BC/NW 2018 № 2 (33):6.1
ИССЛЕДОВАНИЕ ЗАВИСИМОСТИ ВРЕМЕНИ ОБСЛУЖИВАНИЯ ЗАПРОСА ОТ МАСШТАБИРУЕМЫХ ПАРАМЕТРОВ БД
Зюзькин Е.К.
Работы в области теории систем баз данных принесли наиболее важные результаты в информатике за последние 40 лет. Из-за развития таких технологий существенно преобразовалось работа многих организаций, появились новые, хорошо себя зарекомендовавшие системы хранения и обработки информации. Технологии стали более доступными, удобными и начали использоваться более широким кругом пользователей. В то же время, благодаря упрощению работы с интерфейсом и развитию технологий, обычные пользователи начали программировать базы данных и приложения, не имея для этого соответственных знаний и навыков.
Далее речь пойдет о реляционных базах данных. Реляционная база данных представляет собой множество взаимосвязанных таблиц, каждая из которых содержит информацию об объектах определенного вида. Система SQL Server предоставляет одновременный доступ большого количества пользователей к информации, возможность редактирования, удаления и различные манипуляции с хранимой информацией. SQL Server отвечает за корректное создание объектов базы данных, безопасный доступ, а так же осуществляет проверку целостности.
1. Создание индексов в среде MS SQL Server
При определении для таблицы кластерного индекса серверу фактически отдается приказание физически отсортировать данные в порядке индекса. Поэтому у любой базовой таблицы может быть только один кластерный индекс.
Одна из важнейших особенностей кластерного индекса состоит в том, что один элемент индекса на уровне индекса соответствует странице данных и эти значения отсортированы. На уровне листа кластерного индекса страницы памяти, предназначенные для хранения индексной информации, физически совпадают со страницами данных базовой таблицы, для которой этот кластерный индекс создан. Средний размер кластерного индекса на индексном уровне составляет около 5% от размера таблицы, но может варьироваться в зависимости от размера индексируемого столбца. Когда создается кластерный индекс, SQL-сервер временно использует дисковое пространство текущей базы дынных для сортировки. Это пространство равно примерно 120-150% от размера таблицы. Когда индекс создан, используемое в процессе его создания дисковое пространство автоматически возвращается базе данных.
Итак, в кластерном индексе данные на уровне листа физически отсортированы. Каждая запись уровня листа кластерного индекса имеет так называемый уникальный ключ кластеризации. Неповторяемость ключевых значений поддерживается явно, если задано ограничение UNIQUE, или неявно с помощью ключей кластеризации на уровне, недоступном пользователю. Подобная организация данных приведена на рисунке. (Рисунок 1.1)
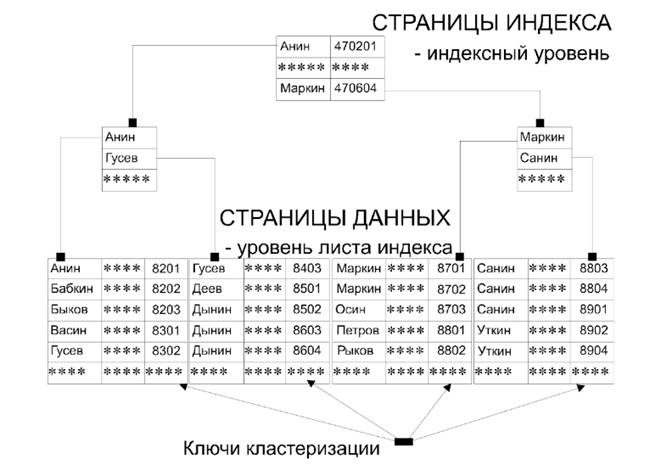
Рисунок 1.1 Структура организации кластерного индекса
Для кластерного индекса характерно, что индекс этого типа и данные совместно
используют одну и ту же запись в системной таблице sysindexes.
Механизм реализации некластерных индексов
Разумеется, одного индекса для таблицы недостаточно, т.к. при работе с базой данных приходится обращаться к данным разными способами. Некластерные индексы позволяют организовывать доступ к данным с использованием В-дерева в порядке, который отличен от порядка физической сортировки данных. Другими словами, некластерный индекс – это физический объект, задающий логический порядок сортировки данных в базовой таблице. Некластерных индексов у таблицы может быть несколько (до 249).
Важнейшая особенность некластерных индексов заключается в том, что один элемент индекса приходится на одну запись данных.
Для способа реализации некластерного индекса является важным то обстоятельство, строится ли он поверх кластерного индекса или нет. В последнем случае говорят, что некластерный индекс построен поверх кучи.
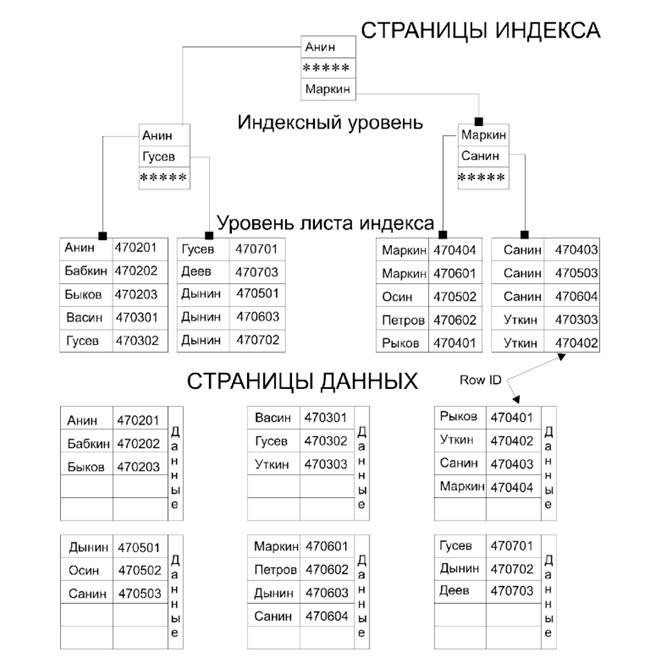
Рисунок 1.2. Структура организации некластерных индексов
Разработка тестовой базы данных
Создание базы данных выполнено с помощью инструментального средства Microsoft SQL Server Management Studio.
В качестве тестовой базы данных используется тестовая база данных, некоего сайта, в которой в трех таблицах находится информация о пользователях.
Первая таблица «General_info»
Вторая таблица «Login_info»
Третья таблица «Password_info»
Ниже приведен скрипт создания необходимых таблиц.
CREATE TABLE [dbo].[General_info](
[id] [INT] NOT NULL,
[First name] [NCHAR](12) NOT NULL,
[Last name] [NCHAR](12) NOT NULL,
[Phone number] [NCHAR](11) NOT NULL,
[E-mail] [NCHAR](25) NOT NULL,
CONSTRAINT [PK_General_info] PRIMARY KEY CLUSTERED
(
[id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
CREATE TABLE [dbo].[Login_info](
[id_user] [INT] NOT NULL
[Login] [NCHAR](17) NOT NULL
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Login_info] WITH CHECK ADD CONSTRAINT [FK_Login_info_General_info] FOREIGN KEY([id_user])
REFERENCES [dbo].[General_info] ([id])
GO
ALTER TABLE [dbo].[Login_info] CHECK CONSTRAINT [FK_Login_info_General_info]
CREATE TABLE [dbo].[Pass_info](
[id_user1] [INT] NOT NULL,
[Password] [NCHAR](12) NOT NULL
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Pass_info] WITH CHECK ADD CONSTRAINT [FK_Pass_info_General_info] FOREIGN KEY([id_user1])
REFERENCES [dbo].[General_info] ([id])
GO
ALTER TABLE [dbo].[Pass_info] CHECK CONSTRAINT [FK_Pass_info_General_info]
Для заполнения данных таблиц нужными значениями прибегнем к программному инструменту ApexSQL Generate. Программа без проблем быстро генерирует тестовые данные для необходимых таблиц.
В таблицу «General_info» было внесено 10 000 000 различных данных, в «Login_info» внесено 1 000 000 записей и в «Pass_info» внесено 100 000 записей.
Сделано это для того, чтобы можно было сравнить время выполнения запроса к различным таблицам, и на основе этого уже делать выводы.
2 Логическая модель тестовой БД
На основе модели «сущность-связь» создадим логическую модель данных (Рисунок 2.3). Логическая модель отображает взаимосвязи между реляционными таблицами.
В каждой таблице базы данных создано ключевое поле «Id» через которое реализуются отношения таблиц в базе данных.
Рассмотрим отношения между таблицами в логической модели. Таблицы «General_info» и «Login_info» находятся в отношении 1:1 (один-к-одному), так как один логин может принадлежать одному человеку. Таблицы «General_info» и «Pass_info» находятся в отношении 1:1, так как пароль 1 человек имеет один пароль.
Разработанная модель находится в 3-ей нормальной форме т.к.:
· атрибуты сущностей являются атомарными;
· каждый неключевой атрибут функционально полно зависит от первичного ключа;
· в модели отсутствуют транзитивные зависимости неключевых атрибутов от ключа.
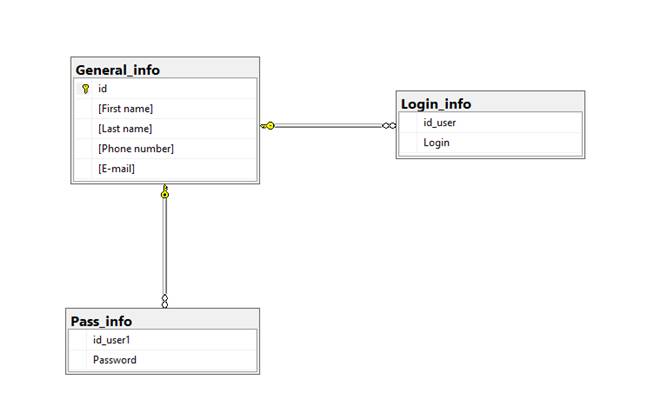 Рисунок 2.1
Логическая модель данных
Рисунок 2.1
Логическая модель данных
3.Физическая модель тестовой БД
Физическая модель базы данных представлена на рисунке (Рисунок 3.1).
База данных состоит из следующих таблиц:
· General_info – хранит следующую информацию о пользователях : id, First name (Имя), Last name (Фамилия), Phone number (Номер телефона), E-mail
· Login_info – хранит список Логинов пользователей;
· Pass_info – хранит список Паролей пользователей;
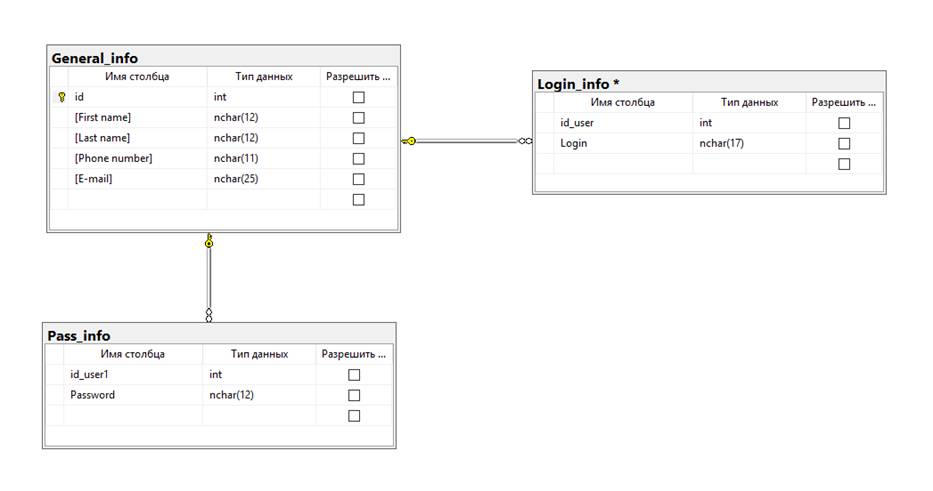
Рис. 3.1 Физическая модель данных
4. Разработка стенда для проведения исследования
Проведение исследований будет проводится на девяти различных машинах, характеристики которых представлены в таблице (Таблица 4.1)
Таблица 4.1
|
|
Процессор |
Оперативная память |
Внутренний накопитель |
Видеокарта |
|
1
|
AMD fx8350 (4.0 Ггц) |
8 ГБ (667 МГц) |
1 Tб HDD |
GeForce GTX560Ti (1 Гб) |
|
2
|
AMD fx8350 (4.0 Ггц) |
8 ГБ (667 МГц) |
60 Гб SSD |
GeForce GTX560Ti (1 Гб) |
|
3
|
AMD fx8350 (4.0 Ггц) |
16 Гб (667 МГц) |
1 Tб HDD |
GeForce GTX560Ti (1 Гб) |
|
4
|
AMD fx8350 (4.0 Ггц) |
8 Гб (667 МГц) |
1 Tб HDD |
AMD Radeon R9 280x (3 Гб) |
|
5
|
AMD fx8350 (3.8 Ггц) |
8 Гб (667 МГц) |
1 Tб HDD |
GeForce GTX560Ti (1 Гб) |
|
6
|
AMD fx8350 (4.7 Ггц) |
8 Гб (667 МГц) |
1 Tб HDD |
GeForce GTX560Ti (1 Гб) |
|
7
|
AMD fx8350 (4.0 Ггц) |
8 Гб (1333 МГц) |
1 Tб HDD |
GeForce GTX560Ti (1 Гб) |
|
8
|
AMD fx8350 (4.4 Ггц) |
16 Гб (1333 МГц) |
1 Tб HDD |
GeForce GTX560Ti (1 Гб) |
Исследования на первых семи машинах необходимы, чтобы понять, какие параметры в конфигурации персонального компьютера/сервера будут влиять на время обслуживания запроса.
Машина 8 необходима, чтобы сверить время обслуживания запроса на нем, и на первом стенде, для того чтобы наглядно была видна разница.
Наблюдения будут проводиться в одной сборке MS SQL Server и на одной операционной системе «Windows 10». Для чистоты эксперимента, систему не будут «грузить» различные приложения, а так же будут отключены антивирусы.
5. Результаты тестирования
Для начала проверим, как влияет размерность таблицы на время обслуживания запроса, и как влияет кластеризованный индекс на скорость обслуживания запроса
Для начала выполним поиск, выбирая все значения из диапазона обозначенных Phone_number, среди 10 000 000 записей (в таблице «General_info»)
Первый запрос будет состоять из 100 000 записей, чтобы впоследствии можно было сравнить этот запрос с запросом к таблице “Pass_Info” и понять, влияет ли размерность таблицы на время обслуживания запроса или нет.
USE test
set statistics time on
SELECT * FROM dbo.General_info WHERE [Phone number] BETWEEN '111-111-111' AND '204-408-000' ;
set statistics time off
Первый запрос занял 1,547 с., второй 1,358 с., третий запрос занял 1,297 с.
Теперь выполним аналогичный запрос к таблице, содержащей 1 000 000 («Login_info») записей, только теперь поиск будет по значению id_user
Запрос на выборку 100 000 значений для того чтобы понять, влияет ли размерность таблицы на время обслуживания запроса.
USE test
set statistics time on
SELECT * FROM dbo.Login_info WHERE id_user BETWEEN 1 AND 100000;
set statistics time off
Первый запрос занял 0,234 с., второй 0,170 с., третий запрос занял 0,127 с.
Последним будет запрос к таблице «Pass_info» с выборкой 100 000 значений, поиск по id_user1.
USE test
set statistics time on
SELECT * FROM dbo.Pass_info WHERE id_user1 BETWEEN 1 AND 100000;
set statistics time off
Первый запрос занял 0,031 с., второй 0,016 с., третий запрос занял 0,015 с.
Для дальнейшего сравнения будем использовать среднее значение из полученных результатов тестирования.
Исходя из результатов можно сделать вывод, что чем меньше таблица, тем быстрее выполняется обслуживание запроса (рисунок 5.1)
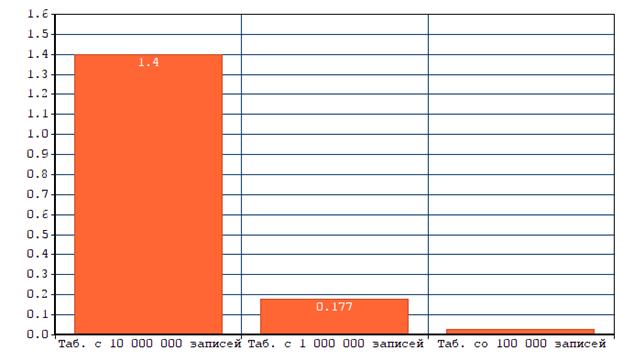
Рисунок 5.1
Далее протестируем, влияет ли поиск по первичному ключу (кластерный индекс), на время обслуживания запроса или нет.
Первый запрос будет к таблице с 10 000 000 записей, в котором мы выберем все значения таблицы, отсортированные по убыванию. Поиск будет проводится по первичному ключу id (кластерный индекс).
USE test
set statistics time on
SELECT * FROM dbo.General_info ORDER BY id desc;
set statistics time off
Первый запрос занял 5,928 с., второй 5,883 с., третий запрос занял 5,625 с.
Второй запрос будет к той же таблице, значения вновь должны быть отсортированы по убыванию. Поиск по номеру телефона (без индекса)
USE test
set statistics time on
SELECT * FROM dbo.General_info ORDER BY [Phone number] desc;
set statistics time off
Первый запрос занял 58,767 с., второй 56,437 с., третий запрос занял 55,945 с.
Исходя из полученных данных, можно сказать, что поиск по кластерному индексу в разы быстрее, чем поиск по столбцу без индекса (Рисунок 5.2).
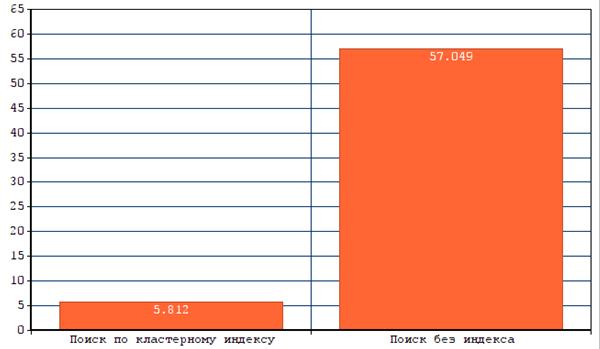
Рисунок 5.2
Теперь выполним два одинаковых запроса к таблице «General_info». Разница будет в том, что первый запрос будет применен к непроиндексированному столбцу «Phone_number», а второй будет применен уже к этому же столбцу, после того, как мы присвоим ему некластерный индекс.
USE test
set statistics time on
SELECT [Phone number] FROM dbo.General_info ORDER BY [Phone number] desc;
set statistics time off
Первый запрос занял 49,561 с., второй 47,986 с., третий запрос занял 47,608 с.
USE test
set statistics time on
SELECT [Phone number] FROM dbo.General_info ORDER BY [Phone number] desc;
set statistics time off
Первый запрос занял 2,921 с., второй 2,683 с., третий запрос занял 2,469 с.
Исходя из полученных результатов, можно сделать вывод, что некластерный индекс очень сильно ускоряет время обслуживания запроса. (Рисунок. 5.3)
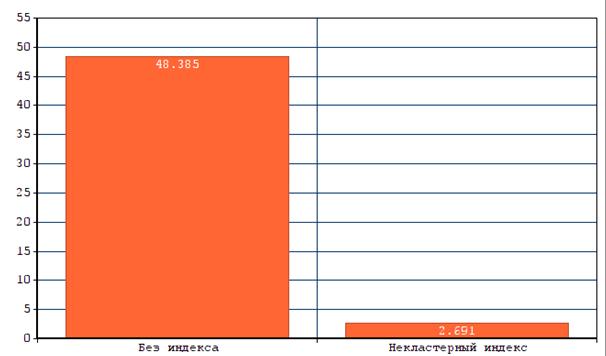
Рисунок 5.3
Теперь попробуем вставить 100 000 значений в таблицу, где все столбцы проиндексированы, и в таблицу, где индексы отсутствуют. Для этого воспользуемся командой «Insert»
Время выполнения вставки значений для непроиндексированной таблицы составило в среднем 0.825с.
Время выполнения вставки значений для непроиндексированной таблицы составило в среднем 4.762с.
Исходя из полученных результатов, можно сделать вывод, что чрезмерная индексация не всегда полезна, а даже наоборот, может очень сильно замедлить скорость работы базы данных (Рисунок 5.4).
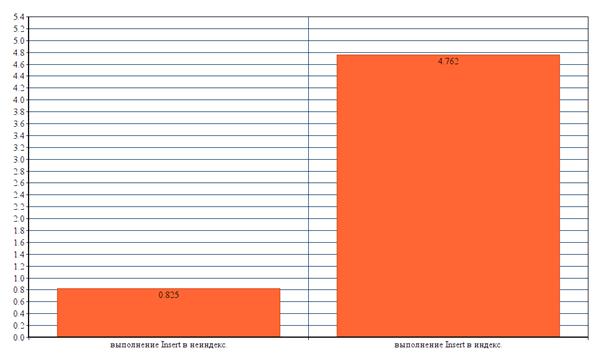
Рисунок 5.4
Далее будем проводить исследования на компьютере, с разным железом, чтобы определить, какие комплектующие и как влияют на время обработки запроса.
1 стенд
Все характеристики представлены в таблице (Таблица 4.1)
Запросим все значения из таблицы «General_info», для этого воспользуемся следующим запросом:
USE test
set statistics time on
SELECT * FROM dbo.General_info;
set statistics time off
Первый запрос занял 5,594 с., второй 5,516 с., третий запрос занял 5,469 с.
Далее запросим все значения, сразу из трех таблиц, для этого воспользуемся запросом:
USE test
SET STATISTICS TIME ON;
SELECT dbo.General_info.id, dbo.General_info.[First name], dbo.General_info.[Last name], dbo.General_info.[Phone number], dbo.General_info.[E-mail], dbo.Login_info.Login, dbo.Pass_info.Password
FROM dbo.General_info, dbo.Login_info, dbo.Pass_info
WHERE dbo.General_info.id = dbo.Login_info.id_user AND dbo.General_info.id = dbo.Pass_info.id_user1
SET STATISTICS TIME OFF;
Первый запрос занял 0,593 с., второй 0,500 с., третий запрос занял 0,484 с.
2 стенд
Различия между первым и вторым заключается в накопителе данных. Во втором стенде используется твердотелый накопитель (SSD), вместо HDD у первого.
Запросим все значения из таблицы «General_info»:
USE test
set statistics time on
SELECT * FROM dbo.General_info;
set statistics time off
Первый запрос занял 6,594 с., второй 6,216 с., третий запрос занял 6,127 с.
Далее запросим все значения, сразу из трех таблиц, для этого воспользуемся запросом:
USE test
SET STATISTICS TIME ON;
SELECT dbo.General_info.id, dbo.General_info.[First name], dbo.General_info.[Last name], dbo.General_info.[Phone number], dbo.General_info.[E-mail], dbo.Login_info.Login, dbo.Pass_info.Password
FROM dbo.General_info, dbo.Login_info, dbo.Pass_info
WHERE dbo.General_info.id = dbo.Login_info.id_user AND dbo.General_info.id = dbo.Pass_info.id_user1
SET STATISTICS TIME OFF;
Первый запрос занял 0,517 с., второй 0,461 с., третий запрос занял 0,410 с.
Результаты для сравнения двух стендов представлены на рисунке (Рисунок 5.5).
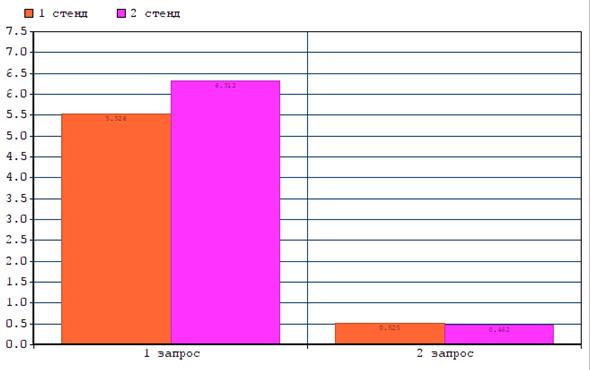
Рисунок 5.5
По представленному выше изображению, можно утверждать, что для больших объемов баз данных, лучше использовать HDD Диски, а если база данных небольшого размера (в нашем примере 100 000 записей), то быстрее с выполнением справляется SSD накопитель.
3 стенд
Отличие от первого стенда состоит в том, что в нём установлено больше оперативной памяти (16Гб, вместо 8Гб)
Запросим все значения из таблицы «General_info»:
USE test
set statistics time on
SELECT * FROM dbo.General_info;
set statistics time off
Первый запрос занял 5,406 с., второй 5,216 с., третий запрос занял 4,896 с.
Далее запросим все значения, сразу из трех таблиц, для этого воспользуемся запросом:
USE test
SET STATISTICS TIME ON;
SELECT dbo.General_info.id, dbo.General_info.[First name], dbo.General_info.[Last name], dbo.General_info.[Phone number], dbo.General_info.[E-mail], dbo.Login_info.Login, dbo.Pass_info.Password
FROM dbo.General_info, dbo.Login_info, dbo.Pass_info
WHERE dbo.General_info.id = dbo.Login_info.id_user AND dbo.General_info.id = dbo.Pass_info.id_user1
SET STATISTICS TIME OFF;
Первый запрос занял 0,523 с., второй 0,481 с., третий запрос занял 0,447 с.
Результаты для сравнения двух стендов представлены на рисунке (Рисунок 5.6).
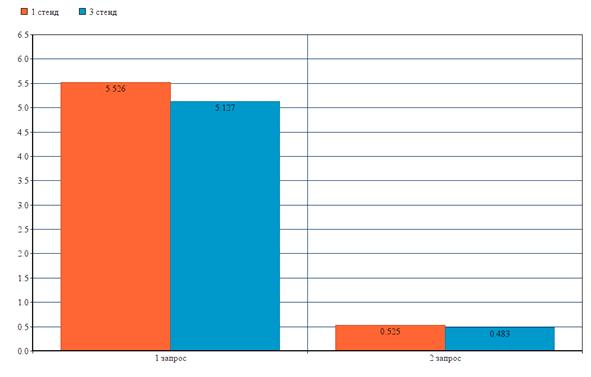
Рисунок 5.6
По представленному выше изображению, можно сделать вывод, что оперативная память положительно влияет на время обслуживания запроса.
4 стенд
Различия между первым и четвертым стендом заключаются в видеокарте.
Запросим все значения из таблицы «General_info»:
USE test
set statistics time on
SELECT * FROM dbo.General_info;
set statistics time off
Первый запрос занял 5,597 с., второй 5,540 с., третий запрос занял 5,496 с.
Далее запросим все значения, сразу из трех таблиц, для этого воспользуемся запросом:
USE test
SET STATISTICS TIME ON;
SELECT dbo.General_info.id, dbo.General_info.[First name], dbo.General_info.[Last name], dbo.General_info.[Phone number], dbo.General_info.[E-mail], dbo.Login_info.Login, dbo.Pass_info.Password
FROM dbo.General_info, dbo.Login_info, dbo.Pass_info
WHERE dbo.General_info.id = dbo.Login_info.id_user AND dbo.General_info.id = dbo.Pass_info.id_user1
SET STATISTICS TIME OFF;
Первый запрос занял 0,585 с., второй 0,512 с., третий запрос занял 0,483 с.
Результаты для сравнения двух стендов представлены на рисунке (Рисунок 5.7).
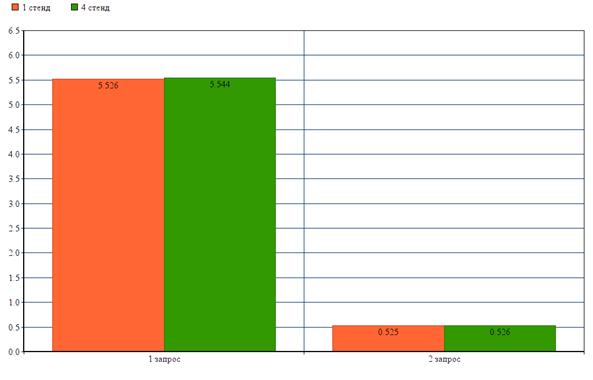
Рисунок 5.7
По представленному выше изображению, можно сделать вывод, что видеокарта никак не влияет на скорость выполнения запроса.
5 стенд
Различия между первым и пятым стендом заключаются в пониженной тактовой частоте процессора у последнего.
Запросим все значения из таблицы «General_info»:
USE test
set statistics time on
SELECT * FROM dbo.General_info;
set statistics time off
Первый запрос занял 6,209 с., второй 6,040 с., третий запрос занял 5,986 с.
Далее запросим все значения, сразу из трех таблиц, для этого воспользуемся запросом:
USE test
SET STATISTICS TIME ON;
SELECT dbo.General_info.id, dbo.General_info.[First name], dbo.General_info.[Last name], dbo.General_info.[Phone number], dbo.General_info.[E-mail], dbo.Login_info.Login, dbo.Pass_info.Password
FROM dbo.General_info, dbo.Login_info, dbo.Pass_info
WHERE dbo.General_info.id = dbo.Login_info.id_user AND dbo.General_info.id = dbo.Pass_info.id_user1
SET STATISTICS TIME OFF;
Первый запрос занял 0,663 с., второй 0,582 с., третий запрос занял 0,541 с.
Результаты для сравнения двух стендов представлены на рисунке(Рисунок 5.8).
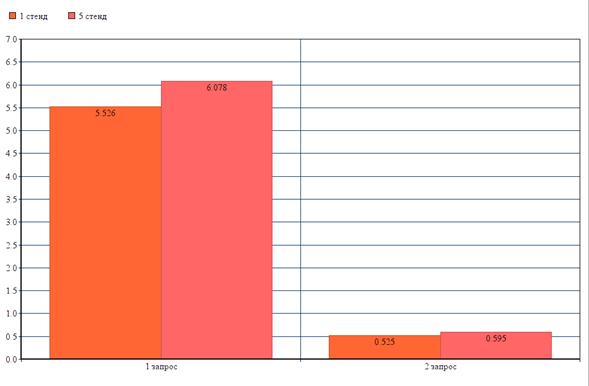
Рисунок 5.8
По представленному выше изображению, можно сделать вывод, низкая частота процессора отрицательно влияет на время обслуживания запроса.
6 стенд
Различия между первым и шестым стендом заключаются в повышенной тактовой частоте процессора у последнего.
Запросим все значения из таблицы «General_info»:
USE test
set statistics time on
SELECT * FROM dbo.General_info;
set statistics time off
Первый запрос занял 4,439 с., второй 4,371 с., третий запрос занял 4,106 с.
Далее запросим все значения, сразу из трех таблиц, для этого воспользуемся запросом:
USE test
SET STATISTICS TIME ON;
SELECT dbo.General_info.id, dbo.General_info.[First name], dbo.General_info.[Last name], dbo.General_info.[Phone number], dbo.General_info.[E-mail], dbo.Login_info.Login, dbo.Pass_info.Password
FROM dbo.General_info, dbo.Login_info, dbo.Pass_info
WHERE dbo.General_info.id = dbo.Login_info.id_user AND dbo.General_info.id = dbo.Pass_info.id_user1
SET STATISTICS TIME OFF;
Первый запрос занял 0,427 с., второй 0,402 с., третий запрос занял 0,400 с.
Результаты для сравнения двух стендов представлены на рисунке (Рисунок 5.9).
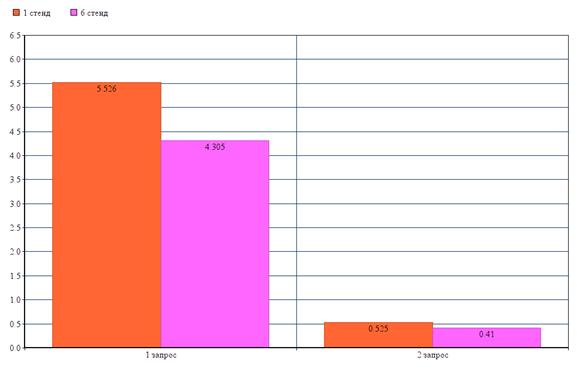
Рисунок 5.9
По представленному выше изображению, можно сделать вывод, что повышение тактовой частоты процессора значительно ускоряет время обслуживания запроса.
7 стенд
Различия между первым и седьмым стендом заключаются в повышенной частоте оперативной памяти у последнего (1333 МГц, вместо 667МГц).
Запросим все значения из таблицы «General_info»:
USE test
set statistics time on
SELECT * FROM dbo.General_info;
set statistics time off
Первый запрос занял 5,263 с., второй 5,117 с., третий запрос занял 5,082 с.
Далее запросим все значения, сразу из трех таблиц, для этого воспользуемся запросом:
USE test
SET STATISTICS TIME ON;
SELECT dbo.General_info.id, dbo.General_info.[First name], dbo.General_info.[Last name], dbo.General_info.[Phone number], dbo.General_info.[E-mail], dbo.Login_info.Login, dbo.Pass_info.Password
FROM dbo.General_info, dbo.Login_info, dbo.Pass_info
WHERE dbo.General_info.id = dbo.Login_info.id_user AND dbo.General_info.id = dbo.Pass_info.id_user1
SET STATISTICS TIME OFF;
Первый запрос занял 0,553 с., второй 0,512 с., третий запрос занял 0,461 с.
Результаты для сравнения двух стендов представлены на рисунке (Рисунок 5.10).
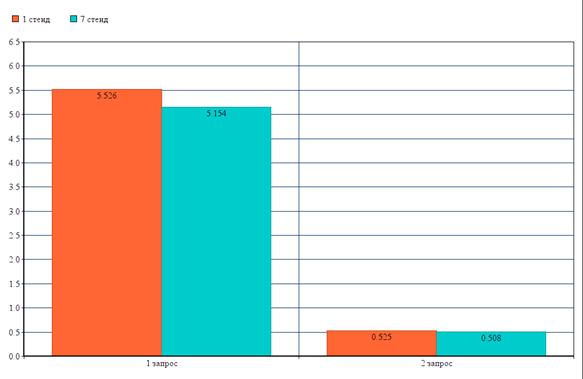
Рисунок 5.10
По представленному выше изображению, можно сделать вывод, что повышение частоты оперативной памяти хоть и не сильно, но повышает время обслуживания запроса.
8 стенд
Теперь сравним 1 стенд (стандартная, самая простая конфигурация), с 8 стендом (усовершенствованная, разогнанная сборка).
Запросим все значения из таблицы «General_info», для этого воспользуемся следующим запросом:
USE test
set statistics time on
SELECT * FROM dbo.General_info;
set statistics time off
Первый запрос занял 3,404 с., второй 3,346 с., третий запрос занял 3,201 с.
Далее запросим все значения, сразу из трех таблиц, для этого воспользуемся запросом:
USE test
SET STATISTICS TIME ON;
SELECT dbo.General_info.id, dbo.General_info.[First name], dbo.General_info.[Last name], dbo.General_info.[Phone number], dbo.General_info.[E-mail], dbo.Login_info.Login, dbo.Pass_info.Password
FROM dbo.General_info, dbo.Login_info, dbo.Pass_info
WHERE dbo.General_info.id = dbo.Login_info.id_user AND dbo.General_info.id = dbo.Pass_info.id_user1
SET STATISTICS TIME OFF;
Первый запрос занял 0,391 с., второй 0,372 с., третий запрос занял 0,368 с.
Результаты для сравнения двух стендов представлены на рисунке (Рисунок 5.11).
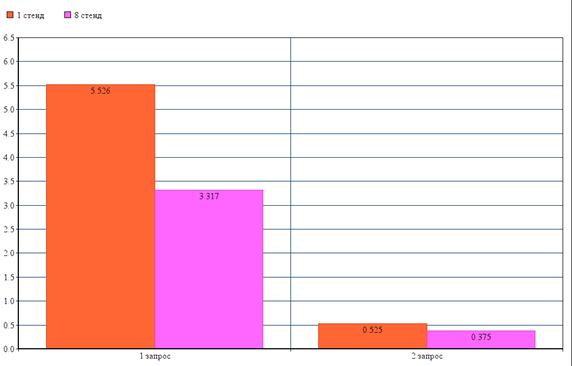
Рисунок 5.11
По представленному выше изображению, можно видеть, как сильно изменяется время выполнения запроса, если подобрать правильные комплектующие.
Заключение
К работе с индексами нужно подходить с головой. Конечно, они отлично себя показывают, если выполнять запросы на обработку данных оператором SELECT, но как только дело дойдет до операторов INSERT, UPDATE и DELETE, то дело принимает сразу другой оборот.
Во время инициирования запроса с помощью оператора SELECT, подсистема запросов отыскивает индекс, двигается по его древовидной структуре и находит необходимые нам данные. Но все будет по-другому, если с инициировать такой оператор как UPDATE. Несомненно, для первой части этого оператора подсистема запросов может снова воспользоваться индексом, чтобы обнаружить модифицируемую строку – это отличная новость. Даже если произойдет обычное изменение данных в строке, которое не будет затрагивать изменение в ключевых столбцах, то процесс изменения будет выполнен без каких-либо проблем. Но стоит учесть, что, если наше изменение будет причиной разделения страниц(которые содержат данные), или значение ключевого столбца будет модифицировано, приведя к переносу его в другой индексный узел – всё это будет способствовать тому, что индекс будет нуждаться в реорганизации, которая будет затрагивать все операции и связанные индексы, в результате производительность базы данных очень сильно упадет
Абсолютно также база данных реагирует на вызов
такого оператора как DELETE. Индекс поможет в поиске расположения
данных, которые необходимо удалить, но удаление данных как таковое приведет.
Теперь непосредственно про INSERT, к которому я обращался в своей
исследовательской работе. INSERT – главный враг всех индексов: если добавлять огромное
количество данных в таблицу, это вызовет изменение индексов с последующей
реорганизацией, и скорость работы существенно упадет..
Поэтому всегда необходимо учитывать какие
запросы будут часто использоваться в базе данных, чтобы понять, какие и сколько
индексов необходимо создать. Больше не значит лучше. Перед добавлением нового
индекса на таблицу необходимо просчитать стоимость не только обычных запросов,
но и объем который займет индекс на диске, стоимость поддержания
работоспособности и индексов, что может привести к эффекту домино для других
операций. Стратегия создания индексов один самых важных аспектов внедрения и
должна включать в рассмотрение множество соображений: от размера индекса,
количества уникальных значений, до типа поддерживаемых индексом запросов.
Основные факторы, которые влияют на производительность программы, распределены, исходя из своего приоритета:
1. Вид базы данных;
2. Параметры и настройка SQL сервера;
3. Частота процессора на локальной рабочей станции;
4. Количество свободной памяти в системе локальной станции;
5. Дополнительное ПО, антивирусы и др.;
6. Скорость дисков на локальной станции;
7. Другие факторы.
Вид базы данных
Самый важный параметр для производительности системы – вид базы данных. Практика показывает, что работа со SQL сервером во много раз быстрее работы в базе данных Access. В качестве дополнительного условия можно отметить и вид SQL сервера. Так, например, работа с MS SQL сервером значительно быстрее работы с MySQL сервером. Microinvest позволяет осуществлять миграцию данных от одного сервера к другому. Таким образом, можно серьезно оптимизировать производительность системы.
Параметры и настройка SQL сервера
Кроме вида базы данных, большое значение имеет и правильность конфигурации SQL сервера. Серверы очень чувствительны к оперативной памяти, мощности центрального процессора и другим параметрам компьютерной конфигурации. Желательно следовать указаниям производителя SQL сервера для достижения максимальной производительности. От этого зависит и скорость работы продуктов MS SQL Server.
Частота процессора локальной рабочей станции
При правильно настроенной и проворной базе данных, производительность системы начинает зависеть от скорости процессора локальной рабочей станции. Продукты MS SQL Server могут использовать все ядра в многоядерных процессорах, тем самым, имеют все преимущества самых современных технологий. Скорость процессора рабочей станции является определяющей для комфортной работы продукта.
Количество свободной памяти в системе на локальной станции
Новые технологии требуют использования достаточного количества RAM, поэтому наличие подходящего объема оперативной памяти является гарантией скорости работы системы. Специальное внимание обращено к повторяющимся операциям, они сохраняются в оперативной памяти, и операторы чувствуют эту оптимизацию в своей ежедневной работе. Например, в качестве такого действия можно отметить печать документов. Первый документ выходит на экран через определенное время, после чего остальные документы начинают загружаться во много раз быстрее, т.к. они активируются оперативной памятью.
Дополнительное ПО, антивирусы и прочее
Антивирусные системы и другое дополнительное ПО влияют на скорость работы программы. Если при каждой операции проверяется наличие вируса, при открытии каждого документа проверяются макросы, то ресурсы системы загружаются, без реальной на то необходимости. Поэтому желательно правильно проектировать защитные и дополнительные программы. Такая разгрузка системы может в большой степени изменить всю производительность.
Скорость дисков локальной станции
При каждой операции совершается чтение и запись данных. Поэтому скорость работы жесткого диска локальной станции имеет значение. Быстрые диски обеспечивают более хорошую производительность системы, особенно при работе с локальной базой данных, где все сохраняется на том же компьютере.
Другие факторы
Существует ряд других факторов, которые определяют скорость работы системы. Несмотря на то, что их значение не столь высоко, скорость определяется и исходя из следующих условий:
· Одновременный запуск большого количества разных приложений ухудшает общую скорость системы. Желательно иметь минимальное количество одновременно запущенных программ;
· Сильно фрагментированные диски увеличивают входящие и исходящие операции и уменьшают скорость работы. На практике хорошо, когда дефрагментирование дисков совершается периодически;
· Неподходящий драйвер для определенного устройства может привести к резкому спаду производительности системы. Желательно устанавливать точные драйверы для устройств.