов. Для шести гласных фонем русского языка с использованием нейронной сети были проведены эксперименты, подтверждающие пригодность этого признака для распознавания. Точность распознавания достигала 80%, которая, хоть и уступает существующим подходам на базе частотных характеристик, все же показывает перспективность данного направления. Кроме того, предложенный подход привлекает низкой вычислительной сложностью. В настоящее время авторы работают над методикой отбора локальных экстремумов речевого сигнала, существенных для распознавания, так как многие локальные экстремумы, связанные с малоамплитудными колебаниями, отражают индивидуальные особенности голоса, а не значение образа. Исследуются также алгоритмы разделения образов, не связанные с классификаторами, основанными на алгоритмах нейронных сетей.
Работа выполнена при содействии Совета по грантам президента РФ для поддержки молодых ученых (грант МК-3281.2013.9)
Литература
1. Rabiner L., Fundamentals of Speech Recognition, Prentice-Hall Inc., 1993. – 507 стр.
2. Huang, Xuedong, Alex Acero, Spoken language processing: a guide, theory, algorithm, and system development, Prentice-Hall Inc., 2001. – 981 стр.
3. R.K. Sunil Kumar, V.L. Lajish, Phoneme recognition using zerocrossing interval distribution of speech patterns and ANN, International Journal of Speech Technology, том 16, Springer, 2013. – с. 125-131.