BC/NW 2014 №2 (25):2.1
MATLAB R2014a: новые возможности параллельного программирования
Чернецов А.М.
(Федеральное государственное бюджетное учреждение науки Вычислительный центр им. А.А. Дородницына РАН, ФГБОУ ВПО Национальный исследовательский университет «МЭИ», Москва, Россия)
Математический пакет MATLAB [1-3] часто применяется в научных расчетах, при обучении инженеров, при анализе финансовых рисков и т.д. За последние годы в связи с развитием средств вычислительной техники и необходимостью ускорения расчетов встал вопрос о распределенной и параллельной обработке данных. Первоначально подобная возможность существовала только в виде 3-rd party решений, которые обладали существенными ограничениями [4]. Поэтому компания Mathworks реализовала в 2005 г. в пакете соответствующие функциональные возможности, которые активно развивались в новых версиях.
Общая схема распределенных вычислений в MATLAB приведена на рис. 1.
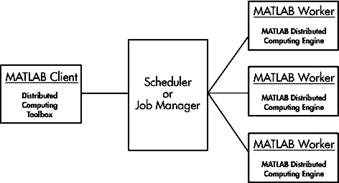
Рис.1. Общая схема параллельной обработки в MATLAB
Клиент через планировщик Scheduler запрашивает ресурсы рабочих процессов (workers). В его качестве может выступать как узел кластера, так и процессор SMP-системы. Все взаимодействия происходят через запущенную на каждом узле службу MDCE. В качестве планировщика выступает либо фирменный MathWorks Job Manager, либо можно использовать довольно широкий набор других планировщиков [3].
Следующий рассматриваемый вопрос – интеграция заданий MATLAB в действующие на кластерах системах управления пакетными заданиями (СУПЗ). MATLAB Distributing Computing Engine поддерживает следующие планировщики: встроенный от Mathworks (Job Manager), Windows CCS - планировщик от Microsoft для Windows Server 2003/2008 Cluster Edition, LSF, mpiexec либо планировщик общего вида. Планировщиком общего вида может выступать, например, планировщик системы PBS/Torque, Condor или Sun Grid Engine. Среди преимуществ встроенного планировщика от Mathworks можно выделить:
- поддержку контрольных точек,
- обеспечение автоматической доставки данных в рабочие процессы ( [4-6]).
Основным его и весьма существенным недостатком является невозможность совместного использования с существующими на многопроцессорном комплексе СУПЗ.
При использовании планировщиков LSF и Windows CCS также возможно обеспечение автоматической доставки данных в рабочие процессы.
На рис. 2 представлена общая схема работы с произвольной задачей.
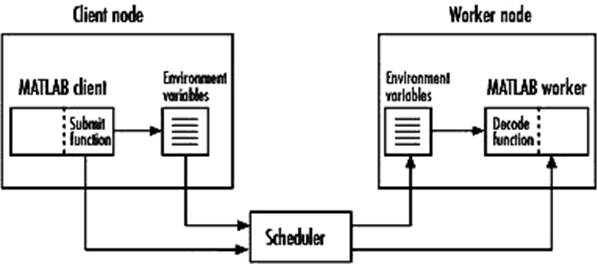
Рис. 2. Общая схема использования планировщика общего вида.
Запрашивается доступ к объекту планировщика sched и устанавливаются его свойства. Далее описываются функции Submit и Decode для постановки задач в очередь и соответственно возвращения результатов. В функции Submit определяются переменные и производится запуск заданий через систему очередей. В функции Decode процесс получает экспортированные средствами системы очередей значения переменных.
Межпроцессные обмены реализованы средствами библиотеки MPI mpich2 (MPICH2 версии 1.4.1p1). Вместо этой реализации можно использовать другие, удовлетворяющие определенным требованиям (см. [3,4,5]). В данном докладе рассматривается стандартная реализация.
Для выполнения параллельной задачи необходимо иметь запущенными на клиенте службу MDCE, планировщик Job Manager. Для каждого узла, на котором выполняются рабочие процессы, необходимо иметь запущенную службу MDCE и рабочий процесс worker. Подробно все эти процедуры описаны в [2-4]. Здесь мы укажем лишь их названия и выполняемые действия.
|
Название |
Действие |
|
mdce start mdce stop |
Запуск службы MDCS Останов службы MDCS |
|
startjobmanager stopjobmanager |
Запуск планировщика Job Manager Останов планировщика Job Manager |
|
startworker stopworker |
Запуск рабочего процесса Останов рабочего процесса |
|
Nodestatus |
Запрос информации о запущенных процессах и планировщиках |
Методология MathWorks выделяет отдельно распределенные (distributed) и параллельные (parallel) задачи. Примером первых является распределенное LU-разложение матрицы, когда матрица разделяется на блоки автоматически средствами MATLAB. Ко вторым относятся задачи, в которых межпроцессные обмены заданы явно с использованием специальных процедур, аналогичных средствам MPI [2, 3].
Начиная с версии MATLAB 2007b, компания Mathworks переименовала toolbox, отвечающие за возможности параллельного программирования: вместо Distributing Computing Toolbox и MATLAB Distributing Computing Engine их стали называть Parallel Computing Toolbox и MATLAB Distributing Computing Server.
В данном докладе распределенные процедуры не рассматриваются, поскольку большая их часть ничем не отличается от стандартных последовательных процедур MATLAB. С документацией по этой теме можно ознакомиться в [2,3].
В MATLAB в настоящее время существует два подхода для решения параллельных задач. Первый подход основан непосредственно на процедуре отправки задания Job Manager, в инструкциях (.m - файле) которой описана последовательность команд, которая будут выполняться рабочими процессами. В этом .m файле помимо основных команд MATLAB могут быть использованы специальные функции пакета для коммуникаций между рабочими процессами. Второй подход для решения параллельных задач основан на режиме pmode. С помощью этого режима непосредственно из командного окна MATLAB становится возможным обращение к процессам workers, просмотр их локальных переменных, обмен данными между ними. В режиме pmode команды, вводимые в рабочем окне MATLAB, будут исполняться всеми рабочими процессами, ассоциированными с соответствующим jobmanager.
Режим pmode следует использовать исключительно как средство отладки параллельных программ. В [4] рассмотрен пример параллельного вычисления числа π.
Более интересные примеры можно рассмотреть, используя первый подход.
В [4] приведена сравнительная таблица функций передачи сообщений в MATLAB и их аналогов в MPI. Там же рассмотрена параллельная реализация в среде MATLAB задач линейной алгебры – матричного умножения и решения СЛАУ методом Гаусса.
Начиная с версии R2007а, MATLAB имеет встроенные средства автоматического распараллеливания на многоядерных системах для основных математических операций, реализованных в ядре MATLAB.
Также необходимо отметить возможность запуска рабочих процессов MATLAB на клиенте, используя локальный планировщик. Этот планировщик позволяет распределять процессы исключительно на локальной машине, т.е. не обеспечивает возможности межузлового обмена. Еще одним важным ограничением является максимальное количество запускаемых рабочих процессов. В таблице ниже приведены сравнительные характеристики различных версий MATLAB:
|
Версия |
Число рабочих процессов |
Соответствие с характеристиками процессоров |
|
2006b |
1 |
1-ядерные системы |
|
2007a |
4 |
4-ядерные системы |
|
2009a |
8 |
2-х процессорные 4-ядерные системы |
|
2011b |
12 |
2-х процессорные 6-ядерные системы |
|
2014a |
Не ограничено |
|
Следует отметить, что наконец-то в выпуске R2014a было снято ограничение на число параллельно запускаемых процессов на одном узле.
В версии R2008А появилась возможность снизить загрузку на клиентскую сессию путем расчетов отдельных скриптов (программ) MATLAB на рабочих процессах MATLAB. Для этого была введена функция пакетного запуска batch [2]. Её целесообразно применять в случаях, когда необходимо быстро ускорить расчет, в алгоритме можно выделить крупные независимые блоки и нет времени на изучение средств параллельного программирования. Также в этой версии была введена новая для пакета конструкция параллельного программирования – цикл parfor, являющийся параллельной модификацией стандартного цикла for. Оператор parfor полезен в случаях, когда нужно провести много однотипных расчетов, например при моделировании методом Монте-Карло. Итерации цикла считаются независимо в произвольном порядке рабочими процессами. Понятно, что оператор parfor нельзя применять в случаях, когда имеется зависимость по данным между итерациями.
Еще одна конструкция, о которой необходимо упомянуть – это конструкция spmd. Операторы, выполняемые внутри блока spmd, выполняются одновременно во всех рабочих процессах. Синтаксис команды:
spmd [(m,n) ]
<statements>
end spmd
Здесь опциональные параметры m и n– минимальное и максимальное число рабочих процессов, соответственно.
Сегодня наметилась очевидная тенденция включения средств параллельного программирования в другие тулбоксы (toolboxes). Так, средства появились в функциях оптимизации (Optimization Toolbox, Global Optimization Toolbox), в статистике (Statistics Toolbox), экономике (Econometrics Toolbox), обработке изображений (Image Processing Toolbox), работе с нейронными сетями (Neural Network Toolbox) и т.д. Также стоит отдельно отметить включение возможностей в продукт MATLAB Compiler, который позволяет создавать исполняемый код, независимый от наличия пакета MATLAB. Более подробно с появившимися возможностями можно ознакомиться в [2,3].
Начиная с версии R2012A, появился новый интерфейс параллельного программирования. В версии R2014a он полностью заменил старый. Основные изменения приведены в таблицах ниже.
|
Старый интерфейс |
Новый интерфейс |
|
sched = findResource('scheduler',... 'Configuration','local'); j = createJob(sched,... 'PathDependencies',{'/share/app/'},... 'FileDependencies',{'funa.m','funb.m'}; createTask(j,@myfun,1,{3,4}); submit(j); waitForState(j); results = j.getAllOutputArguments; |
clust = parcluster('local');
j = createJob(clust,... 'AdditionalPaths',{'/share/app/'}),... 'AttachedFiles,{'funa.m','funb.m'}; createTask(j,@myfun,1,{3,4}); submit(j); wait(j); results = j.fetchOutputs; |
|
Старый интерфейс |
Новый интерфейс |
|
job (distributed job) |
parallel.job.MJSIndependentJob |
|
matlabpooljob |
parallel.job.MJSCommunicatingJob |
|
paralleljob |
parallel.job.MJSCommunicatingJob |
|
simplejob |
parallel.job.CJSIndependentJob |
|
simplematlabpooljob |
parallel.job.CJSCommunicatingJob |
|
simpleparalleljob |
parallel.job.CJSCommunicatingJob |
|
Старый интерфейс |
Новый интерфейс |
|
findResource |
|
|
createJob |
createJob (без изменений) |
|
createParallelJob |
createCommunicatingJob |
|
createMatlabPoolJob |
createCommunicatingJob |
|
Destroy |
|
|
clearLocalPassword |
|
|
createTask |
createTask (без изменений) |
|
getAllOutputArguments |
|
|
getJobSchedulerData |
|
|
setJobSchedulerData |
|
|
getCurrentJobmanager |
|
|
getFileDependencyDir |
После анализа становится понятно, что средства параллельного программирования были переупорядочены для применения ООП и различные процедуры и функции теперь стали принадлежать классу parallel.
Все прошедшее время возможности использования средств графических процессоров GPU в MATLAB расширялись от версии к версии. Более подробная информация представлена в [2].
За прошедшие 9 лет средства параллельного программирования в MATLAB превратились из чего-то экзотического в мощный инструмент, позволяющий быстро и эффективно решать задачи в различных предметных областях. В ближайших планах производителя – компании Mathworks – расширение функционала средств параллельного программирования и в других тулбоксах MATLAB.
Литература
1. http://www.mathworks.com
2. http://www.mathworks.com/access/helpdesk/help/pdf_doc/distcomp/distcomp.pdf
3. http://www.mathworks.com/access/helpdesk/help/pdf_doc/mdce/mdce.pdf
4. Оленев Н.Н., Печенкин Р.В., Чернецов А.М. “Параллельное программирование в MATLAB и его приложения”, М., Издательство ВЦ РАН, 2007.
5. Чернецов А.М. MATLAB 2009A: обзор новых возможностей параллельного программирования - “Международный форум информатизации МФИ-2009. Труды международной конференции “Информационные средства и технологии”, том 1, М.: Изд-во МЭИ, 2009, - С. 176-180.
6. Чернецов А.М. Использование средств MATLAB для организации распределенной обработки //Инфорино-2012. Труды международной конференции “Информатизация инженерного образования”, Москва, 10-11 апреля 2012 г., С. 127-130.