BC/NW №1 2014 №1 (24):6.1
Персонализация поиска: кластеризация Интернет-пользователей и Интернет-ресурсов
Зейн А.Н.
В статье рассмотрена проблема кластеризации Интернет-пользователей и Интернет-ресурсов с динамическими компонентами. Предложено 2 подхода для усовершенствования кластеризации Интернет-ресурсов и 1 подход для улучшения состояния кластеров. Рассмотрена и показана возможность улучшения динамического показателя «степень принадлежности» с помощью применения числовых коэффициентов, полученных как результат анализа содержания DOM-модели Интернет-ресурсов и с помощью специального DOM-фильтра для локализации и устранения динамических объектов. Показана возможность представления Интернет-пользователей и Интернет-ресурсов в качестве обобщённых векторов характеристик.
Введение
Средняя аудитория поисковой системы Яндекса составляет около 20000000 человек в сутки [1]. В течение суток эта поисковая система обрабатывает до 150000000 запросов, выдавая Интернет-пользователям (в дальнейшем ИП) более 10000000000000 ссылок на информационные Интернет-ресурсы (в дальнейшем ИР) [2]. К сожалению, фактом является то, что большинство найденных ресурсов не содержат информации, отвечающей поисковым интересам пользователей. Проблема поиска сильнее всего отражается для многозначных терминов, например : ягуар, муравейник, семья, лук, ручка, ключ, кран, киви и др.
Постановка задачи исследования
Классификация ИР с целью персонализации поиска, исходя из поисковой истории ИП. Предложенный подход может быть использован для решения проблемы многозначных терминов в поисковой системе.
1. Математическое описание объектов
Пусть X – множество наблюдаемых объектов (ИП
или ИР), xi – i-ый наблюдаемый объект, xi Î X. Если производится наблюдение за соcтоянием
объекта xi, то в произвольный момент времени
tk Î T можно сформировать его характеристический вектор:
xi(tk) = (xi,1(tk), …, xi,j(tk), …, xi,nof(V)(tk)), (1)
где xi,j(tk) – вес j-го термина из глобального словаря терминов V в момент времени tk, равный числу вхождений этого термина. Для ИП - это число вхождений j-ого термина в течении наблюдаемого периода, а для ИР - это число вхождений j-ого термина в тексте ИР; nof(V) – размер поискового вектора i-го объекта, равный числу слов в глобальном словаре терминов. Числовые координаты xi,j(tk), 1£j£nof(V), расположены в характеристическом векторе в том же лексикографическом порядке, что и термины в словаре V. Переход от вербального к числовому представлению происходит за счет позиционного кодировании терминов и подсчёта числа их вхождений.
2. Промежуточные результаты экспериментального исследования
После формирования
векторов характеристик (формула 1) для сравнения объектов воспользуемся
евклидово-расстоянием [3] между векторами ![]() и
и
![]() :
:
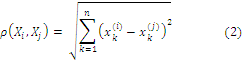
где ![]() - k-ая координата
- k-ая координата ![]() и
и
![]() векторов
соответственно.
векторов
соответственно.
2.1. Этапы обработки и кластеризации ИП и ИР
Сформированный обобщённый подход для обработки и кластеризации ИП и ИР:
1) Формирование вербальных векторов из терминов ИП и ИР.
2) Формирование словаря всех терминов (глобальное множество слов).
3) Формирование числовых векторов из вербальных с помощью позиционного кода.
4) Отказ от статических и ассоциативных методов для классификации ИП.
5) Сравнение иерархических методов (агломеративный и дивизивный). Для ИП агломеративный метод выполняется с меньшими вычислительными затратами.
6) Отказ от агломеративных методов для классификации ИР. Применение итерационных методов (метод k-средних и метод Фарель).
7) Применение числовых коэффициентов и DOM-фильтр для устранения влияния динамических элементов.
8) Представление ИП и ИР как единый объект исследования.
9) Внедрение понятия обобщённого вектора характеристик.
10) Сравнение комбинированной и обобщённой кластеризации. Для обобщённой кластеризации кластеры становятся более концентрированными.
11) Получение более стабильных кластеров из обобщённых объектов ИП и ИР.
12) Чем ближе ИР к ИП тем выше его индекс. Улучшена классификация ИР проведена в соответствии с поисковой истории ИП.
13) Тестирование результата над многозначными терминами.
2.2. Кластеризация ИР с применением числовых коэффициентов из DOM-модели
На каждом этапе получены промежуточные результаты. После отказа от статических и ассоциативных методов (не кластерные) в пользу агломеративного (кластерный), евклидово расстояние между объектами одной группы уменьшилось: диффузия объектов между кластерами снизилась. После внедрения новых объектов (ИР) пришлось отказаться от иерархических методов в пользу итерационных: расчёт центра тяжести позволило предварительно привязать новые объекты к кластерной структуре. Как только определились с методом кластеризации возникла проблема динамических элементов в DOM-модели ИР. Результаты расчёта степеней принадлежности [4] j-го ИР к кластерам подтверждают их динамичный характер
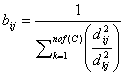 (3)
(3)
при
том, что и ![]() . Здесь
. Здесь ![]() — число кластеров в структуре;
— число кластеров в структуре;
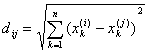 — евклидово расстояние между j-ым
объектом и ближайшим i-ым объектом k-ого кластера;
— евклидово расстояние между j-ым
объектом и ближайшим i-ым объектом k-ого кластера;
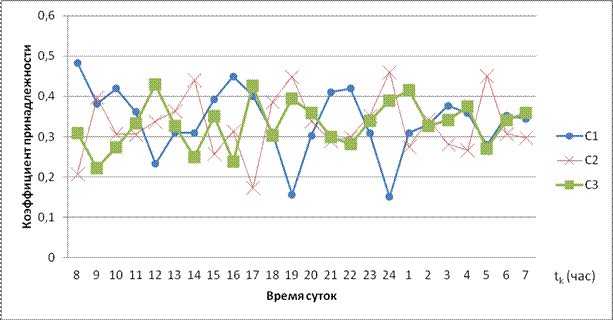 На рис. 1 графики скрещиваются, то есть в разные моменты времени j-ый
ИР принадлежит разным кластерам. Для устранения этого эффекта предлагается
использовать DOM-модель ресурсов с целью их «очистки» от динамических
компонентов партнёрских сетей, различного рода сообщений, рекламы и т.д. На
ряду с этим DOM-модель может быть использована для расчета весовых
коэффициентов характеристического вектора ресурса.
На рис. 1 графики скрещиваются, то есть в разные моменты времени j-ый
ИР принадлежит разным кластерам. Для устранения этого эффекта предлагается
использовать DOM-модель ресурсов с целью их «очистки» от динамических
компонентов партнёрских сетей, различного рода сообщений, рекламы и т.д. На
ряду с этим DOM-модель может быть использована для расчета весовых
коэффициентов характеристического вектора ресурса.
Рис. 1. Графики коэффициентов принадлежности ресурса для разных кластеров в разные моменты времени без использования весовых коэффициентов
Учитывая особенности DOM-модели Интернет-страниц, каждому элементу вектора wi(tk) может быть сопоставлен весовой коэффициент, рассчитанный по формуле
![]() (4)
(4)
где
nW – общее число слов в DOM-модели страницы; wt – числo вхождений слова на t-позиции в конкретном тэге DOM-модели страницы; k1 – коэффициент усиления (k1 > 1), значение которого рассчитывается исходя из наименования тэга, определяющего контекст слова на странице; k2 – коэффициент усиления (k2 ≥ 1), значение которого рассчитывается по формуле отношений площадей, занимаемых словами на странице:
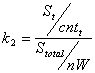 (5)
(5)
где
St – площадь области заголовка; cntt – число слов в заголовке; Stotal – площадь информационного текста; nW – общее число слов в DOM-модели страницы;
Повторный расчёт степеней принадлежности j-ого ИР с применением весовых коэффициентов, рассчитанных по формуле (4), приводит к построению новых графиков (рис. 2).
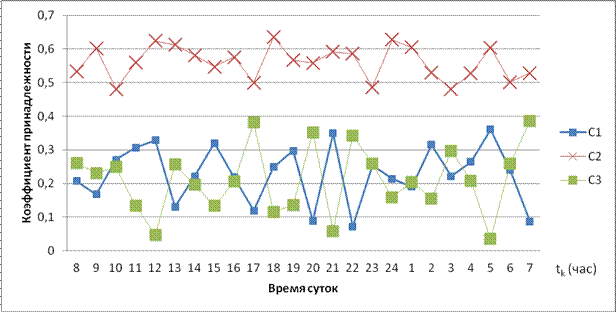
Рис. 2. Графики коэффициентов принадлежности ресурса после применения весовых коэффициентов.
Использование коэффициентов усиления (из формул 4 и 5), построенных на основании DOM-модели, приводит к сдвигу расчетного коэффициента принадлежности в сторону одного из кластеров (график С2). Остальные графики смещаются вниз: до применения усилительных коэффициентов среднее значение коэффициентов принадлежности к кластерам С1 и С3 равно 0,340 и 0,331 соответственно, а после их применения снизились до 0,229 и 0,211.
2.3. Трехтактная кластеризация ИР
Реализован метод трехтактной кластеризации динамических ИР с обратной связью. На вход в схему (рис.3) поступают URL-адреса Интернет-страниц (объекты кластеризации). Задача первого блока состоит в выявлении компонентов DOM-модели страницы с динамическими признаками и их удалении. Второй блок отвечает за формирование вектора характеристик на основе анализа исключительно статических объектов DOM-модели. Третий блок непосредственно осуществляет кластеризацию объекта.
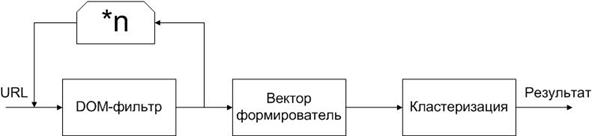
Рис.3. Схема трехтактной кластеризации динамических ИР.
Применение DOM-фильтра для кластеризации Интернет-страниц с динамическими компонентами улучшает показатели степеней принадлежности к кластерам (табл. 1).
Табл. 1. Степени принадлежности к кластерам до и после применения метода трёхтактной кластеризации.
|
Кластер
Эксперимент |
k1 |
k2 |
k3 |
|
До применения DOM-фильтра |
0,306 |
0,473 |
0,22 |
|
После применения DOM-фильтра |
0,153 |
0,632 |
0,21 |
Применение трёхтактной схемы кластеризации повышает показатели степеней принадлежности к кластерам примерно на 25%. Исследуемый объект становится ближе к соответствующему кластеру и кластеры становятся более плотными.
2.4. Обобщённая кластеризация ИП и ИР
Если представлять ИП и ИР, как единые объекты исследования, то можем говорить об обобщенном векторе характеристик x*i(tk) = (x*i,1(tk), …, x*i,j(tk), …, x*i,nof(V*)(tk)), где nof(V*) ≥ nof(V). Под обобщённой кластеризации будем понимать кластеризацию всех объектов исследования (ИП и ИР) без их разделения по типам. Если кластеризация объектов проводится раздельно, тогда мы говорим о комбинированной кластеризации.
После внедрения понятия обобщённого вектора характеристик и применения теории графов, пространство, где размещаются объекты ИП и ИР (обобщённые объекты) уменьшается в 0.15-0.6 раз (рис.4).
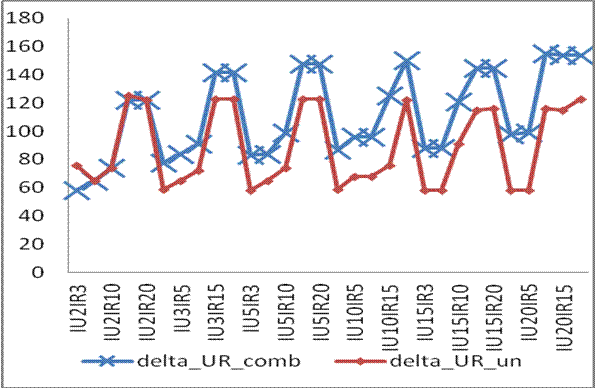
Рис.4 - Графики дельта расстояний между ближайшим и дальнейшим объектами относительно центра тяжести кластера.
На рис.4 можно заметить преимущество обобщённой кластеризации по сравнению с комбинированной: пространство объектов ИП + ИР становится более компактным.
Заключение
В настоящей статье кратко представлены все пройденые этапы кластеризации ИП и ИР. После каждого из перечисленных этапов были приняты решения в пользу одного из рассмотренных способов кластерного анализа. Наличие динамических компонентов в DOM-модели ИР приводило к неопределённостям: в разные, но близкие моменты времени информационные ресурсы могли принадлежать разным кластерам. Для снижения динамичности объектов были предложены 2 метода: метод коэффициентов усиления и метод трёхтактной кластеризации. Применение этих методов существенно повысило показатель степени принадлежности к кластерам. Внедрение понятия обобщённого вектора характеристик делает кластерное пространство более компактным: объекты становятся ближе чем это было при применении комбинированной кластеризации. Предложен новый подход, направленный на улучшения поиска ИР на основание поисковой активности ИП. Это позволит выделить более релевантные ИР при поиске многозначных терминов.
Список литературы
1. Яндекс. Статистика. Аудитория сервисов Яндекса. [электронный ресурс] ― URL: http://stat.yandex.ru/stats.xml?ReportID=-225&ProjectID=1
2. Википедия. Яндекс. [электронный ресурс] ― URL:
http://ru.wikipedia.org/wiki/%DF%ED%E4%E5%EA%F1
3. Айвазян С.А., Бухштабер В.М., Енюков И.С., Мешалкин Л.Д. Прикладная статистика классификация и снижение размерности – М: Финансы и статистика, 1989.
4. Гимаров В.А., Дли М.И., Битюцкий С.Я. Задачи нестационарной кластеризации состояния нефтехимического оборудования // Нефтегазовое дело ― 2004. [электронный ресурс] URL: http://www.ogbus.ru/authors/Gimarov/Gimarov_1.pdf.