BC/NW 2018 № 2 (33):2.1
РАЗРАБОТКА ПРОГРАММЫ ДЛЯ ЭКСПЕРИМЕНТАЛЬНОГО ОПРЕДЕЛЕНИЯ ХАРАКТЕРИСТИК КЭШ-ПАМЯТИ ВЫЧИСЛИТЕЛЬНОЙ СИСТЕМЫ
Шахов В. О.
При обращении процессора напрямую к оперативной памяти за командами и данными задержки ожидания данных непозволительно велики для интенсивной обработки непрерывно запрашиваемых массивов данных, и процессору приходиться простаивать в их ожидании. Решается эта проблема включением между ОЗУ и процессором промежуточной быстродействующей памяти небольшого по сравнению с общим объемом ОЗУ размера, называемой кэш-памятью (КП).
Совершенствование структуры КП привело к тому, что она включает в себя несколько уровней, каждый имеющий свой размер, задержки и ассоциативность.
В ряде случаев (например, для тонкой оптимизации программы под конкретный процессорный модуль(ПМ) или, что важнее, под вычислительную сеть, состоящую из таких ПМ) полезно знать вышеупомянутые характеристики кэш-подсистемы.
Целью настоящей работы является создание тестового пакета, выявляющего упомянутые характеристики кэш-памяти. Таким образом в рамках работы поставлены следующие задачи:
• Изучить типичные потоки запросов и алгоритмы генерации нагрузки на кэш-память, выявляющие требуемые параметры КП.
• Реализовать алгоритмы генерации нагрузки на кэш-память.
Кэш-память состоит из блока данных и теговой памяти. Наименьшей единицей информации является страница. Блок данных состоит из набора страниц, теговая память в свою очередь устанавливает соответствие страницы в блоке данных на диске.[1]
Структура кэш-памяти представлена на Рис. 1.
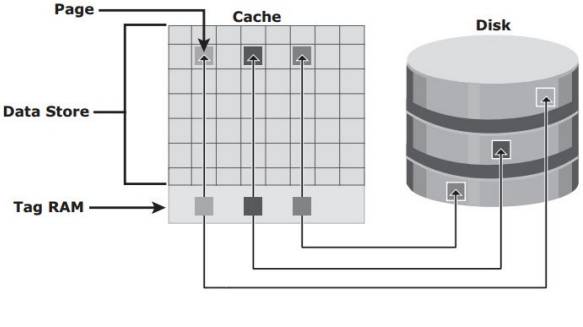
Рис. 1: Обобщенная структура КП без отображения ОЗУ и прочих уровней КП
Теговая память содержит и другую информацию. Например, флаг dirty, который показывает, соответствуют ли содержимое страницы в КП содержимому на более высоком уровне памяти, например диске, время последнего обращения, и т.д.
При поступлении запроса на чтение проверятся присутствие запрашиваемых данные в кэш-памяти. Если данные присутствуют в кэш-памяти, то это называется попаданием, read hit. В этом случае чтение занимает порядка миллисекунды, что существенно экономит время доступа к данным, т.к. не нужно обращаться к памяти на более высоком уровне. Ситуация, когда данные не содержатся в КП, называется промахом, read miss. В этом случае происходит считывание данных с диска в кэш-память, а затем эти данные посылаются хосту. Время выполнения запроса на чтение сильно увеличивается.
Запись в КП так же происходит намного быстрее, чем запись напрямую на диск. Запись обновленных в кэш-памяти данных на диск может быть организована в общем двумя способами.
1) Write-back cache: Данные записываются в кэш-память и подтверждение об успешной операции записи посылается хосту немедленно. Затем, после нескольких запросов на запись, данные записываются на диск.
2) Write-through cache: Данные записываются в КП и сразу после этого на диск. Только после этого посылается подтверждение хосту об успешно выполненной операции записи. Такой подход увеличивает время операции записи, но риск потери данных сильно снижается.
Страницам, которые были записаны в КП, но еще не записаны на диск, устанавливается флаг dirty, обозначающий, что страница в кэш-памяти не соответствуют странице на диске. Флаг dirty снимается после записи страницы на диск.
Алгоритмы управления кэш-памятью
Размер кэш-памяти ограничен, поэтому, когда КП заполнена, необходимо записывать новые данные вместо старых, находящихся в кэш-памяти. Существуют различные алгоритмы освобождения кэш-памяти. Наиболее часто используемые:
1. Least Recently Used (LRU): когда КП заполнена, и происходит обращение к не содержащейся в стеке странице, будет заменена страница, к которой не было дольше всех обращений. Страницы в кэш-памяти помечаются флагом последнего использования.
2. Most Recently Used (MRU): когда КП заполнена, и происходит обращение к странице, не содержащейся в стеке, будет вытеснена последняя использованная страница. Страницы в кэш-памяти помечаются флагом последнего использования.
Теоретический подход к решению задачи
Кэш разбит на блоки (строки): каждый блок хранится как неделимая единица, и читается из следующего уровня памяти весь целиком. Младшие биты адреса определяют смещение искомого байта в блоке кэша. Блоки обычно организованы двумерно: несколько сетов, из которых нужный выбирается по следующим младшим битам адреса, и несколько ways, из которых нужный выбирается произвольно — чаще всего, по правилу LRU. При обращении к памяти все теги требуемого сета сравниваются с тегом искомого адреса. [2]
Размер кэша равен произведению числе сетов в КП на количество линий кэша(ways) на размер этой линии кэша.
Благодаря тому, что сет выбирается по младшим битам адреса, непрерывный в памяти массив будет располагаться непрерывно и в кэше. Если массив помещается в кэше целиком, то при обращении к нему не возникает промахов: каждый следующий блок массива попадает в следующий свободный вей. При последующих проходах по массиву он весь будет читаться из кэша, и новых обращений к памяти следующего уровня не потребуется.
Если же размер массива превышает размер кэша, то в соответствии с правилом LRU первые блоки массива будут вытеснены его последними блоками.
Например, если кэш состоит из 32-х, организованных в 4 линии, а считываемый массив состоит из 35 блоков, , то первые три блока будут вытеснены. А при втором проходе по массиву первые три сета будут заполняться по-новой из следующего уровня памяти, а остальные пять сетов будут читаться прямо из кэша.
Когда размер массива превышает размер КП на целый way, данные между проходами не будут сохраняться в кэше: все обращения будут приводить к промаху и к чтению нового блока из памяти следующего уровня.
В итоге выведем следующие наблюдения:
1) пока массив меньше КП, время доступа к нему будет константой (без промахов)’
2) когда массив больше КП менее чем на один way, время доступа к нему будет зависеть от размера «излишка»;
3) когда массив больше КП на один way или больше, время доступа к нему будет константой (во всех случаях промахи) .
Поэтому, представив график(рис. 2) зависимости размера массива от времени доступа к данным каждому уровню кэша соответствует одна «уверенная» площадка на графике, и размер кэша фиксируется по значению края площадки. На графике площадки две — 32КБ и чуть более 4МБ, это говорит о том, что кэш двухуровневый.
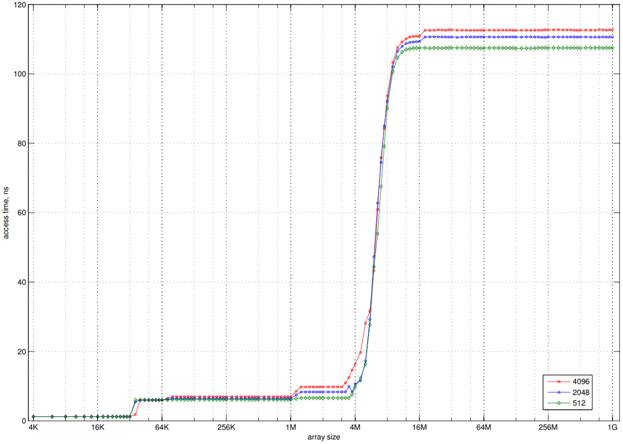
Рис. 2. График зависимости размера массива от времени доступа к данным
Теперь, по крутизне наклона площадки можно определить уровень ассоциативности КП. Если кэш не ассоциативный (прямое отображение: только один way), то размер way равен размеру КП, и 100% промахов начинаются с двукратного размера кэша. Если кэш двухвейный, то размер вея — половина от размера кэша, и правый край площадки — полтора размера кэша. Если кэш полностью ассоциативный (только один сет), то размер way равен размеру блока, и площадка переходит резко в вертикальный наклон: превышение размера КП даже на один блок приводит к 100% промахов. [3]
На данном графике(рис. 2) первая площадка ровная, а вторая довольно «размазанная». Делется вывод, что КП первого уровня разделеный для кода и данных, и поэтому каждый проход по массиву вызывает одни и те же события в КП. КП второго уровня общий, поэтому в нём располагается также и код программы, и код и данные ОС, поэтому вторая площадка начинается ещё до того, как размер массива достигнет размера КП.
Размер кэша — это тот размер массива, с которого начинается воспроизводимый линейный рост времени доступа к массиву; на данном графике(рис. 2) это 6МБ, что подтверждается и заявленными спецификациями процессора.
Нужно выбрать размер шага, т.е. блоки массива, которые будем «проходить», т.е. читать. Для одного и того же размера массива размер шага не влияет на количество промахов. Если шаг более размера блока, то в кэш будет читаться не сразу весь массив, а отдельные его блоки; часть сетов останутся свободными. Так или иначе, у нас нет промахов до тех пор, пока массив меньше кэша, и 100% промахов, если массив больше хотя-бы на один way.
В случае, когда размер шага превышает размер way: «пропущенные» ways остаются свободными, и в кэш помещаются все прочитанные блоки массива, даже если сам массив больше размера кэша. Например, для массива размером 64 блока, и шага в килобайт (16 блоков), читаются всего четыре блока, и все они попадают в один сет.
Та же ситуация всегда повторяется с полностью ассоциативным кэшем, у которого размер way совпадает с размером блока. Отличительная черта такого прохода — левый край площадки сдвигается в зависимости от размера шага: вдвое большему шагу соответствует вдвое больший «кажущийся» размер кэша, потому что каждый второй вей «пропускается».
По графику выше(рис. 2) видно, что левые края площадок совпадают для всех размеров шага — значит, размер way каждого кэша больше максимального из испробованных размеров шага, и составляет как минимум 4КБ. Для кэша L1 видим вертикальную площадки: 0% промахов для массива размером 32КБ, и 100% промахов для массива в 36КБ. Как мы видели выше, это значит, что добавка 4КБ наполняет way целиком; стало быть, размер вея — в точности 4КБ, т.е. кэш L1 состоит из 8 ways.
Будут браться данные объёма в промежутке 4КБ – 512МБ, берется среднее значение получаемого результата от миллиона проходов по массиву для каждого промежутка. Чтобы снизить к минимуму влияние действий системы, т.е. посторонних команд, аналогично способу, используемому в функции lat_mem_rd из пакета тестов для Linux lmbench [4], используем в качестве основы цикла нагрузки операцию p = (void**) *p, она компилируется всего в 1 машинную команду, и повторим её, допустим, 256 раз, для того, чтобы реже возвращаться к началу цикла. Для измерения временных интервалов используется функция архитектуры x86 __rdtsc(), она возвращает число тактов, прошедших в системе со времени старта работы процессора(64 бита). Сначала требуется определить частоту процессора, для этого нужно одновременно замерить затраченное время выполнения для некого действия и количество затребовавшихся для выполнения этого действия тактов(требуется делать это с отключенной функцией авторазгона TurboBoost, чтобы показатели давали более корректные результаты), используется функция Windows QueryPerformanceCounter(). Расчет задержек на доступ к КП осуществляется так: нужно поделить число прошедших тактов на частоту процессора в то время.
Запомнив три последних результата можно выявлять в них скачкообразные переходы, будет взят порог в 10% и больше — это левые и правые границы площадок. Сохраняя площадки, выявленные таким способом, для каждого размера шага из используемых, по завершению измерений проводится анализ, где обнаруживается количество уровней КП, их ассоциативность и их размер.
Результаты теста на процессоре Intel Core i7 4770 (4/8) c архитектурой дер Intel Haswell изображен на рисунке 3. График измеренных показателей для данного процессора изображен на рисунке 4. Судя по результатам, как и упоминают в статье о процессорах поколения Intel Ivy Bridge [5] (предыдущее перед рассматриваемым), традиционно используемая технология освобождение КП LRU была переосмысленная компанией Intel и в более высоких уровнях кэша, особенно L3, эта технология не используется, учитываются особые алгоритмы префетчинга (предвыборки) и поэтому тесты, ориентированные на работу технологии LRU, не корректно обнаруживают уровни ассоциативности (размеры weys, линий) и немного занижают размер кэша. Так по информации из работы [6] алгоритмы вытеснения в L1 и L2 кэша тоже только частично на LRU, и даже частично, в некоторых ситуациях используется алгоритм Pseudo-LRU (PLRU), он представляет собой нечто среднее из LRU и MRU.
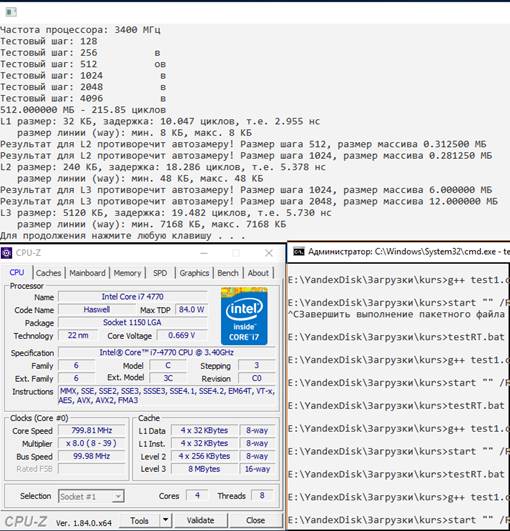
Рис. 3 Результаты теста на Intel Core i7 4770
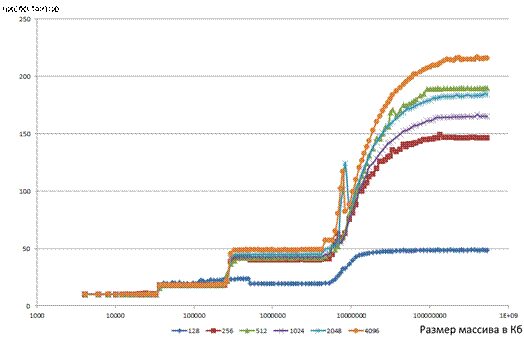
Рис. 4 График зависимости затрачиваемых тактов от размера массива для разных размеров шага для Intel i7 4770.
Результаты теста на процессоре Intel Xeon E5450 (4/4)(архитектура Intel Harprtown) изображен на рисунке 5. Как указано в презентации с конференции IBM Federal [7], у данной архитектуры L1 L2 кэши с политикой вытеснения PLRU. Так же алгоритму удается обнаружить здесь TLB (буфер ассоциативной трансляции страничной организации памяти).
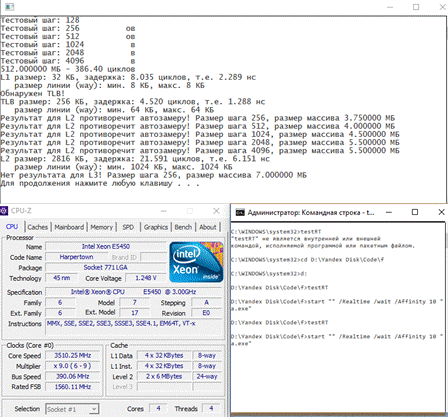
Рис. 5 Результаты теста на Intel Xeon E5450
Экспериментальным путем установлено, что многомегабайтные массивы с трудом удерживаются в памяти при работе данного теста-бенчмарка, даже с учетом высоких полномочий для выполнения процесса, фоновые системные процессы частично разрушают желаемую структуру памяти, что вносит помехи в собираемые значения. Из-за этого и того факта, что современные технологии вытеснения кэш-памяти не такие однозначные и динамически могут менять свое поведение, определение характеристик верхних уровней КП и TLB - не такая простая задача.
Литература
1. Б. Я. Цилькер, С. А. Орлов, Организация ЭВМ и систем. Учебник для вузов, 2006г, Питер, 688с
2. С. В. Морозов, В. М. Нестеров, Моделирование потока запросов на чтение и запись данных, СПБГУ 2014
3. Интернет ресурс - https://habr.com/post/111011/
4. Интернет ресурс - http://www.bitmover.com/lmbench/lat_mem_rd.8.html
5. Интернет ресурс - http://blog.stuffedcow.net/2013/01/ivb-cache-replacement/
6. Qureshi, M.K., Jaleel, A., Patt, Y.N., Steely, S.C., Emer, J.: Adaptive insertion policies for high performance caching. ACM SIGARCH Computer Architecture News 35(2), 381 (2007)
7. Koushik K Ghosh, Ph.D., IBM Systemx iDataPlex - Parallel Scientific Applications Development April 22-23, 2009