BC/NW 2013, №2 (23):2.1
РАЗРАБОТКА МЕТОДОВ И ПРОГРАММНЫХ СРЕДСТВ ФОРМИРОВАНИЯ МЕТАДАННЫХ для ИНФОРМАЦИОННЫх ИНТЕРНЕТ-РЕСУРСОВ
Варшавский П.Р., Грачева О.В.
(ФГБОУ ВПО «Национальный исследовательский университет «МЭИ», Москва, Россия)
В настоящее время сеть Интернет содержит огромное количество различных Интернет-ресурсов (сайтов), которое увеличивается с каждым днем. По данным проведенного компанией Netcraft в декабре 2012 года исследования в сети Интернет уже насчитывается около 633 млн. сайтов. Такое положение дел неизбежно приводит к необходимости решать актуальную на данный момент задачу, связанную с организацией эффективного поиска информации (Интернет-ресурсов) в сети Интернет и обеспечением релевантности результатов поиска пользовательскому запросу. Для решения указанной задачи чаще всего используются специальные поисковые системы, такие как Google, Yahoo, Yandex и другие. Функционирование таких систем включает два основных процесса: индексирование Интернет-ресурсов (сбор сведений об информационных ресурсах и последующее их обновление); поиск по запросам пользователей.
Несмотря на постоянное совершенствование технологий поиска в Интернет, индексирование Интернет-ресурсов затруднено в силу сложности анализа и выделения дополнительных, вспомогательных данных (метаданных). Эти трудности обусловлены в основном отсутствием единого стандарта оформления метаданных и нежеланием разработчиков сайтов указывать метаданные по разрабатываемым Интернет-ресурсам и следовать какому-либо стандарту.
Кроме того, многие разработчики, занимающиеся SEO оптимизацией, умышленно вводят некорректные метаданные для повышения популярности своего ресурса, его продвижения в поисковых системах Интернет. Решить проблему отчасти помогают методы полнотекстового, семантического и статистического анализа. Эти методы позволяют на основе содержимого (контента) веб-страницы определить тематику данного ресурса и выявить метаданные. Таким образом, учет метаданных в процессе поиска позволяет повысить релевантность результатов, выдаваемых поисковыми системами Интернет. Поэтому данное направление является очень актуальным и востребованным как для пользователей, так и для разработчиков поисковых систем.
Semantic Web (семантическая паутина) — это надстройка над сетью Интернет, которая призвана сделать размещенную в ней информацию более понятной для компьютеров [1]. Машинная обработка в Semantic Web возможна благодаря двум ее важнейшим особенностям:
1) Повсеместное использование унифицированных идентификаторов ресурсов (URI). В Semantic Web URI используются для именования объектов, то есть каждый URI однозначно называет некоторый объект. Свои URI в семантической паутине есть не только у страниц, но и у объектов реального мира (людей, городов, художественных произведений и так далее) и даже у абстрактных понятий (например, у свойств «имя», «должность», «цвет»).
2) Использование семантических сетей, онтологий и метаданных. Современные методы автоматической обработки данных, доступных в Интернете, как правило, основаны на частотном и лексическом анализе текстового содержимого, которое, прежде всего, предназначено для восприятия человеком. В Semantic Web вместо этого используется стандарт RDF, описывающий семантические сети (графы), в которых узлы и дуги имеют URI. Утверждения, кодируемые с помощью RDF, в дальнейшем можно интерпретировать с помощью онтологий, созданных по стандартам RDF Schema и OWL, чтобы получать из них логические заключения.
Метаданные (metadata) — это информация о документе, понимаемая компьютером, т.е. обладающая свойством внутренней интерпретируемости. В общем случае метаданные представляют собой информацию, характеризующую какую-либо другую информацию. Экземпляр метаданных для Интернет-ресурса выступает в качестве описания этого ресурса.
Зачастую метаданные для html-страниц создаются вручную. Такие метаданные имеют большую ценность, поскольку гарантируется осмысленность. Однако у этого метода создания метаданных есть и существенные недостатки:
• сложность обработки большого количества информационных ресурсов;
• необходимость своевременного обновления метаданных при изменении данных ресурса.
Таким образом, целесообразно использовать автоматизированные инструментальные средства для создания метаданных.
Один из методов решения указанной задачи основывается на анализе структуры целевых документов и промежуточных гипертекстовых страниц, содержащих дополнительную информацию – ссылки и описания целевых документов.
Другой метод – сопоставление фразовых шаблонов. Он заключается в нахождении искомой информации посредством сопоставления текста информационного ресурса и фразовых шаблонов.
Еще один метод – статистический анализ документа. Суть данного метода заключается в том, чтобы определить признаки и характеристики (например, частоту использования определенных терминов), отражающие существенные стороны содержания документа [2].
В работе использовался статистический метод для определения ключевых слов информационного ресурса. Вычисление весовых коэффициентов ключевых слов проводилось по алгоритму, схема которого приведена на рис. 1.
Блок 1 служит для преобразования загруженного из интернета html-документа в модель DOM (Document Object Model) – объектную модель документа. Осуществляется выборка заголовков и текста на основе построенной DOM-модели.
Блок 2 выполняет разбиение содержимого заголовков и текстов на отдельные слова.
Блок 3 отвечает за удаление стоп-слов, таких как предлоги, местоимения, союзы и союзные слова, междометия, частицы, вводные слова, цифры, знаки препинания и т.п. Такие слова не несут самостоятельной смысловой нагрузки, поэтому их не следует учитывать при выделении ключевых слов.
Блок 4 предназначен для проведения операции стемминга для каждого слова, не являющегося стоп-словом.
Стемминг (стемматизация) – это процесс нахождения основы слова (стеммы) для заданного исходного слова, которая необязательно совпадает с корнем или с морфологической основой слова. Первый документ по этому вопросу был опубликован в 1968 году. Данный процесс применяется в поисковых системах для обобщения поискового запроса пользователя.
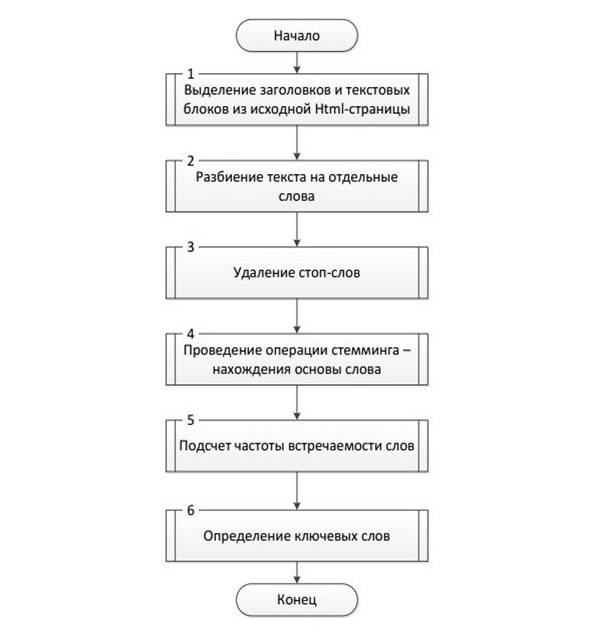
Рис. 1. Алгоритм нахождения ключевых слов
Одним из самых популярных алгоритмов стемминга является стеммер Портера, опубликованный Мартином Портером в 1980 году [3]. Оригинальная версия стеммера была предназначена для английского языка и была написана на языке BCPL. Впоследствии Портером был создан проект «Snowball» и, используя основную идею алгоритма, написаны стеммеры для распространенных индоевропейских языков, в том числе для русского.
В стеммере Портера не используются базы основ слов, и не проводится морфологический анализ. При обработке слово разделяется на две части: основу (стемму) и формообразующую морфему (суффикс, или аффикс) за счет последовательного применения ряда правил, заданных вручную на основе особенностей языка. Алгоритм работает быстро, однако не всегда безошибочно [4].
В данной работе алгоритм стемминга Портера был улучшен за счет увеличения базы суффиксов и окончаний в соответствии с таблицами основных окончаний и суффиксов русского языка [5].
Блок 5 служит для подсчета частоты встречаемости слов.
Блок 6 предназначен для определения ключевых слов на основе заданного порогового значения частоты встречаемости слова.
В ходе выполнения работы было разработано программное средство в среде .Net на языке C#, позволяющее проводить статистический анализ веб-страниц и выделять метаданные (ключевые слова). На основе полученных результатов можно выполнить проверку корректности метаданных, предоставленных разработчиком Интернет-ресурса, и добавить обнаруженные метаданные для уточнения тематики веб-страницы или сайта.
Работа выполнена при финансовой поддержке грантов РФФИ (№ 11-01-00140-а, № 12-07-00508-а)
Литература
1. Башмаков А.И., Башмаков И.А. Интеллектуальные информационные технологии: Учеб. пособие. – М.: Изд-во МГТУ им. Н.Э. Баумана, 2005.
2. Rajaraman Anand, Ullman Jeffrey D. Mining of Massive Datasets. Cambridge University Press, 2011.
3. Rijsbergen, C.J. Van, Robertson S.E., Porter M.F. New models in probabilistic information retrieval. London: British Library, 1980.
4. Manning Christopher D., Raghavan Prabhakar, Schütze Hinrich. Introduction to Information Retrieval. Cambridge University Press, 2008.
5.
Белоногов Г.Г., Калинин Ю.П., Хорошилов А.А. Компьютерная лингвистика и
перспективные информационные технологии.
– М.: Русский мир, 2004.