BC/NW 2017 № 1 (30):11.1
ПРОГРАМНЫЕ СРЕДСТВА И ТЕХНОЛОГИИ ДЛЯ ПРОХОЖДЕНИЯ ПРОВЕРКИ РАСПОЗНАНИЯ CAPTCHA НА ПРИМЕРЕ IBM WATSON
Курников Д.М., Петров С.А.
На сегодняшний день сложной теоретической и практической проблемой является разработка искусственных систем распознавания графических образов. Распознавание символов в применении к CAPTCHA осложняется тем, что разработчики CAPTCHA накладывают на символы специальные эффекты, чтобы программное распознавание стало менее эффективным. Так же разрабатываются новые виды CAPTCHA, усложняющие адаптацию уже реализованных программных средств.
Капча (от CAPTCHA — англ. Completely Automated Public Turing test to tell Computers and Humans Apart — полностью автоматизированный публичный тест Тьюринга для различения компьютеров и людей) — компьютерный тест, используемый для того, чтобы определить, кем является пользователь системы: человеком или компьютером.
Универсального программного продукта для распознавания любых типов CAPTCHA не существует. Одним из популярных способов распознавания являются нейронные сети.
Для распознавания образов используются нейронные сети с различными архитектурами: состоящие из перцептронов, адаптивно резонансные сети и сети радиально-базисных функций и другие. Основой работы сети является её обучение: под определённые виды CAPTCHA необходимо применять различные алгоритмы обучения.
С точки зрения качества распознания, эффективной является сверточная сеть. Сверточная сеть использует гораздо меньшее количество настраиваемых весов, так как одно ядро весов используется целиком для всего изображения, вместо того, чтобы делать для каждого пикселя входного изображения свои персональные весовые коэффициенты. Также данная сеть поддерживает обучение с учителем и без него, что говорит о её адаптивности под различные типы задач распознавания образов.
IBM Watson способен распознавать изображения, используя самогенерируемые семантические классификаторы. В процессе обучения нейронная сеть IBM Watson может научиться распознавать объекты, события или условия среды, при помощи характеристик цвета, текстуры, формы. Предполагается, что IBM Watson способен обучиться проверке распознания CAPTCHA.
IBM Watson – это новое направление развития программных технологий разработки интеллектуальных систем - разработка когнитивных систем.
Когнитивные системы можно рассматривать как применение для передачи и обработки мыслей тех способов, которые характерны для человека. В сочетании с использованием суперкомпьютерных мощностей, они позволяют решать задачи с высокой степенью верности. Когнитивные системы обладают большей гибкостью решения задач на больших массивах информации.
У когнитивных систем, как и у человека, должны быть функции сбора, запоминания и извлечения информации, близкие к механизмам мышления человека. Можно выделить следующие оценочные системы поведения, как в следующих примерах:
· способность создавать и проверять гипотезы;
· способность разбивать на составляющие и строить логические выводы о языке;
· способность извлекать и оценивать полезную информацию (такую как даты, местоположения и характеристики).
Когнитивные процессы более высокого порядка могут достичь высокого уровня понимания, ориентируясь на основные способы поведения. Для реализации когнитивного механизма восприятия информации необходимо выполнение ее многоуровневого анализа и обработки. В качестве примера можно привести процесс понимания языка. В этом случае для понимания языка необходимо понимание более простых правил языка. К ним могут относиться не только формальная грамматика, но и неформальных соглашения, которые наблюдаются в повседневном использовании.
Большой интерес с точки зрения реализации подобной системы представляет именно система IBM Watson. Это обуславливается особой организацией системы, что позволяет сделать вывод о наибольшей степени ее когнитивности. Схема обработки знаний системой Watson приведена на рисунке 1.
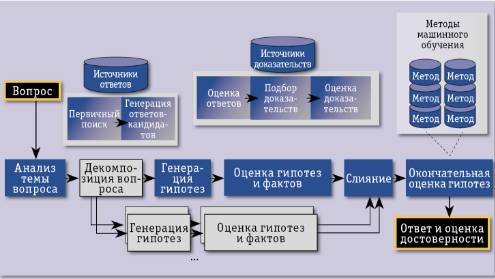
Рисунок 1. Схема обработки знаний системой Watson
Система работает в таком порядке:
1. Для выделения основных особенностей вопроса выполняется его синтаксический анализ.
2. Выполняется контекстный поиск элементов запроса по корпусу знаний Watson. На основе статистического анализа генерируется ряд гипотез о результатах, содержащих необходимый ответ.
3. Выполняется глубинное сопоставление языков запроса и возможных вариантов ответа. При этом применяются различные алгоритмы логического вывода.
4. Каждый алгоритм логического вывода выдает оценки адекватности ответа вопросу и степени его связи с ним. Результаты зависят от вида анализируемой алгоритмов предметной области.
5. Каждой полученной оценке затем присваивается весовой коэффициент на основе ряда статистических моделей. Эти модели могут применяться для определения общего уровня оценки уровня верности ответа.
6. Процесс поиска ответа п. 1-5 повторяется до тех пор, пока не будут найдены ответы, имеющие вероятность оказаться вернее, чем остальные.
Система Watson реализована на базе супер-ЭВМ IBM BlueMix. Особое значение для работы системы Watson имеет корпус знаний. Он состоит из набора неструктурированной информации. К знаниям в этом случае относят учебники, методические рекомендации, практические руководства, часто задаваемые вопросы, социальные программы и новости. В процессе обработки корпуса знаний Watson выполняет проверку его содержимого на адекватность заданному вопросу, а также актуальность и надежность источников. Это придает Watson черты когнитивной системы.
Система Watson предоставляет разработчику набор веб-инструментов Watson Experience Manager. С помощью этих инструментов можно:
- загружать документы и управлять ими;
- создавать и администрировать базу знаний;
- создать учебные данные, помогающие обучать Watson в нужной области знаний;
- тестировать Watson с помощью готового пользовательского интерфейса, задавая вопросы и читая возвращаемые ответы;
- проверять и просматривать отчеты о загруженности.
Технология Watson Q&A создает для пользователей или других систем возможность взаимодействовать с ней посредством вопросов или запросов на естественном языке. Она воспринимает естественный язык, создает гипотезы и предоставляет ответы и рекомендации с обоснованием и указанием степени достоверности. Со временем Watson «учится и становится умнее» благодаря следующим процессам:
- обучение пользователями;
- обучение с учетом предыдущих взаимодействий;
- поступление новой информации.
API вопросов и ответов Watson (QAAPI) – это интерфейс службы передачи репрезентативного состояния (REST1), который позволяет приложениям взаимодействовать с Watson. С помощью этого API можно задавать Watson вопросы, получить ответы и давать отзывы на эти ответы. Помимо простых вопросов и ответов, Watson может с помощью REST обеспечить прозрачность процесса получения своих выводов. Другие функции, такие как наполнение платформы Watson информацией, предоставляются в виде инструментов.
Ответ на отправленный вопрос включает код состояния HTTP. В синхронном режиме успешный код состояния HTTP: 200 Created. Успешный ответ также включает в себя статус завершенной обработки вопроса и ответы. В разделе ответов содержатся ответы, ранжированные по достоверности. Достоверность – это процент уверенности Watson в правильности этого ответа. Чем больше значение, тем выше достоверность. В разделе текста содержится текст каждого ответа.
Ответ также содержит дополнительные сведения по обработке данных на естественном языке (Natural language processing – NLP), в том числе категорию вопроса, фокус внимания, лексический тип ответа, список синонимов и многое другое.
Все внутренние системы IBM Watson являются закрытыми и не могут быть вызваны ни через API, ни через интерфейс. Нейронная сеть IBM Watson является самообучающейся. Какой алгоритм обучения используется внутри сети IBM Watson неизвестно. Также ничего не известно об архитектуре нейронной сети IBM Watson.
IBM Watson соединяет в себе возможности обработки естественного языка, формирования и оценки гипотез и динамического обучения, что приводит к изменению подхода к решению задач и его ускорению. Watson – это система, отвечающая на вопросы, заданные на естественном языке, которая не использует заранее подготовленные ответы, а находит их самостоятельно, основываясь на приобретенных знаниях, и дает оценку достоверности этих ответов.
Когнитивные системы ориентируются в сложностях человеческого языка и понимания, потребляют и обрабатывают огромные объемы структурированных и неструктурированных («больших») данных, создают и оценивают бесчисленные возможности, взвешивают и оценивают ответы, основанные только на релевантных свидетельствах, дают рекомендации и подают идеи в конкретных ситуациях, совершенствуют свои знания и обучаются с каждой итерацией и с каждым взаимодействием, позволяют принимать решения в точке воздействия, масштабируются пропорционально решаемой задаче. Для передачи идей и манипулирования ими эти системы применяют способности, подобные человеческим. В сочетании с преимуществами цифровых вычислений они могут решать задачи с высокой точностью, большей гибкостью и более широким охватом. Watson служит примером когнитивной системы. Он может препарировать человеческий язык и выявлять соотношения между фрагментами текста с высокой точностью на уровне способностей человека и при значительно более высоких скоростях и широких масштабах охвата, чем любой человек. Подход на основе правил для обработки каждого случая, с которым можно столкнуться в естественном языке, потребовал бы почти бесконечного количества правил.
Литература
1. Хайкин С. Нейронные сети: полный курс, 2¬e издание.:Пер. с анrл. – М. Издательский дом "Вильямс", 2006.
2. Курейчик В.М. Генетические алгоритмы. Обзор и состояние // Новости искусственного интеллекта. — 1998.