BC/NW 2016 № 1 (29): 2.1
РАЗРАБОТКА ПРОГРАММЫ ПЕРЕДАЧИ ДАННЫХ МЕЖДУ СЕРВЕРОМ И УЗЛАМИ GRID КЛАСТЕРА С ВОЗМОЖНОСТЬЮ ТЕСТИРОВАНИЯ ВРЕМЕННЫХ ЗАТРАТ
Громов А. С.
Целью данной работы является разработка средства распределения данных в GRID кластере с возможностью тестирование временных затрат этого распределения. GRID кластер строится на основе группы рабочих станций и объединенный в локальную сеть. В качестве центрального узла кластера используется сервер, реализующий поиск и установку соединения для всех узлов кластера. При проведении вычислений на кластере на каждом этапе необходимо распределить с сервера начальные данные между всеми узлами. Механизм распределения этих данных должен оценить фактические временные затраты на передачу и предоставить их для дальнейшего анализа работы кластера.
В последние годы распределенные вычисления открыли новые пути приложениям, требующим больших вычислительных мощностей. На сегодняшний день, в связи с ростом объёмов данных, можно говорить о практически повсеместном использовании распределенных вычислений в научной среде [1]. Но в то же время, применение распределенных вычислений для обучения искусственных нейронных сетей (ИНС) является относительно новой задачей и было мало исследовано [2, 3].
Технология grid-вычислений призвана решить задачу эффективного использования ресурсов, принадлежащих к одной или нескольким организациям в глобальном масштабе. Grid-вычисления, подтвердили свое место в науке такими проектами, как: Boinc, EGEE, AntHill. Таким образом, растущая потребность в вычислительных мощностях и высокая степень интеграции распределённых вычислительных ресурсов делают создание платформы для обучения нейронных сетей приоритетной задачей
Основные положения концепции системы
В настоящее время распределенные вычислительные системы мало задействованы для решения задач с применением нейронных сетей. Проведя исследование существующих технологии распределенного обучения нейронных сетей [4,5,6] были сформулированы основные концепции для построения и функционирования программной платформы удовлетворяющей актуальным потребностям в моделировании нейронных сетей. Использование свободных мощностей, волонтёрские вычисления, стандартные интерфейсов и протоколы, масштабируемость, высокие требования к качеству услуг являются одними из стандартных подходов при создании grid-систем. В рамках реализации механизма параллельного обучения нейронных сетей были приняты следующие концепции:
– Минималистичный подход к распределению нейронных сетей. Для решения широкого круга задач необходимо распределение не самой нейронной сети, а только обучающей выборки. Массив обучающих векторов разделяется на несколько блоков, а блоки в свою очередь, распределяются между вычислительными узлами. Таким образом, обучение ИНС распараллеливается в рамках одной эпохи. Процесс обучения относится к классу слабосвязанных задач.
– Свободный выбор архитектуры ИНС. Архитектуры ИНС крайне разнообразны и для их применения к конкретной задачи зачастую требуется не только изменение параметров, но иногда и изменение самой модели. Поэтому система должна поддерживать модульную интеграцию программных библиотек, реализующих различные типы нейронных сетей.
Схема алгоритма функционирования системы приведена на рис. 1. В момент, когда клиент скачивает параметры и кэширует блоки происходит передача данных по сети кластера. Это действие повторяется каждую эпоху алгоритма и в конечном счете анализ временных затрат покажет, насколько сильно влияют временные затраты на передачу данных на общие показатели производительности нашего grid-кластера.
Количество эпох E задается на начало обучения и определяется пользователем. Все данные для передачи разбиваются на блоки. Каждую эпоху e, происходит передача блока данных b, затем клиентская часть кэширует блок на свой жесткий диск, а затем выделяет в своем блоке вектор vi из набора векторов, количеством V. Вектор является единичным набором данных для обучения. Таким образом, все данные проходят процесс разбиения до элементарных векторов. Передаче и разбиению данных посвящена данная работа.
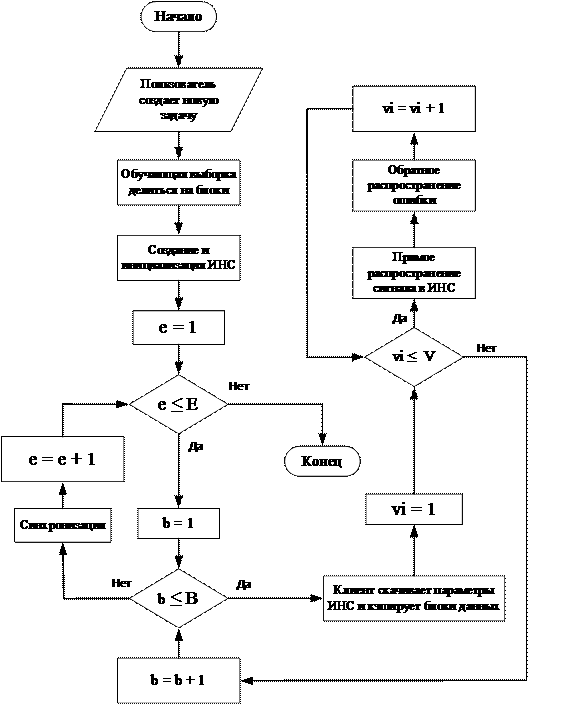
Рис. 1. Алгоритм функционирования системы.
1.1 Общая схема и состав grid-кластера
Концепция разработки магистерской диссертации предполагает выполнение задач на стандартных стационарных компьютерах, находящихся в лаборатории или рабочих местах. Общая схема grid-кластера приведена на рис. 2. В виду того, что использование вычислительных мощностей таких устройств крайне низка, и в отсутствие сотрудников рабочие машины простаивают. В виду всего этого, как говорилось ранее в данной работе grid-кластер представляет собой множество вычислительных машин, работающих на конкретной ОС. Вычислительные машины представляют собой гетерогенные вычислители и могут значительно отличаться по характеристикам. Основной принцип построения – универсальность и использование тех вычислительных мощностей, что имеются в распоряжении. Сервером является один из узлов кластера, которых является планировщиком заданий и источником данных для вычислений всех узлов кластера. Рекомендуется выбирать для сервера вычислительную машину с наилучшими характеристиками кластера.
В плане сетевого оборудования также нет особых ограничений. В данной работе предполагается, что grid-кластер соединен в локальную сеть коммутатором или маршрутизатором.
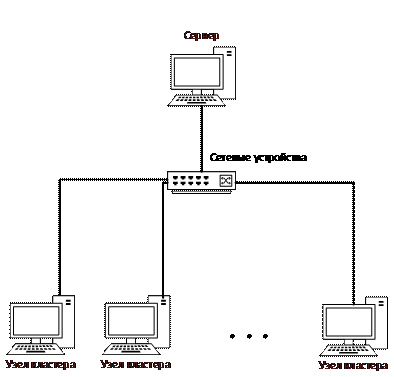
Рис. 2. Общая схема модели grid-кластера.
Постановка задачи расчета временных затрат при выбранной конфигурации кластера
В данной части работы предлагается оценить зависимость временных затрат на передачу данных узлам grid-кластера от размера обучающей выборки. Для модели grid-кластера используем доступное оборудование.
При разработке тестирующей части программы необходимо измерить общие временные затраты на передачу данных узлам. На рис. 3 изображена диаграмма передачи и основные этапы временных задержек. Для того, чтобы измерить полное время цикла, необходимо засечь время на сервере перед чтением готовых к отправке данных с диска. В конце с узла передать сигнал об окончании кэширования данных на сервер. И только после получения такого сигнала на сервере отметить конечное время передачи.
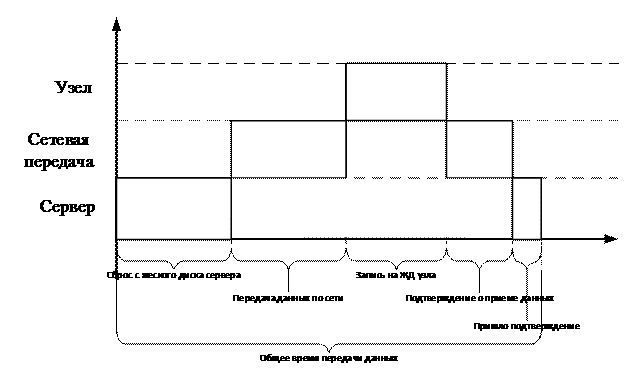 Рис. 3.
Диаграмма временных затрат при передаче данных.
Рис. 3.
Диаграмма временных затрат при передаче данных.
Расчет задержек для тестируемого кластера
Схема элементов grid-кластера для тестирования передачи приведена на рис. 4. В контур входят все элементы, способные внести задержки при передаче. В качестве серверного узла рабочий компьютер. Характеристики передающих устройств, входящих в тестируемый кластер приведены в табл. 1. Узел в нашем случае представлен в виде портативного компьютера, соединенным с сервером WI-FI каналом. На всех узлах используются установленные ОС на базе windows.
Временные расчеты при передаче основываются на пропускных способностях всех элементов контура. Задержки внутренней логики устройств, а также затраты на использование протокола TCP остаются без учета, ввиду их небольшого вклада в задержки и сложности измерения исключительно на серверном узле.
При использовании оборудования для тестирования программы следующие элементы контура влияли на временные затраты: жесткий диск сервера, сетевая карта сервера, среда передачи от сервера до маршрутизатора, сам маршрутизатор, беспроводное соединение с портативным компьютером, сетевая карта портативного компьютера и его жесткий диск.
Теоретическое время временных затрат в нашем случае будет рассчитано исходя из пропускных способностей каждого элемента контура. Ввиду того, что сообщение о подтверждении данных состоит из одного байта, то его задержку в расчет включать не будем.
Лимитирующая пропускная способность контура является беспроводной канал со скоростью 54 Мбит/c. Объем данных 502 мб.
Время, затраченное на передачу данных T будет следующим:
T = ![]()
![]() = 74,37 c
= 74,37 c
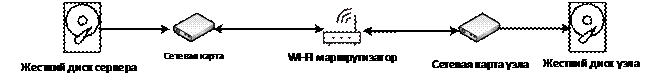 Рис. 4. Схема контура передачи данных.
Рис. 4. Схема контура передачи данных.
Таблица 1. Список оборудования контура передачи данных
|
Номер |
Название устройства |
Пропускная способность |
|
1 |
Жесткий диск Western Digital AV-25 1Tb. Интерфейс SATA – II |
До 300 Мбит/c |
|
2 |
Сетевая карта D-Link DGE-530T |
До 100 Мбит/с |
|
3 |
WI-FI маршрутизатор TP-Link Archer C20 |
100 Мбит/c |
|
4 |
Сетевая карта Realtek RTL8168/8111 Тип протокола: IEE 802.11g |
До 54 Мбит/c |
|
5 |
Жесткий диск Seagate ST1000LM024 1 Tb. Интерфейс SATA - II |
До 300 Мбит/c |
При проверке программы необходимо иметь ввиду, что скорость беспроводного канала зависит от удаленности (или мощности) сигнала от источника, а также от загруженности канала данной частоты.
Описание механизма рассылки начальных данных
На начало работы кластера, сервер устанавливает соединения со всеми узлами-клиентами и опрашивает их о готовности принимать данные. После регистрации всех узлов, сервер должен разделить имеющуюся и готовую к отправке узлам обучающую выборку на блоки. Каждый блок должен быть доставлен конкретному узлу. Блоки данных фиксированной длины передается по протоколу TCP всем узлам одновременно и при этом фиксируется время начало передачи. Узлы в свою очередь, приняв данные с сервера должны сохранить их на свой жесткий диск для дальнейшей работы с ними. После окончания передачи данных всем узлам с учетом сброса данных на жесткие диски, сервер фиксирует время конца процесса передачи данных.
При разработке данной программы в виду того, что все узлы кластера представляют собой компьютерную сеть, а не выделенный для задачи сервер.
В процессе измерения времени передачи данных могут возникнуть множество дополнительных задержек, связанных с загрузкой локальной сети в данный момент, распределением узлов территориально и состоянию работы жесткого диска узла в момент принятия данных.
В связи с тем, что кластер работает в ненагруженном режиме и его вычислительные ресурсы во время расчетов могут использоваться для прочих целей, то замер времени является не показателем эффективности передачи данных, а одним из показателей при расчете доли временных затрат каждого этапа обучения.
Постановка задачи для разработки программы тестирования временных затрат
Программа тестирования временных затрат состоит из двух частей: клиентской и серверной. Клиентская часть запускается на узлах кластера и включает режим прослушивания сигнала с сервера. Серверная часть опрашивает заранее заданные узлы и устанавливает с ними связь, отображая пользователю список готовых к работе.
Главной задачей серверной части является установка соединений и запуск передачи данных узлам. Алгоритм работы представлен на рис. 4.
После выбора объема обучающей выборки, программа должна рассчитать объем передаваемых данных для каждого узла и создать файлы соответствующего объема на жестком диске. После передачи и приема подтверждений, программа должна выдать результат в секундах о временных затратах для пользователя.
Структура разрабатываемых программ
Программа написана на языке С# с использованием библиотек .net 3.5 для работы с сетевыми функциями.
Основными требованиями для работы программы является установленная на компьютеры предполагаемого кластера ОС windows с поддержкой .net версии 3.5 и выше.
Были созданы два исполняемых файла serv.exe и nod.exe, для запуска на серверной машине и на узлах-клиентах.
Структура программы для узла
Главной задачей узла является запуск прослушивания сигнала от сервера и готовность принять данные. После установки соединения необходимо принять данные, сохранить их на жесткий диск и отправить сигнал об окончании на сервер. Алгоритм работы представлен на рис. 5.

Рис. 5. Алгоритм работы узла.
Узел создает слот прослушивания, на который приходит сигнал от сокета после чего осуществляет прием данных от сервера. В табл. 2 представлены основные функции для программы узла (nod.exe).
Таблица 2 – описание функций программы для узла
|
Имя функции |
Описание функции |
|
Receive(int ID) |
Процедура приема данных с сервера |
|
Cache (byte * data, int size) |
Процедура записи принятых данных на жесткий диск |
|
EndMsg() |
Процедура отправки сигнала конца приема данных |
|
CloseSockets(size) |
Процедура закрытия всех сокетов. |
|
WaitForData |
Процедура асинхронного ожидания приема данных |
|
OnDataReceived(IAsyncResult asyn) |
Функция-делегат для асинхронного соединения |
Структура программы для сервера
Главной задачей сервера является опрос все заданных по адресам узлов на доступность к приему данных. После подтверждения со стороны узла, сервер определяет количество работоспособных узлов в сети и приступает к запуску механизма передачи узлам данных. Алгоритм работы представлен на рис. 6.
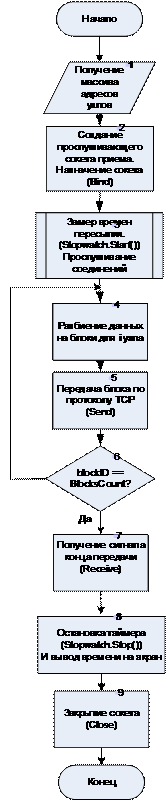
Рис. 6. Алгоритм работы сервера.
Узел создает слот прослушивания, на который приходит сигнал от сокета после чего осуществляет прием данных от сервера. В табл. 3 представлены основные функции для программы узла (serv.exe).
Таблица 3 – описание функций программы для сервера
|
Имя функции |
Описание функции |
|
Listener( int query ) |
Функция создания прослушивающего сокета, с очередью длинной query. |
|
Sеnd(int ID) |
Процедура отправки данных с сервера |
|
Read (byte * data, int size) |
Процедура считывания данных с жесткого диска сервера |
|
CloseCockets(size) |
Процедура закрытия всех сокетов. |
|
GetIP |
Процедура получения IP адреса сервера |
Отладка и тестирование программы
Отладка производилась на двух рабочих станциях под управлением ОС windows, объединенных в локальную сеть. Программа определила доступные для подключения узлы. При заданном объеме, данные распределились по узлам и пришли все сигналы подтверждения. Был получен численный результат замера времени на пересылку данных узлам.
В результате запуска программы на доступном оборудовании, описанном в п. 1.5 данной работы. Замеры производились неоднократно. Результаты замеров представлены в табл. 4.
Таблица 4. Результаты временных замеров.
|
Номер замера |
Размер передаваемых данных в б |
Результат в мс |
|
1 |
502838000 |
82857 |
|
2 |
502838000 |
81342 |
|
3 |
502838000 |
81451 |
|
4 |
502838000 |
81627 |
|
5 |
502838000 |
82635 |
В итоге, как и предполагалось результаты временных затрат оказались чуть выше теоретически полученных. Это отражает характер работы при передаче – ненагруженный и разделяемы с возможными другими передачами данных. Полученные результаты соответствуют ожидаемому.
Литература
1. Distributed computing // URL: http://en.wikipedia.org/wiki/Distributed_computing
2. Simon Haykin, Neural Network a comprehensive foundation(2nd edition), Prentice Hall, 842 pages, 1998
3. N. Sundararajan, P. Saratchandran, Parallel architectures for Artificial Neural Networks, Wiley-IEEE Computer Society Press, 412 pages, 1998
4. GitHub // URL: http://github.com/s74/disann.
5. Distributed computing on internet // URL: http://fgouget.free.fr/distributed/index-en.shtml 6. Lisandro Daniel Dalcin, Techniques for High-Performance distributed computing in computational fluid mechanics, CIMEC Document Repository, 102 pages, 2008.
6. Mlclass.ru (Электронный ресурс)
7. http://www.osp.ru/os/2013/08/13037858/ (Электронный ресурс)
8. machinelearning.ru К. В. Воронцов. Машинное обучение. Курс лекций. (Электронный ресурс)
9. Абросимов А. И. Базисные методы проектирования и анализа сетей ЭВМ. 2015г.
10. Jon Skeet. C# in Depth, 3rd Edition. 2013г.