BC/NW 2014 №2 (25):9.1
Подход к глубинному извлечению данных из неструктурированных веб-страниц
Дзегеленок И.И., Пашинцев А.В., Юрьев В.К.
(ФГБОУ ВПО «Национальный исследовательский университет «МЭИ», Москва, Россия)
В настоящее время интернет является одним из основных источников информации. Самый распространённый способ её представления в сети – HTML-страницы (веб-страницы), информация на которых обрамляется в специальные конструкции – теги (узлы, метки, элементы). Им задаются свойства, влияющие на отображение элементов на странице. Теги вложены друг в друга и образуют древовидную структуру, которую называют деревом DOM (Document Object Model – объектная модель документа).
С конца 90-х годов началась активная разработка систем для извлечения данных из веб-страниц. Их цель – интеграция и последующая обработка полученной информации. Такие системы обычно называются английским термином “IE” (Information Extraction – извлечение информации). К числу наиболее известных систем такого типа относятся XWRAP, RoadRunner, EXALG, и др. Подробный обзор данных систем представлен в работе [1].
Существует несколько проблем, с которыми сталкиваются разработчики систем извлечения информации. Отсутствие общепринятого стандарта оформления веб-страниц привело к появлению большого количества разнородных сайтов. Ориентация сети на пользователя создала сильное «шумовое» поле в виде интерфейсных блоков и графических элементов. Первая проблема усложняет создание универсальной системы, подходящей под любые сайты; вторая заставляет фильтровать извлечённую информацию на предмет её полезности. Обычно в пределах одного сайта в сети страницы однотипны, т.е. сформированы по единому шаблону, что несколько облегчает поставленную задачу. Настройка под конкретный сайт обычно сводится к определению правил извлечения информации с любой страницы (в виде регулярных выражений или логических предикатов).
В настоящей работе представлено краткое описание системы глубинного извлечения данных из веб-страниц «ГИД». Описываемая система по заданному пользователем запросу ищет источники информации в сети интернет, формирует предметную область (набор параметров, сопряжённых с запросом) на основании выбранных источников, а также извлекаеи информацию с веб-страниц. Она оснащена удобным графическим интерфейсом, напоминающим обычный браузер, для взаимодействия с пользователем. Система разбита на несколько подсистем, каждая из которых способна работать автономно. В основе работы системы лежит использование языка XPath для доступа к данным на HTML-странице. XPath – язык запросов к элементам DOM-дерева, описанный в работе [2]. Он позволяет находить теги веб-страницы с помощью цепочки вложенности элементов и извлекать их содержимое.
Конечной целью описываемой системы является извлечение данных из веб-страниц и предоставление их системе «Решатель Открытых Задач» в виде файлов базы данных. Она разработана на кафедре ВМСС Московского Энергетического Института и создана для формирования знаний на основании предоставленных данных (предметной области и фактов). Подробнее с этой системой и её терминологией можно ознакомиться в работе [3]. Получающийся в результате работы системы «ГИД» файл можно использовать и в других целях, как и результаты промежуточной работы каждой из подсистем.
Система «ГИД» предназначена для извлечения данных из веб-страниц различных классов. Входными данными для системы является пользовательский запрос со свободной тематикой. Полученный запрос отправляется в поисковую систему, после чего на основании полученных веб-страниц формируется поисковое пространство (область поиска данных по запросу) и модель предметной области (возможные параметры запрашиваемой тематики). Далее система с помощью пользователя определяет местоположение данных на страницах-эталонах (одной или нескольких страницах из найденных) и извлекает выбранные данные на всех страницах выбранного класса. В процессе определения места данных на страницах-эталонах пользователь может пользоваться сформированной предметной областью либо задать свою предметную область.
Под классом веб-страниц подразумеваются все страницы с похожими DOM-деревьями (сходство определяется по унифицированному критерию сходства). Эталон – страница, выбранная пользователем, относительно которой создаются спецификации извлечений внутри класса веб-страниц. Спецификации извлечений – набор конструкций на языке XPath, по которым можно определить конкретный элемент на странице, и набор параметров, характерных для страниц одного класса. Поиском страниц занимается подсистема поиска веб-страниц (ППВ). За обработку найденных страниц отвечает подсистема морфологического анализа (ПМА). Разметка страницы (формирование спецификации извлечений) происходит в подсистеме создания спецификаций (ПСС). Извлечение данных и формирование выходного файла производится в подсистеме извлечения искомых данных (ПИИД). Для оптимизации работы подсистем взаимодействие с ППВ и ПМА реализовано на серверной стороне посредством веб-интерфейса, взаимодействие с ПСС и ПИИД – на клиентской стороне с помощью устанавливаемого программного обеспечения. Подсистемы ПСС и ПИИД связаны между собой приложением-диспетчером. Взаимодействие между клиентской и серверной частью обеспечивается получением серверной стороной запроса пользователя и передачей результирующих файлов клиенту. Итоги работы с системой сохраняются в базе данных на клиентской стороне для дальнейшей обработки и актуализации извлечённой информации. Схема взаимодействия подсистем системы «ГИД» изображена на рис. 1.
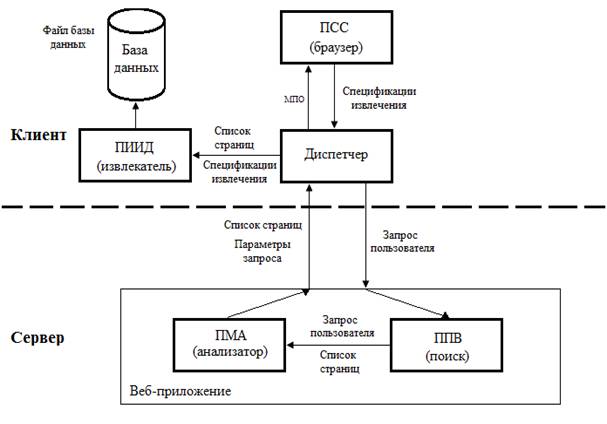
Рис. 1. Схема взаимодействия подсистем системы «ГИД»
Подсистема ППВ обеспечивает снабжение всей системы страницами с актуальными данными, касающимися запроса пользователя. В её основе лежит взаимодействие с уже существующими поисковыми системами. Поисковой системой в данном контексте является любая система поиска информации в сети интернет, удовлетворяющая следующим требованиям. Она должна воспринимать запросы пользователя через адресную строку браузера; необходима также поддержка выделения ключевых слов в запросе. У системы должен быть веб-интерфейс, выдающий при запросе одну или несколько ссылок на связанные с запросом страницы, упорядоченные по релевантности (степени соответствия) ссылок. Примерами таких систем являются Yandex, Google, Bing, DuckDuckGo, Yahoo! и другие.
Подсистема ППВ формирует запрос к выбранной пользователем поисковой системе в соответствии с правилами формирования запросов этой системы и анализирует выдачу на предмет отсутствия в ней ссылок, что означает, что у поисковой системы не оказалось возможности найти интересующую пользователя информацию. Для этого используется язык php (скриптовый язык, ориентированный на веб-программирование) и модуль curl внутри него (библиотека функций и классов, с помощью которых можно получать содержимое веб-страниц, минуя использование браузера). Документация на язык php доступна по ссылке [4].
Результатом работы этой подсистемы является набор ссылок (URL – универсальный локатор ресурсов, адрес страницы в сети интернет) на веб-страницы, извлечённый из выдачи поисковой системы с помощью XPath-запроса и отсортированный по убыванию релевантности пользовательскому запросу. За сортировку отвечает поисковая система. При необходимости, пользователь может пропустить работу с этой системой и указать напрямую тот список страниц, с которым он хочет работать.
Подсистема ПМА реализует несколько алгоритмов лингвистического анализа для определения значимых для пользователя параметров запроса. Она работает с данными, предоставленными подсистемой ППВ.
Первым этапом работы подсистемы ПМА является получение текстов (источников информации) из найденных/заданных пользователем веб-страниц. Для извлечения содержимого веб-страниц используются механизмы подсистемы ППВ. Подсистема формирует запросы к каждому из найденных сайтов и возвращает их DOM-деревья. Дальнейшая обработка этих деревьев заключается в фильтрации тегов на предмет интерфейсных блоков и некоторых тегов, анализировать которые не имеет смысла. Такие узлы фильтром отсекаются.
Интерфейсные блоки определяются по типовым значениям некоторых свойств тегов, которыми образованы эти блоки (например, слово “menu” в свойстве “name”). Также отсекаются теги script, style, input и др. В первом содержится код на языке JavaScript, с помощью которого обычно реализуется взаимодействие с пользователем на странице. JavaScript – скриптовый язык, код которого исполняется на стороне пользователя браузером. Удаляемый код не даёт никаких сведений об интересующем пользователя предмете. Тег style содержит сведения об отображении элементов, тег input используется для организации ввода на странице.
По завершении работы фильтра DOM-дерево страницы зачастую становится меньше, что позволяет снизить влияние «шумов» (случайно оказавшейся на странице информации) на результат работы подсистемы. Из получившегося дерева впоследствии извлекается весь текст (т.е. содержимое каждого тега, отличное от другого тега). Этот текст уже лишён всякой структуры, за исключением оригинального разбиения на предложения, и к нему можно применять методы лингвистического анализа.
Для формирования предметной области к текстам-источникам последовательно применяются несколько алгоритмов. Первый – алгоритм-лемматизатор. Он выявляет возможные морфологические формы (леммы) каждого слова в этих текстах с помощью поиска слов по словарю лемм. Используемые в подсистеме словари составлены проектом «Автоматическая Обработка Текстов», доступным по адресу [5]. В этих словарях содержатся леммы слов с указанными для них грамматическими признаками – род, число, падеж/спряжение, время. Если форма не найдена в словаре, лемма этого слова определяется рекурсивным удалением приставок, суффиксов, постфиксов и окончаний. Получившаяся основа на каждом этапе проверяется по словарю, чтобы обеспечить максимально точное определение формы слова. Описанный подход является реализацией модифицированного алгоритма стеммера Портера (сайт [6]).
Второй алгоритм на основании грамматических признаков слов выделяет отношения между словами и предложениями внутри текста. Эта информация позволяет искать по тексту предмет запроса пользователя и выбирать сопряжённые с ним признаки и свойства, из которых формируется предметная область. При наличии списка страниц области формируются несколько раз, после чего происходит поиск пересечений между ними. Это позволяет получить более достоверные результаты.
Последним этапом работы подсистемы ПМА является формирование области поиска для следующей подсистемы на основании сформированной предметной области. На этом этапе задействуются механизмы подсистемы ППВ. К поисковой системе производится несколько запросов для поиска однотипных страниц в пределе сайта/сайтов из списка. Такие страницы образуют отдельные классы веб-страниц (как правило, по одному классу на один домен), с которыми уже работает следующая подсистема.
Подсистема ПСС работает с переданными ей классами веб-страниц. Она реализована в виде браузера с надстройками с помощью программной оболочки Chromium, представляющей собой связку браузерного движка Webkit и JavaScript-движка V8 (конкретно для этой подсистемы была взята библиотека Awesomium). Надстройки расширяют интерфейс и реализуют работу ПСС. Пользователь из списка страниц выбирает эталон, который открывается в окне программы. На этой странице пользователь размечает необходимую информацию. Разметка происходит с помощью внедрения исполняемого Javascript-кода на уже загруженную страницу. Этот код отслеживает положение курсора пользователя и выделяет рамкой те элементы, над которыми он находится. По щелчку мыши происходит извлечение XPath-пути элемента, выделенного рамкой, а его содержимое привязывается к выбранной переменной из предметной области. Таким образом размечается вся страница и формируется спецификация извлечения.
Вся подсистема написана на языке программирования C#, с которым можно ознакомиться в работе [7]. Результатом работы пользователя с этой системой является файл, хранящий спецификации извлечения для каждого из используемых классов веб-страниц.
В подсистеме ПИИД происходит непосредственное извлечение данных со страниц, указанных в сформированном подсистемой ПСС файле. С помощью браузера, работающего в фоновом режиме (без оконной формы) подсистема обращается к каждой из указанных страниц и применяет к ней XPath-запросы для этого класса страниц. Так подсистема получает значения связанных с каждым запросом переменных, постепенно формируя итоговый файл – базу фактов для «Решателя Открытых Задач» (файл в формате dbf, который потенциально можно использовать в любом другом приложении). Безоконный браузер необходим для предварительной обработки страницы на предмет исполняемого кода, который мог повлиять на DOM-дерево. Без предварительной обработки XPath-запросы, сформированные в подсистеме ПСС (т.е. на странице после исполнения JavaScript-кода), могут оказаться недействительными/частично неверными (могут ссылаться на другие элементы DOM-дерева).
В настоящей работе представлена система автоматизированного извлечения неструктурированных данных из веб-страниц «ГИД». Относительно существующих решений в области извлечения информации эта система отличается гибкостью настройки (пользователь может вмешаться на любом этапе работы системы и взять процесс извлечения информации под свой контроль), возможностью автоматизированного нахождения параметров пользовательского запроса, а также возможностью актуализировать данные в случае появления более свежих источников в сети интернет. Удобный пользовательский интерфейс позволяет работать с любыми веб-сайтами, система поиска страниц может сама генерировать ссылки для дальнейшего извлечения информации с них.
Также, в отличие от многих других систем извлечения информации из сети интернет, подсистемы, используемые в работе системы «ГИД», полностью автономны, и результаты их работы могут быть использованы в разных целях. Подсистему морфологического анализа можно использовать для нахождения связанных со свободной тематикой параметров (не только в пределах веб-страницы, но и при работе с обычными текстами). Подсистему извлечения информации можно настроить на чтение температурных или биржевых показателей и запускать с определённой периодичностью, чтобы получать актуальные сведения о погоде и экономической обстановке. На основании имеющейся системы также можно сделать новостную ленту, собирающую свежие новости с нескольких сайтов, одновременно. Получаемые в результате работы всей системы файлы базы данных можно использовать в самых разных приложениях и для сбора сведений для научных работ; планируется доработать систему для выгрузки результатов работы системы «ГИД» во всех популярных форматах файлов.
Опытная эксплуатация системы показала состоятельность предложенных подходов и их эффективность в области извлечения информации из сети интернет. Возможность пользовательского вмешательства в процесс извлечения информации позволяет исправлять некоторые неточности в определении параметров пользовательского запроса. Эксплуатация системы позволила наметить направления для её дальнейшего развития, а именно: повышение удобства и возможностей интерфейса, расширение пользовательских настроек, извлечение данных по заранее заданным правилам, автоматизация актуализации базы данных, повышение точности определения предметной области и т.д. В будущем планируется выложить исходный код системы «ГИД» в свободный доступ и снабдить соответствующими лицензиями для его свободного распространения, чтобы окончательное решение проблемы извлечения данных стало ещё ближе к конечному пользователю.
Литература
1. C. Chang, M. Kayed, M. R. Girgis, K. F. Shaalan. A Survey of Web Information Extraction Systems. IEEE Transaction in Knowledge and Data Engineering, 18(10):1411-1428,2006
2. Jonathan Robie, Don Chamberlin, Michael Dyck, John Snelson. W3C 2014. XML Path Language (XPath) 3.0
3. Дзегеленок И. И. На пути к преобразованию информационных ресурсов Интернета в актуальное знание. Информационные ресурсы России : ИРР. -М.:Росинформресурс, 2011,N № 2.-С.9-14
4. Mehdi Achour, Friedhelm Betz. Online-documentation of PHP-language [Электронный ресурс]. – Сайт. – Режим доступа: php.net (дата обращения: 01.05.2014)
5. Алексей Сокирко. Проект «Автоматическая обработка текстов» [Электронный ресурс]. – Сайт. – Режим доступа: aot.ru (дата обращения: 15.04.2014)
6. Martin Porter. The Porter Stemming Algorithm [Электронный ресурс]. – Сайт. – Режим доступа: snowball.tartarus.org (дата обращения: 20.03.2014)
7. Троелсен Э. Язык программирования C# 5.0 и платформа .NET 4.5. –М.: Вильямс, 2013. -1312 с.