СТРУКТУРА ПРОЕКТА HADOOP ОРГАНИЗАЦИИ APACHE SOFTWARE FOUNDATION.
Мизинов С.В., Русинов С.Г., Добряков П.С., Нефедов Е.Ю.
Hadoop — проект фонда Apache Software Foundation [1], свободно распространяемый набор утилит, библиотек и программный каркас для разработки и выполнения распределённых программ, работающих на кластерах. Разработан с использованием языка программирования Java в рамках вычислительной парадигмы MapReduce, представленной компанией Google в 2004 году, согласно которой приложение разделяется на большое количество одинаковых элементарных заданий, выполняемых на узлах кластера и естественным образом сводимых в конечный результат. В 2008 году Hadoop стал одним из ведущих проектов Apache. Сегодня Hadoop последних версий широко используется как в коммерческих компаниях, так и в научных и образовательных учреждениях [2]. На данный момент выпущены две версии продукта, Hadoop 1.0 и 2.0 (релиз 2.6.3 декабрь 2015).Структуру проекта Hadoop принято называть экосистемой. Экосистемы версии 1.0 и 2.0 приведены на рисунке 1. Рассмотрим основные подпроекты:
- Common — содержит библиотеки управления файловыми системами, поддерживаемыми Hadoop и сценарии создания необходимой инфраструктуры и управления распределённой обработкой, для удобства выполнения которых создан специализированный упрощённый интерпретатор командной строки (FS shell, filesystem shell). Большая часть команд интерпретатора аналогична командам shell Unix, но есть команды специфические для Hadoop (например, count подсчитывает количество каталогов, файлов и байтов по заданному пути).
- MapReduce — программный каркас для программирования распределённых вычислений в рамках парадигмы MapReduce.
- HDFS (Hadoop Distributed File System) — файловая система, предназначенная для хранения файлов больших размеров, поблочно распределённых между узлами вычислительного кластера. Все блоки в HDFS (кроме последнего блока файла) имеют одинаковый размер, и каждый блок может быть размещён на нескольких узлах, размер блока и коэффициент репликации (количество узлов, на которых должен быть размещён каждый блок) определяются в настройках на уровне файла hdfs-site.xml. Благодаря репликации обеспечивается устойчивость распределённой системы к отказам отдельных узлов. Организация файлов в пространстве имён — традиционная иерархическая: есть корневой каталог, поддерживается вложение каталогов, в одном каталоге могут располагаться и файлы, и другие каталоги. Развёртывание экземпляра HDFS предусматривает наличие центрального узла имён (namenode), хранящего метаданные файловой системы и метаинформацию о распределении блоков, и серии узлов данных (datanode), непосредственно хранящих блоки файлов. Узел имён отвечает за обработку операций уровня файлов и каталогов — открытие и закрытие файлов, манипуляция с каталогами, узлы данных непосредственно отрабатывают операции по записи и чтению данных. Узел имён и узлы данных снабжаются веб-серверами, отображающими текущий статус узлов и позволяющими просматривать содержимое файловой системы. Административные функции доступны из интерфейса командной строки. HDFS является неотъемлемой частью проекта, однако, Hadoop поддерживает работу и с другими распределёнными файловыми системами без использования HDFS, поддержка Amazon S3 и CloudStore реализована в основном дистрибутиве. HDFS может использоваться не только для запуска MapReduce-заданий, но и как распределённая файловая система общего назначения.
- YARN (Yet Another Resource Negotiator — «ещё один посредник к ресурсам») — модуль, появившийся с версией 2.0 (2013 год), отвечающий за управление ресурсами кластеров и планирование заданий. Если в предыдущих выпусках эта функция была интегрирована в модуль MapReduce, где была реализована единым компонентом (JobTracker), то в YARN функционирует логически самостоятельный демон — планировщик ресурсов (ResourceManager), абстрагирующий все вычислительные ресурсы кластера и управляющий их предоставлением приложениям распределённой обработки. Работать под управлением YARN могут как MapReduce-программы, так и любые другие распределённые приложения, поддерживающие соответствующие программные интерфейсы. YARN обеспечивает возможность параллельного выполнения нескольких различных задач в рамках кластера и их изоляцию (по принципам мультиарендности), является интерфейсом между аппаратными ресурсами кластера и широким классом приложений, использующих его мощности для выполнения вычислительной обработки
Кластер Hadoop можно разделить на два абстрактных объекта: механизм MapReduce и распределенная файловая система HDFS. Механизм MapReduce обеспечивает выполнение задач map (отображение) и reduce (сокращение) в рамках кластера и возврат результатов. При этом распределенная файловая система предоставляет схему хранения, позволяющую реплицировать данные между узлами. Распределенная файловая система Hadoop (HDFS) поддерживает большие файлы (как правило, кратные 64 МБ).
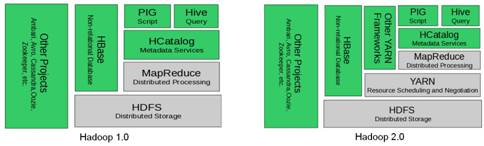
Рис. 1. Экосистема Hadoop 1.0 и 2.0
Запросом клиента к кластеру Hadoop 1.0 управляет JobTracker. JobTracker, взаимодействуя с NameNode, распределяет задание как можно ближе к данным, с которыми оно будет работать. NameNode является главным узлом файловой системы и обеспечивает сервисы метаданных для распределения и репликации данных. JobTracker распределяет задачи map и reduce в доступные слоты в одном или нескольких TaskTrackers. TaskTracker выполняет задачи map и reduce с данными DataNode (подчиненные узлы распределенной файловой системы). После завершения задач map и reduce TaskTracker уведомляет об этом JobTracker, который определяет завершение всех задач и сообщает об этом клиенту. Иллюстрация архитектуры кластера приведена на рисунке 2.
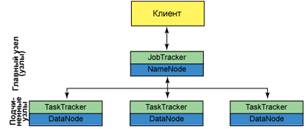
Рис.2. Архитектура кластера Hadoop 1.0
Несмотря на все свои преимущества, подход с использованием JobTracker и TaskTracker стал главным недостатком из-за ограничений масштабирования и наличия режимов отказов, вызванных сетевыми издержками. Эти проблемы были также характерны для модели обработки MapReduce. С целью ликвидировать эту зависимость JobTracker и TaskTracker были удалены из Hadoop 2.0 и заменены новым модулем YARN. Иллюстрация архитектуры кластера приведена на рисунке 3.
Корнем иерархии YARN является ResourceManager. Этот демон управляет всем кластером и назначением приложений базовым вычислительным ресурсам. ResourceManager распределяет ресурсы (вычислительные ресурсы, память, пропускная способность и т.д.) для базовых NodeManager (агент YARN на узле). Кроме того, ResourceManager взаимодействует с ApplicationMaster при распределении ресурсов и с NodeManager при запуске и мониторинге базовых приложений. В этом контексте ApplicationMaster выполняет некоторые функции своего предшественника TaskTracker, а ResourceManager выполняет роль JobTracker.
NodeManager управляет всеми узлами в кластере YARN. NodeManager предоставляет сервисы на каждом узле кластера, начиная с контроля управления контейнером в течение его жизненного цикла и заканчивая мониторингом ресурсов и отслеживанием состояния узла. В отличие от MapReduce в Hadoop 1.0, управлявшей задачами map и reduce через слоты, NodeManager управляет абстрактными контейнерами, которые представляют собой ресурсы на узле, доступные для конкретного приложения. YARN по-прежнему использует слой HDFS с главными узлами NameNode для сервисов метаданных и DataNode для сервисов хранения, реплицированных по всему кластеру.
Каждым экземпляром приложения, которое выполняется в YARN, управляет демон ApplicationMaster. Он отвечает за получение ресурсов из ResourceManager и мониторинг (посредством NodeManager) исполнения и потребления ресурсов контейнеров (распределение ресурсов процессора, памяти и т.д.).
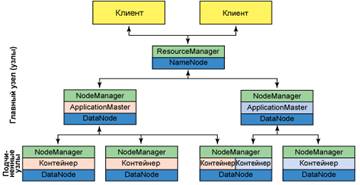
Рис. 3 Архитектура кластера Hadoop 2.0
Из всего вышесказанного становится ясно, что прежнюю архитектуру Hadoop 1.0 сильно ограничивал JobTracker, отвечавший за управление ресурсами и планирование заданий в кластере. Новая архитектура YARN отказывается от этой модели; теперь за управление использованием ресурсов приложениями отвечает ResourceManager, а за управление выполнением заданий – ApplicationMasters. Это изменение устраняет узкое место, а также повышает возможность масштабирования кластеров Hadoop до гораздо более крупных конфигураций, чем прежде. Кроме того, помимо традиционной MapReduce, YARN позволяет одновременно применять различные модели программирования, в том числе обработку графов, итерационную обработку, машинное обучение и кластерные вычисления, используя стандартные схемы передачи информации, такие как Message Passing Interface.
Литература
1. Apache Hadoop [Электронный ресурс] : официальный веб-сайт проекта Hadoop организации-фонда Apache Software Foundation. Режим доступа: http://hadoop.apache.org , свободный. Яз. Англ.
2. Радченко Г.И. Распределенные вычислительные системы – Челябинск.: Фотохудожник, 2012. – 184 с.