BC/NW 2019 № 1 (34):12.1
РАЗРАБОТКА СРЕДСТВ ДЛЯ ВЫДЕЛЕНИЯ В ВИДЕОПОТОКЕ РЕДАКТИРУЕМЫХ ОТРЕЗКОВ НА ОСНОВЕ НЕЙРОСЕТЕЙ
Троян Д.Ю., Абросимов Л.И.
Исследования производились в связи с проблемой недостаточной производительности редакторов телеканала НТВ, которая возникает вследствие значительных временных затрат на неавтоматизированный поиск необходимых отрезков видеозаписи в режиме непосредственного видеопросмотра и их последующую обработку.
Редакторы телепрограмм тратят много времени на поиск времени начала, конца видеоконтента и прерываний на рекламные вставки.
Целью разработки является повышение производительности работы редакторов телеканала при повышении точности поиска требуемых отрезков видеозаписи, используя нейронные сети в качестве основного средства решения проблемы существующих методов классификации изображений.
Актуальность решаемой задачи определяется недостаточной производительностью редакторов телеканала, возникающей вследствие значительных временных затрат на поиск необходимых моментов времени в видеозаписи двадцати четырёх часового, разделенного на отрезки по одному часу, эфира телеканала с целью его последующего редактирования и размещения на ресурсах телеканала, иначе выражаясь на сайте и в социальных сетях. Проблему можно сформулировать в двух тезисах:
1. Редакторы тратят много времени на поиск времени начала, конца и прерываний на рекламные вставки.
2. Запись эфира делится не по содержанию передачи а на отрезки по одному часу, что приводит к увеличению времени на поиск необходимых отрезков и их последующую обработку.
Основная проблема реализации данного проекта состоит в отсутствии программного алгоритма, способного, опираясь на видеоряд, распознать и различить:
o “контент” подлежащий редактированию, иными словами: передачи, прямые эфиры и записи фильмов и сериалов,
o партнерский контент: побочный материал, включающий в себя, рекламные ролики. Другими словами, телеканал не может предоставить достоверной информации о содержании эфира на данный момент.
При этом нельзя полагаться на расписание, по той причине, что в расписании указано “округленное” время начала передачи и не обозначено время, когда она прерывается на рекламную паузу. Так же исходящий поток RTMP не содержит меток, которые указывают на содержание эфира.
Решение задачи облегчается тем, что во время показа рекламы, картинка, (или видеоряд) не содержит логотип телеканала, Поэтому задача сводится к тому, чтобы разработать программный комплекс, способный определять контекст эфира, исходя из содержания эфира. Другими словами в реальном времени анализировал то, что сейчас происходит и принимал решение о том, что сейчас «проигрывается» реклама или какая-то передача, посредством определения присутствия логотипа телеканала в кадре.
Однако, даже для этой, казалось бы тривиальной задачи, необходимо использовать алгоритмы машинного обучение, по той причине, что логотип в кадре не является одинаковым. Он может поменять цвет, вследствие своей частичной прозрачности, а следовательно фон, который будет располагаться под логотипом, будет оказывать влияние на его внешний вид. Также в форму логотипа могут вноситься изменения. Это может носить как временных характер, в честь каких-то событий, так и постоянный, как например в случае изменение логотипа по причине изменения дизайна канала.
Гибко обученная нейронная сеть не встретит препятствий в этих и многих других случаях. В то время как алгоритм так называемого “сличения” не воспримет незначительные изменение в конструкции или цвета изображения как допустимое, и с высокой долей вероятности, не распознает его должным образом.
На основании изложенного, становиться очевидным, что в этом проекте для распознавания логотипа следует использовать нейронную сеть.
Формулирование особенностей работы редактора
Поскольку результатами работы полученного программного комплекса предстоит пользоваться редактору, следует дать пояснение о значении этого термина и особенностях его работы на телеканале.
Основная проблема, которую предстоит решить - это ускорение монтажа медиаконтента.
Монта́ж медиаконте́нта — творческий и технический процесс в кинематографе, на телевидении или звукозаписывающих студиях, позволяющий в результате соединения отдельных фрагментов исходных записей получить единое, композиционно цельное произведение[1]. Аналогичная переработка видеозаписей на телевидении называется словом «видеомонта́ж», однако во всех отраслях медиа общепринят более короткий термин монта́ж (фр. montage). Монтаж является важнейшей частью кинематографического языка, способной придать повествованию выразительность и внятность минимальными средствами[2].
В данном контексте редактор - это человек, профессия которого связана с редактирование контента телеканала, который уже был в эфире, для последующей загрузки его на сайт, социальные сети и youtube.
Особенно много времени редактор тратит на поиск точного времени начала, конца и прерываний на рекламные вставки.
Чаще всего редактор получает запись вчерашнего эфира, расписание и список необходимых отрезков, которые редактор должен сделать. Ориентируясь по эфиру при помощи расписания, редактор сначала делает заготовки для передачи, другими словами делает грубую вырезку записи передачи из 24 часового эфира, затем осуществляет склейку, вырезая рекламу. Далее, если это например был выпуск новостей или запись прямого эфира, он вырезает так называемые “хайлайты” - короткие и особо значимые участки передачи, список которых он получил ранее.
Бывают случаи, когда редактору необходимо в кратчайший срок опубликовать отрывок из только что вышедшей передачи, такое происходит в том случае, если информация из этого отрывка носит чрезвычайный характер. В эти моменты дорога каждая минута. Однако все омрачает тот факт, что для редактирования доступна лишь запись эфира предыдущего часа.
Описание текущей и предложенной схемы
Используя формальное описание работы редактора, можно составить схему его работы и предложить оптимизацию с использованием современных программно-аппаратных средств, в том числе и нейронных сетей.
Текущая схема работы редактора выглядит следующим образом.

Рисунок 1
где:
1. Получение списка необходимых отрезков - является получением списка необходимых отрезков, которых редактор должен нарезать и загрузить на сайт в течение рабочего дня. Поступает этот список руководителя по почте или лично на бумаге.
2. Скачивание необходимых отрезков - означает скачивание отрезков с серверов партнеров с использованием web-интерфейса сайта партнера.
3. Черновое редактирование - разделение скачанных отрезков на отрезки, разделенных рекламой, иными словами если имеется отрезок длинной 1 час с любым количеством прерываний на рекламу, сумма полученных отрезков будет также 1 час.
4. Чистовое редактирование - удаление из отрезков после черновой обработки участков видео с рекламой и склейка их в передачу, без рекламы.
5. Отправка отрезков на сайт - загрузка отредактированных передач из эфира на сайт телеканала. Подготовка краткого описания в соответствии с содержанием передачи.
Схема работы после внесенных изменений и улучшений при помощи предложенных и разработанных программных решений.

Рисунок 2
Где склейка отрезков, является соединением готовых участков видео с вырезанной рекламой.
Таким образом из схемы работы редактора полностью исключается черновое и частично чистовое редактирование, что должно положительно повлиять на производительность их труда.
Предложенная схема работы программного комплекса выглядит следующим образом:
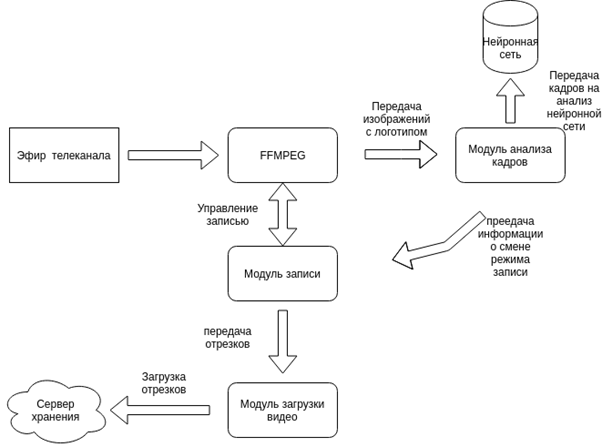
Рисунок 3
Опираясь на эти схемы необходимо:
1. Определить класс нейронных сетей, подходящих для данного проекта
2. Определить классы образов которые предстоит распознавать нейронной сети
3. Произвести необходимые исследования для разработки и обучения нейронной сети
4. Проработать схему работы приложения
5. Реализовать программный комплекс
6. Развернуть полученный сервис в тестовой среде и произвести необходимые измерения и тесты.
Критерии оценки технологий
С учетом приведенных выше ограничений и требований, можно сформулировать следующие критерии оценки используемых технологий:
1. Оболочка должна быть написана на популярном языке программирования.
2. Наличие подробной документации и множества примеров реализации.
3. Ядро должно эффективно использовать все возможности современных графических процессоров для распараллеливания вычислений на обучающем сервере.
4. Желательно наличие предварительно обученных нейронных сетей, с помощью которых легко будет построить классификатор образов.
Соответствие популярных библиотек критериям оценки
|
Библиотека (фреймворк) |
Популярный ЯП |
Подробная документация |
Оптимизация под GPU |
Предобученные нейронные сети |
|
Caffe |
+ |
- |
+ |
- |
|
Deeplearning4j |
+ |
+ |
+ |
+ |
|
deeplearning-hs |
- |
- |
+ |
- |
|
MatConvNet |
- |
- |
+ |
- |
|
neon |
- |
+ |
+ |
- |
|
TensorFlow |
+ |
+ |
+ |
+ |
|
Theano |
+ |
+ |
+ |
- |
|
Torch |
- |
+ |
+ |
- |
Как можно видеть, всем заданным критерия соответствуют только Deeplearning4j и TensorFlow. Однако, оболочка библиотеки Deeplearning4j есть только для языков Scala и Java, синтаксис которых тяжел для освоение, особенно если нейронная сеть будет первой программой которая на них будет написана. В то-же время оболочка TensorFlow написана на популярном и легким в освоении языке программирования Python, что в совокупности с огромным пулом предварительно обученных нейронных сетей, склоняет чашу весов в пользу именно этой библиотеки.
Таким образом, было принято решение использовать библиотеку TensorFlow.
Подготовка данных для обучения сети
Поскольку нейронной сети предстоит различать наличие и отсутствие логотипа. Логично будет использовать два класса для обучения:
1. NTV - изображения содержащие логотип телеканала “НТВ”
2. ADS - изображения, в которых отсутствует логотип телеканала, а следовательно реклама.

Рисунок 4 - Изображение, содержащее логотип телеканала

Рисунок 5 - Изображение, не содержащее логотип телеканала
Для подготовки данных, отвечающим заявленным требованиям, с сайта телеканала были загружены записи передач. Далее с помощью программы ffmpeg были найдены и вырезаны участки, в которых располагался логотип, с периодичностью 1/10 FPS, или один кард в десять секунд, это было сделано по двум причинам:
1. Если сохранять каждый кадр (25FPS), мы получим множество практически одинаковых кадров, что приведет к переобучению. Нейронная сеть не будет замечать существенных изменений между наличием и отсутствием логотипа, а будет опираться на похожесть обрабатываемых кадров, на экспозицию в обучающей выборки.
2. Использование такого большого количества кадров, схожих по содержанию только увеличит время обучения по той причине, что изменение весов во время обучения нейронных сетей происходит только в том случае, если полученные данные для обучения отличаются от предыдущих, другими словами - множество одинаковых кадров не увеличит точность распознавания кадров с отличным от этих кадров содержанием.




Рисунок 6 - Образцы изображений для обучения класса NTV.
Таким образом, было подготовлено около 3-х тысяч изображений из разных передач с разной экспозицией кадра с логотипом.
Далее встал вопрос - как быстро и качественно создать массив данных, для обучения нейронной сети для распознавания другого класса изображений, а именно рекламу. На сайте телеканала не было записей эфира с рекламой. Получить запись рекламы из телеканала представляется возможным только вручную вырезая участки из прямого эфира. Не трудно подсчитать, что для подготовки схожего массива данных той же методикой, пришлось бы вырезать свыше 8-ми часов рекламы.




Рисунок 7 - Образцы изображений для обучения класса ADS.
Решение было найдено. Для подготовки данных для распознавания класса ADS не использовалась реклама, а использовались те же записи передач, которые были использованы для обучения класса “НТВ”. Однако расположение вырезанного кадра относительно предыдущего было изменено. Таким образом время подготовки обучающих данных было сокращено вдвое, по той причине, что ffmpeg, обрабатывая один видеоролик, подготавливал сразу два набора данных.




Рисунок 8 - Образцы изображений для обучения класса ADS, выделенных из видео, для обучения класса NTV.
Процесс обучения нейронной сети
Для установки TensorFlow и необходимых сред разработки необходимо установить git, python версии 3.6 или 2.7, версии. Предпочтительно 3.6.
Также следует установить библиотеки для разработки. Основная из которых - TensorFlow
Для CPU вычислений - pip install tensorflow==1.8.1
Для GPU вычислений - pip install tensorflow-gpu==1.8.1
Далее необходимо склонировать репозиторий с демонстрацией работы нейронной сети.
git clone https://github.com/googlecodelabs/tensorflow-for-poets-2
В ней содержится уже обученная нейронная сеть, способная распознавать сорта полевых цветов. Ради интереса можно воспользоваться ей, для оценки точности алгоритма.
Обучение
Нам предстоит создать сеть, подобную той, которую мы клонировали ранее. Для этого следует сделать следующее:
1. Разложить данные для обучения в папку tf_folder/flower_photos. Это позволит обучающему алгоритмму распознать необходимое количество классов и их содержание.
2. Запустить алгоритм обучения командой:
python scripts/retrain.py --output_graph=tf_files/retrained_graph.pb --output_labels=tf_files/retrained_labels.txt --image_dir=tf_files/flower_photos
retrain.py - Это програма, поставляемая в пакете TensorFlow. Эта программа преобразует изображения из изображения из папок для обучения нейронной сети в классы для обучения. В нашем случае это два класса - NTV и ADS.
Во время исполнения команды обучения, у нее есть несколько дополнительных параметров:
1. Создать новый файл графов в папке tf_files (после завершения обучения). --output_graph=tf_files/retrained_graph.pb
2. Создать новый файл меток в папке tf_files (после завершения обучения). --output_labels=tf_files/retrained_labels.txt
3. Указать путь к датасету цветов. --image_dir=tf_files/flower_photos
4. Изменить модель, отличную от Inception-v3 --architecture mobilenet_1.0_224
5. Tensorboard --summaries_dir=tf_files/training_summaries/${write the architecture here}
6. Изменение расположения Bottleneck --bottleneck_dir=tf_files/bottlenecks
7. Изменение количества итераций --how_many_training_steps=500
Архитектура приложения
Поскольку нейронная сеть , анализирующая полученные изображения, способна только принимать решения о наличие логотипа телеканала или его отсутствии, следует разработать так называемую программную обвязку, включающую в себя:
1. обертку над вызовом подготовленной нейронной сети
2. средства для старта приложения в автоматическом режиме
3. алгоритм, принимающий решение о создании отрезка на основе данных после обработки
4. функцию, посылающие изображения для обработки
5. средства для загрузки полученных отрезков на сервер, для их хранения
6. средства создания исходной записи видео и получения кадрова для обработки нейронной сетью
7. развертывание сервиса на сервере для тестирования и эксплуатации
Полученная схема выглядит следующим образом.
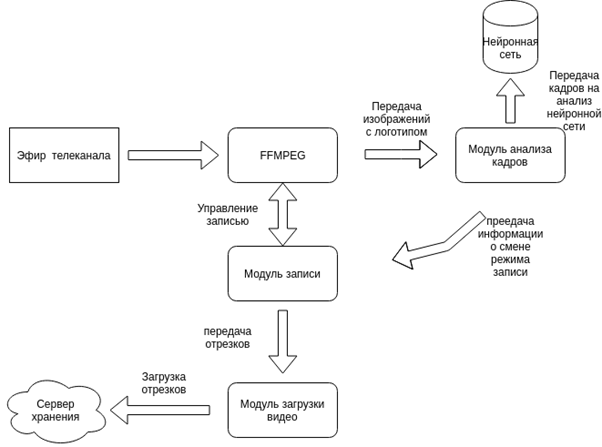
Рисунок 9
В виде блок-схемы программа выглядит следующим образом:
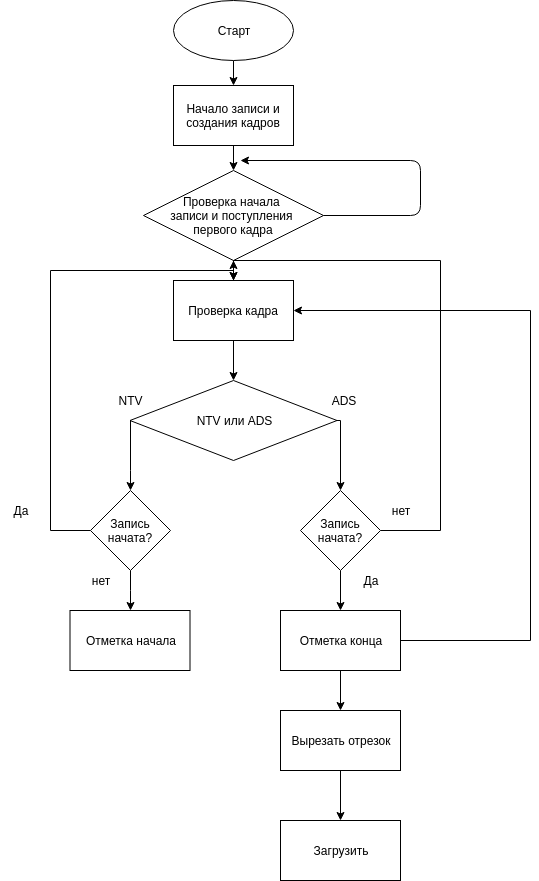
Рисунок 10 - Блок-схема программы
Тестирование
Для тестирования сверточных нейронных сетей помимо обучения и тестирования на наборе данных ImageNET, существуют и другие критерии. Самыми показательными из которых считаются:
1. Пропорция соотношения правильно определенных образов к неправильно определенным.
2. Разница между величинами выдаваемыми нейронной сетью для каждого класса. Иными словами разница между процентами принадлежности изображения к тому или иному классу должена быть максимально различена.
Поскольку нейронной сети будет необходимо различать изображения из вышеупомянутых классов (NTV и ADS), следует проводить тестирования на этих же классах в условиях максимально приближенным к условиям ее использования
Для тестирования в реальных условиях использовалось два проекта:
1. Первый проект соответствовал разрабатываемому проекту и работал в штатном режим.
2. Второй проект имел некоторые отличия от разрабатываемого. Основное отличие заключалось в том, что для этого проекта не работало правило о накопления n-го количества кадров подряд для переключением состояния записи и определения времени начала и конца эфира без рекламы, которое сглаживало случайные срабатывания переключения между ADS и NTV. Таким образом в видеозаписях второго проекта будут явно видны участки некорректной работы нейронной сети. Так же в отличие от первого проекта, во втором обработанные кадры не будут удаляться, а будут сохраняться в директориях, соответствующих их класса. Помимо этого в этом экземпляре проекта осуществляется логгирование параметров, полученных в результате работы нейронной сети. А именно: время затраченное на обработку изображения, распределение вероятности вхождения изображения в каждый класса (NTV, ADS), принадлежность к классу, название полученного изображения. Название сохраняется с целью в дальнейшем сопоставить кадры и полученных графики.
Результаты тестирования нейронной сети
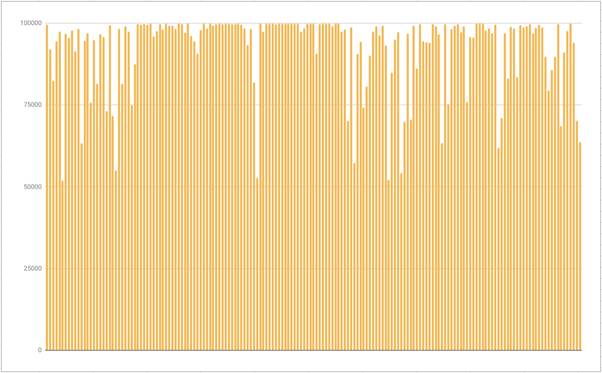
Рисунок 11 - График активности нейронной сети в классе ADS
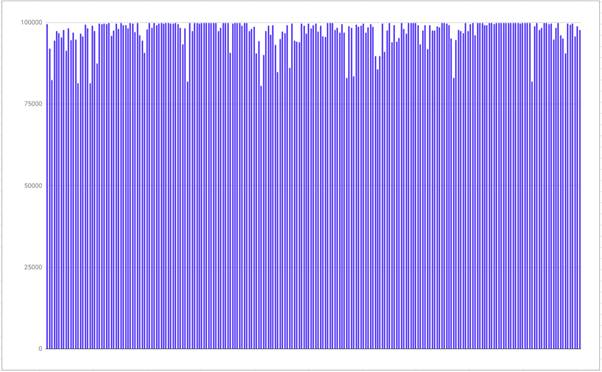
Рисунок 12 - График активности нейронной сети в классе NTV
Сравнение графиков активности нейронной сети показывает, что нейронной сети легче определить класс NTV, связано это с тем, что в этом классе присутствуют явные показатели - присутствие логотипа. Для класса ADS таких явных показателей, как присутствие в кадре чего-либо - нет. С этим связана низкая, по сравнения с активностью класса NTV, активность.
По результата визуального сличения в папке с изображениями класса ADS из более чем 2000 изображений было обнаружено 46 изображений с логотипом телеканала NTV, это означает что в этих случаях нейронная сеть сработала неправильно. Вот несколько из этих изображений:




Рисунок 13 - изображения, ошибочно определенные нейронной сетью
Таким образом, точность нейронной сети в распознавании касса ADS в данном тестировании составляет 97,7%, что является отличным показателем для данного класса нейронных сетей.
В папке класса NTV было найдено 115 изображения без логотипа, из более чем 8000 изображений.
Таким образом точность нейронной сети в распознавании касса NTV в данном тестировании составляет 98,5625%, что также является хорошим показателем.
График активности для ошибочно определенных кадров:
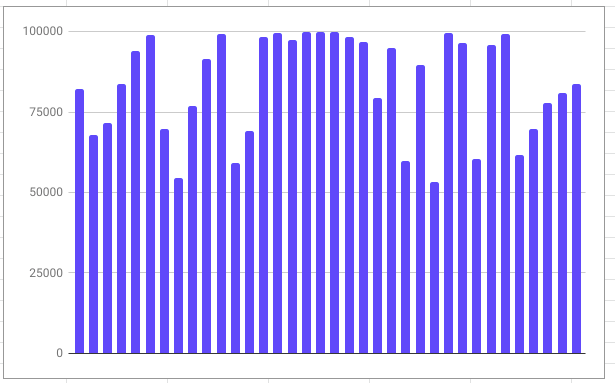
Рисунок 14 График активности для изображений ошибочно определенных как NTV.
На графике видна низкая активность нейронной сети, при неправильной классификации изображений, из этого следует, что когда нейронная сеть делает вывод о принадлежности изображения к тому или иному классу, при этом имея низкую активность, данные с высокой долей вероятности могут оказаться неточными, а значит что данные с низкой активность можно не учитывать при принятие решения либо.
Как было заявлено в постановке задачи, одна из основных целей этого программного комплекса - сокращение времени, которое тратят редакторы на редактирование видео. Исходя из этого было сформировано два требования к этой системе:
Погрешность в автоматическом удалении рекламы должно быть не более одной секунды. Это означает, что:
1. В полученном отрезке должно быть не более одной секунды рекламного материала в начале и в конце отрезка.
2. В полученном отрезке должно быть потеряно не более одной секунды материала передачи в начале и в конце.
Также, время, которое тратит редактор на составление одной передачи должно быть уменьшено не менее чем на 15%.
Тестирование должно показать соответствие или не соответствие разработанного проекта этим критериям.
Для определения погрешностей в автоматическом удалении рекламы отлично подходят материалы, полученные в результате работы первого проекта, который использовался в тестировании нейронной сети.
Для определения уменьшения времени, затраченного редакторами на производство одной передачи, предполагается дать редакторам 5-7 дней на ознакомление с особенностями работы с материалами, подготовленным новым сервисом, далее сделать 3 замера времени редактирования одинаковых передач, выпущенных в разные дни.
Результаты тестирования проекта.
Определение погрешности в автоматическом удалении рекламы показало, что из 10-ти отрезков, во всех показатели не превысили заявленных ограничений.
|
Номер видеоролика |
Погрешность в начале (сек) |
Погрешность в конце(сек) |
|
1 |
-0.4 |
+0.2 |
|
2 |
-0.2 |
+0.6 |
|
3 |
+0.6 |
+0.2 |
|
4 |
-0.1 |
-0.5 |
|
5 |
+0.8 |
-0.1 |
|
6 |
+0.3 |
-0.2 |
|
7 |
+0.3 |
+0.4 |
|
8 |
-0.5 |
+0.4 |
|
9 |
-0.1 |
-0.6 |
|
10 |
+0.8 |
+0.1 |
Таким образом все видеоролики, проходившие тестирование уложились в заявленные рамки.
Результаты тестирования сокращения времени затраченного редакторами на редактирование одной передачи. Для тестирования была взята передача, идущая в прямом эфире, по той причине, что время прерывания на рекламу у этой передачи постоянно меняется.
Без использования материалов, подготовленных нейронной сетью редактор потратил 27 минут. Из них на черновое и чистовое редактирования - 14 минут. Остальное время было потрачено на скачивание видеороликов - около 5-ти минут, остальное на загрузку видеороликов, ознакомление с расписанием, поиск нужных видеороликов.
С использованием материалов, подготовленными программным комплексом с использование нейронной сети редактор потратил около 15-ти минут из них 4 минуты на склейку и проверку роликов, 3 минуты на скачивание необходимых видеороликов. Таким образом общее время обработки передачи уменьшилось на 45.5%, время скачивания на 40%, время склейки видеоролика на 71,43%.
Литература
1. Chatfield, K. Return of the Devil in the Details: Delving Deep into Convolutional Nets [Текст] / Simonyan, K. Vedaldi, A. Zisserman, A. — Visual Geometry Group Department of Engineering Science University of Oxford Oxford, UK — 4, 5
2. Fischer, P. Descriptor matching with convolutional neural networks: a comparison to SIFT [Текст] ./ A. Dosovitskiy, T. Brox — CoRR, abs/1405.5769, 2014. — 1
3. Gupta, S. Perceptual organization and recognition of indoor scenes from RGB-D images. [Текст] / P. Arbelaez, J. — Malik In CVPR, 2013. — 8
4. Gupta, Learning rich features from RGB-D images for object detection and segmentation [Текст] ./ S. Girshick, P. Arbelaez, J. Malik — In ECCV. Springer, 2014. — 1, 2, 8
5. Ganin, Y. N4 -fields: Neural network nearest neighbor fields for image transforms. [Текст] / V. Lempitsky. — In ACCV, 2014. — 1, 2, 7
6. Girshick, R. Rich feature hierarchies for accurate object detection and semantic segmentation. [Текст] / J. Donahue, T. Darrell, J. Malik — In Computer Vision and Pattern Recognition, 2014. — 1, 2, 7
7. Fast image scanning with deep max-pooling convolutional neural networks. [Текст] / A. Giusti, D. C. Cires J. Masci, L. M. Gambardella, and J. Schmidhuber. — In ICIP, 2013. — 3, 4
8. Harley, A. W. “An Interactive Node-Link Visualization of Convolutional Neural Networks [Текст] — in ISVC, 2015 — 867-877
9. Hariharan B. Semantic contours from inverse detectors. [Текст] / P. Arbelaez, L. Bourdev, S. Maji, and J. Malik — In International Conference on Computer Vision (ICCV), 2011. — 7
10. B. Hariharan, taneous detection and segmentation. [Текст] / P. Arbelaez, R. Girshick, J. Malik. Simul — In European Conference on Computer Vision (ECCV), 2014. — 1, 2, 4, 5, 7, 8 55
11. B. Hariharan, Hypercolumns for object segmentation and fine-grained localization [Текст] ./ P. Arbelaez, R. Girshick, J. Malik. — In Computer Vision and Pattern Recognition, 2015. — 2
12. He K., Spatial pyramid pooling in deep convolutional networks for visual recognition. [Текст] / X. Zhang, S. Ren, and J. Sun. — In ECCV, 2014. — 1, 2
13. Caffe: Convolutional architecture for fast feature embedding. [Текст] / Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell. — arXiv preprint arXiv:1408.5093, 2014. — 7
14. Backpropagation applied to hand-written zip code recognition. [Текст] / Y. LeCun, B. Boser, J. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. — In Neural Computation, — 1989.
15. Backpropagation applied to hand-written zip code recognition. [Текст] / Y. LeCun, B. Boser, J. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. — In Neural Computation, 1989. — 2, 3
16. LeCun, Y. A. Efficient backprop. In Neural networks: Tricks of the trade. [Текст] / L. Bottou, G. B. Orr, and K.-R. Muller. — Springer, 1998. — 9–48.
17. Liu, C. Sift flow: Dense correspondence across scenes and its applications. Pattern Analysis and Machine Intelligence [Текст] / J. Yuen, and A. Torralba — IEEE Transactions on, 33(5):978–994, 2011. — 8
18. Long J., Do convnets learn correspondence? [Текст] / N. Zhang, and T. Darrell. — In NIPS, 2014. — 1
19. Long, J. Shelhamer, E. Darrell, T. Fully Convolutional Networks for Semantic Segmentation [Текст]/ UC Berkeley
20. Krizhevsky, A. Imagenet classification with deep convolutional neural networks. [Текст] / I. Sutskever, and G. E. — Hinton In NIPS, — 2012.
21. Spatial pyramid pooling in deep convolutional networks for visual recognition. [Текст] / K. Khe, A. Zhang, S. Ren, and J. Sun, — in Proc. ECCV, 2014 — 3
22. Koenderink, J. J. Representation of local geometry in the visual system. [Текст] / A. J. van Doorn Biological cybernetics, — 55(6):367–375, 1987. — 6 56
23. Striving for Simplicity: The All Convolutional Net, [Текст] / J. T. Springenberg, A. Dosovitskiy, T. Brox, M. Riedmiller, — NASA ADS, 2015
24. Going deeper with convolutions. [Текст] / C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. — CoRR, abs/1409.4842, 2014. — 1, 2, 3, 5
25. Wojna, Z. Rethinking the Inception Architecture for Computer Vision [Текст] / Szegedy C., Vanhoucke V., Ioffe S., Shlens J., — DBLP - CS Bibliography
26. Yu, F. Multi-Scale Context Aggregation by Dilated Convolutions [Текст] / V. Koltun, at ICLR, 2016