РАЗРАБОТКА УСКОРЕННОЙ ВЕРСИИ МЕТОДА КЛАСТЕРНОЙ ВИЗУАЛИЗАЦИИ
Ершов Д.А.
С ростом вычислительных мощностей и появлением графических адаптеров компьютерная графика начала интенсивно развиваться. На данный момент визуализация в реальном времени является одним из наиболее важных и перспективных направлений в компьютерной графике. Системы компьютерной визуализации применяются в системах виртуальной и дополненной реальности, в различных тренажерах и компьютерных играх, в кинематографе, САПР, где необходимо обрабатывать сложные трехмерные сцены в реальном времени.
Визуализация (rendering) [1] – термин в компьютерной графике, обозначающий процесс получения плоского цифрового растрового изображения по модели с помощью компьютерной программы. Моделью является описание любых объектов или явлений на строго определенном языке или в виде структуры данных. Такое описание может содержать геометрические данные, информацию об освещении, материалах, положение точки наблюдателя и пр.
В зависимости от цели, различают предварительную визуализацию, как достаточно медленный процесс визуализации, применяющийся в основном при создании фильмов и фотореалистичных изображений, и визуализацию в режиме реального времени, широко применяемую в компьютерных играх и системах виртуальной реальности.
Визуализация является вычислительной задачей, которая эффективно решается с помощью видеокарт (графических адаптеров). Современные видеокарты содержат в себе графический процессор (GPU), собственную оперативную память, подсистему дополнительного питания, разъёмы для подключения мониторов и разъем для подключения к шине PCI Express.
Графический процессор (GPU) – это специализированная интегральная схема, разработанная для эффективной обработки и формирования изображений компьютерной графики. Благодаря многопоточной архитектуре с множеством ядер и специализированной конвейерной архитектуре графические процессоры намного эффективнее в обработке графической информации, чем центральный процессор. Графические процессоры используются не только для расчетов, связанных с построением и обработкой изображений компьютерной графики, но и для различных параллельных вычислений.
В современных видеоадаптерах используется специализированная память с высокой пропускной способностью. Пиковая пропускная способность памяти достигает примерно 500 ГБ/с. Видеопамять хранит данные изображений, текстуры, буферы вершин, глубины и специализированные программы. Как правило, микросхемы памяти распложены в непосредственной близости от графического процессора и являются несъемными. Столь близкое расположение оперативной памяти позволяет процессору быстро получать всю необходимую информацию, что увеличивает производительность видеоадаптера. Видеоадаптеры, интегрированные в материнскую плату или центральный процессор, обычно не имеют собственной видеопамяти и используют для хранения часть оперативной памяти компьютера (UMA – Uniform Memory Access, однородный доступ к памяти)
Для формирования изображения трехмерной сцены информация об отображаемой геометрии должна быть загружена в память видеокарты, после чего пропущена по графическому конвейеру. Графический конвейер (конвейер визуализации) [2] – это модель, которая описывает последовательность этапов, которые должна выполнить система визуализации для отображения трехмерной сцены в двухмерное цифровое растровое изображение. Этапы графического конвейера представлены на рис. 1.
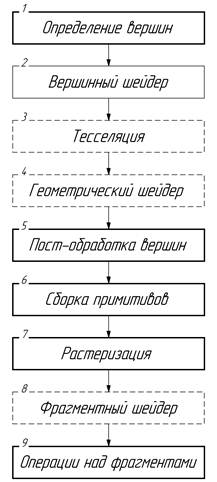
Рис. 1. Графический конвейер
Этапы вершинного шейдера, тесселяции, геометрического и фрагментного шейдеров могут быть запрограммированы с помощью шейдерных программ (шейдеров), остальные же этапы – просто настроены нужным образом. Пунктиром выделены необязательные для программирования и исполнения этапы.
Шейдер (shader, затеняющая программа) [3] – компьютерная программа, предназначенная для параллельного выполнения процессорами графического адаптера на одной из стадий графического конвейера, написанная на одном из специализированных языков (GLSL, HLSL, Cg) и компилируемая в инструкции графического процессора. Словом «шейдер» называется независимо компилируемая единица, предназначенная для выполнения в рамках отдельного этапа графического конвейера. Словом «программа» называется набор скомпилированных шейдеров, связанных вместе в единую шейдерную программу, определяющую работу графического конвейера. Таким образом, с помощью шейдерных программ графический конвейер может быть настроен для выполнения различных задач.
Современные графические процессоры имеют тысячи унифицированных шейдерных вычислительных блоков (unified shader, shader processor) и проектируются с использованием унифицированной шейдерной архитектуры (unified shading architecture). Каждый шейдерный блок может выполнять любую из стадий графического конвейера, что позволяет более гибко использовать ресурсы графического процессора. Унифицированную шейдерную архитектуру поддерживают все современные графические процессоры.
1.3 Проблемы визуализации в реальном времени
Современные системы визуализации стремятся достичь фотореалистичной графики, для чего очень важен корректный расчет освещенности объектов сцены. Полноценный расчет глобального освещения сцены с учетом косвенного (вторичного) освещения возможен лишь с использованием методов трассировки лучей, однако он занимает большое количество времени из-за большой вычислительной сложности данных методов.
В основе методов визуализации в реальном времени лежит процесс проецирования трехмерной сцены на плоскость и растеризация. Трехмерная сцена за счет математических преобразований проецируется на плоскость, после чего происходит процесс растеризации, в ходе которого спроецированная геометрия разбивается на отдельные фрагменты, соответствующие пикселям.
Одной из важных проблем при визуализации является расчет освещенности от большого количества источников света. При расчете конечного цвета каждого пикселя требуется знать информацию о всех источниках света, влияющих на освещенность объекта, которому этот пиксель принадлежит. Обработку источников света, влияющих на определенный объект, невозможно выполнить параллельно в пределах графического конвейера при непосредственном расчете освещенности. Современные методы визуализации по-разному решают данную проблему.
1.4 Современные методы визуализации в реальном времени
В настоящее время существует несколько методов, которые позволяют справиться с недостатками расчета освещенности классических методов визуализации, при этом не теряют преимуществ каждого из методов. Они используются как надстройка над классическими методами, позволяющая выполнять эффективный расчет освещенности от большого количества источников света.
Одним из них является тайловая (плиточная) визуализация [4, 5], которая может применяться как с традиционным подходом к освещению трехмерной сцены (прямой визуализацией), так и с методов отложенного освещения. С учетом мощностей современных видеокарт применение отложенной визуализации с помощью тайлов обеспечивает значительное увеличение производительности системы визуализации по сравнению с «чистой» отложенной визуализацией.
Принцип тайловая визуализация заключается в разбиении экранного пространства на квадратные участки (тайлы). На основе информации о глубине сцены выполняется определение ограничивающих объемов тайлов – усеченных пирамид. Размер тайлов выбирается так, чтобы сохранять баланс между использованием памяти и эффективностью осуществления вычислений. При использовании тайлов малого размера (8x8 пикселей) возрастает общее количество тайлов и количество используемой памяти, но возрастает точность отсечения источников света.
Отсечение источников света выполняется за счет присвоения тайлам только тех источников света, которые могут повлиять на освещенность фрагментов геометрии сцены, находящихся внутри этих тайлов. Присвоение выполняется в несколько этапов. Первоначально вычисляются максимальное и минимальное значения глубины фрагментов внутри тайла, после чего возможно построение усеченной пирамиды тайла. Далее выполняется проверка пересечения ограничивающих объемов источников света с усеченной пирамидой тайлов, благодаря чему формируется локальный список источников света тайла. Данный этап эффективно распараллеливается за счет использования разделяемой памяти графического процессора.
После этого возможно выполнение визуализации всех геометрических объектов сцены с расчетом освещенности только от тех источников света, которые присутствуют в локальном списке тайла, которому принадлежит рассчитываемый фрагмент финального изображения. Однако для тайлов, фрагменты которых существенно отличаются по глубине, усеченная пирамида получается слишком длинной, из-за чего пересекается с большим количеством ограничивающих объемов источников света, которые не влияют на освещенность внутри тайла. Это существенно снижает эффективность отсечения обрабатываемых источников света.
Кластерная визуализация [6, 7] позволяет решить проблемы тайловой визуализации. Каждый кластер имеет фиксированную глубину, что снижает количество источников света, не влияющих на освещенность внутри тайла. Перед началом визуализации выполняется построение параллельных осям ограничивающих параллелепипедов (AABB – Axis-Aligned Bounding Box) кластеров в пространстве камеры, разбивая пирамиду видимости на множество частей. Построение кластерной сетки в пространстве камеры позволяет избежать перестроения AABB на каждом кадре визуализации. Присвоение источников света выполняется также в несколько этапов, как и в методе тайловой визуализации. Первоначально выполняется предварительное построение буфера глубины сцены за счет визуализации всех геометрических объектов в отдельное полноэкранное изображение. Параллельно с этим на стадии обработки фрагментов графического конвейера осуществляется определение уникальных (активных) кластеров за счет вычисления трехмерного индекса кластера, которому принадлежит обрабатываемый фрагмент, и маркировки кластера. На стадии присвоения источников света уникальным кластерам выполняется перебор всех источников света и проверка пересечения ограничивающих объемов источников света с AABB кластеров, за счет чего формируется локальный список источников света для каждого кластера.
При визуализации всех геометрических объектов сцены расчет освещенности выполняется только от тех источников освещения, которые находятся в локальном списке кластера, которому принадлежит рассчитываемый фрагмент финального изображения. Этапы данного метода эффективно распараллеливаются и выполняются полностью на GPU, что позволяет избежать лишнего копирования данных между CPU и GPU.
2 Анализ возможных путей ускорения
Ранее автором были разработаны реализации классических методов тайловой и кластерной визуализации с незначительными улучшениями.
Необходимо проанализировать классический метод кластерой визуализации, выявить узкие места и предложить пути их ускорения.
Разработать собственную программную реализацию ускоренного метода кластерной визуализации сложных трехмерных сцен с применением предложенного пути оптимизации с использованием OpenGL 4.5.
При реализации стараться выполнять все возможные действия непосредственно на GPU, чтобы минимизировать затраты на пересылку данных между CPU и GPU.
Провести тестирование и сравнительный анализ полученной ускоренной реализации с разработанным ранее классическим методом кластерной визуализации.
2.2 Разработанный классический метод кластерной визуализации
Алгоритм работы разработанного ранее классического метода кластерной визуализации представлен на рис. 5.
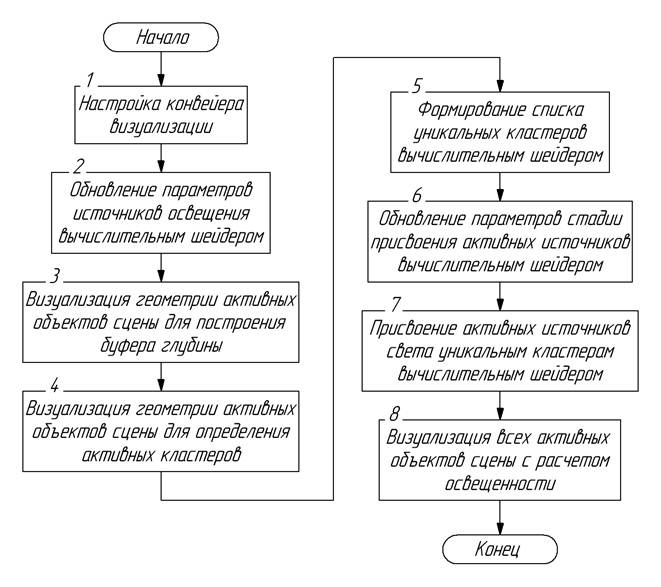
Рис. 5. Алгоритм работы метода кластерной визуализации
На 1 этапе выполняется настройка работы тестов конвейера, очистка буфера цвета и глубины, задается фоновый цвет буфера и получение матриц трансформации от камеры.
На 2 этапе запускается вычислительный шейдер, осуществляющий обновление всех активных источников освещения на основе прошедшего времени между кадрами.
На 3 этапе выполняется визуализация всех активных объектов в сцене с использованием шейдерной программы для построения буфера глубины.
На 4 этапе выполняется визуализация всех активных объектов в сцене с использованием шейдерной программы для определения активных кластеров.
На 5 этапе запускается вычислительный шейдер, осуществляющий формирование списка уникальных активных кластеров и подсчет их количества.
На 6 этапе запускается вычислительный шейдер, осуществляющий копирование количества уникальных активных кластеров в буфер, содержащий аргументы для запуска следующего этапа.
На 7 этапе запускается вычислительный шейдер, осуществляющий определение и присвоение источников света, влияющих на пиксели внутри кластеров.
На 8 этапе выполняется визуализация всех активных объектов в сцене с использованием основной шейдерной программы.
Перед началом выполнения алгоритма создаются все необходимые структуры данных для хранения информации о кластерах, для маркировки активных кластеров, для списка уникальных кластеров, для хранения AABB кластеров, для хранения информации о источниках света в каждом кластере, для хранения списка индексов всех источников света в кластерах и экранный буфер с единственной текстурой для хранения глубины. Каждый кластер имеет пространственный и линейный индекс, с помощью которого в буферах можно найти соответствующую ему информацию. Одиночный срез кластерной сетки, содержащий смещение в буфере индексов источников света и количество источников света в калстере, представлен на рис. 6.
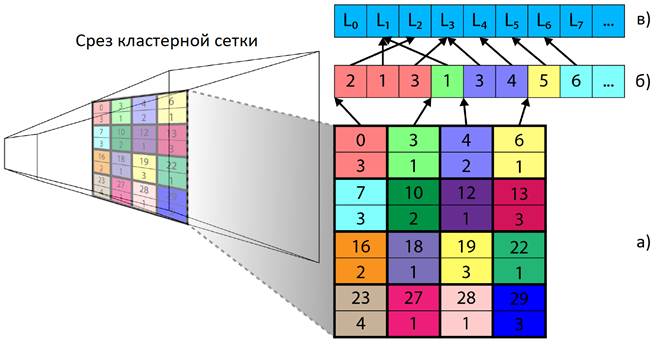
Рис. 6. Одиночный срез кластерной сетки a), б) – список индексов источников света, в) – список источников света
Перед началом работы метода вычислительный шейдер выполняет построение AABB кластеров в пространстве камеры, разбивая пирамиду видимости на множество частей. Построение кластеров в пространстве камеры позволяет избежать перестроения AABB на каждом кадре.
Предварительное построение буфера глубины осуществляется за счет визуализации всей сцены в отдельный экранный буфер, содержащий только текстуру для хранения глубины фрагментов. В конвейер на данном этапе поступает лишь информации о вершинах объектов.
Определение активных кластеров осуществляется путем визуализации геометрии сцены, при этом в фрагментном шейдере осуществляется определение трехмерного индекса кластера, после чего он преобразуется в линейный индекс и по данному индексу осуществляется запись в буфер флагов активности кластеров.
После этого запускается вычислительный шейдер, каждый поток которого соответствует одному кластеру. Данная шейдерная программа формирует список уникальных кластеров, активных в данной сцене, в глобальной памяти.
Для оптимального выполнения стадии присвоения источников света кластерам необходимо точно знать количество рабочих групп. Количество рабочих групп в данном случае совпадает с количеством уникальных кластеров, которое подсчитывается при формировании списка уникальных кластеров на предыдущем шаге. Для избежания лишнего копирования данных с GPU на CPU с итоговой задержкой в несколько кадров [8] используется дополнительный вычислительный шейдер и возможность непрямого запуска вычислительных шейдеров (glDispatchComputeIndirect), которая появилась в OpenGL 4.3. Дополнительный вычислительный шейдер копирует количество уникальных кластеров в параметры для запуска следующей стадии, что позволяет эффективно использовать ресурсы GPU.
На стадии присвоения источников освещения кластерам выполняется грубый перебор всех источников освещения каждой рабочей группой и формирование локальных списков на основе коллизии между сферами источников освещения и AABB кластеров. При переборе используется Global Memory Coalescing для эффективного доступа к глобальной памяти и ускорения данной стадии. После формирования локальных списков источников для уникальных кластеров данные списки копируются в глобальный линейный буфер индексов источников света в кластерах, а информация о количестве источников в кластере и смещении локального списка в глобальном заносятся в дополнительный буфер по линейному индексу кластера.
На последнем этапе выполняется визуализация всех объектов сцены. При расчете освещенности учитываются только те источники света, которые могут повлиять на фрагменты кластера, которому принадлежит рассчитываемый данным потоком фрагмент.
Листинг кода программной реализации классического метода кластерной визуализации представлен в приложении Б.
2.3 Ускорение классического метода кластерой визуализации
Узким местом метода кластерной визуализации является 7-ой этап, осуществляющий присвоение источников света кластерам. Присвоение выполняется методом грубой силы (brute-force), то есть полным перебором всех источников света, выполняемым параллельно в пределах каждого кластера, в ходе которого осуществляется проверка пересечений.
Данный этап можно существенно ускорить за счет предварительного построения иерархии ограничивающих объемов (BVH – Bounding Volume Hierarchy) источников света на этапе 2-ом этапе работы алгоритма, где осуществляется обновление активных источников света, присутствующий в сцене. Тогда на стадии присвоения источников света будет выполняться обход дерева ограничивающих объемов источников света, что позволит быстро определять подмножество источников света, потенциально пересекающихся с ограничивающим объемом кластера. Таким образом, проверка пересечения будет осуществляться только с теми источниками света, которые содержатся в узле BVH, пересекающимся с ограничивающим объемом кластера.
Однако построение BVH непосредственно на GPU является сложной задачей, детали решения которой будут рассмотрены в ходе разработки.
3 Разработка программной реализации
Для реализации будет использован разработанный ранее инструментарий визуализации. Инструментарий разработан на языке С++ с использованием библиотек OpenGL, GLFW и ImGui. Внутри инструментария реализован профилировщик для измерения времени работы на CPU и GPU.
Для обеспечения взаимодействия с видеокартой используется открытая графическая библиотека OpenGL 4.5, которая предоставляет множество новых возможностей, в сравнении с её предыдущими версиями. В частности, версия 4.5 направлена на сведение к минимуму накладных расходов при работе с драйвером видеокарты (AZDO) и эффективное взаимодействие с выделенными ресурсами.
Для упрощения работы с операционной системой используется открытая кроссплатформенная библиотека GLFW, которая обеспечивает простой и гибкий программный интерфейс для создания окон, инициализации контекста OpenGL и обработки системных событий.
Для реализации графического интерфейса пользователя использована открытая библиотека ImGui, которая спроектирована для простой интеграции в системы визуализации реального времени.
Методы визуализации реализованы в виде отдельных классов. Каждый из классов переопределяет метод render() базового абстрактного класса Renderer. В данном методе размещается основная часть реализации соответствующего метода.
Помимо этого каждый из классов переопределяет методы onGUI() и onResize(), для отображения вспомогательного интерфейса управления визуализацией и для изменения размера необходимых буферов и текстур в соответствии с изменением рабочей области окна приложения.
При инициализации загружаются и компилируются шейдерные программы, резервируются необходимые ресурсы и устанавливаются константные данные, необходимые для визуализации.
Для упрощения реализации рассматриваются только точечные источники света, а информация о источниках света формируется на этапе инициализации сцены. Обновление источников света осуществляется непосредственно на GPU для избежания накладных расходов по пересылке данные между CPU и GPU.
Рассмотрим подробнее реализацию алгоритма ускоренного метода в пределах классов и шейдерных программы.
3.3 Разработка программной реализации ускоренного метода
Иерархия ограничивающих объемов источников света должна перестраиваться при любом изменении позиции или ориентации источников света относительно виртуальной камеры. Для эффективного построения иерархии ограничивающих объемов использованы коды Мортона, которые вычисляются для каждого источника света на основе его позиции в пространстве. Код Мортона (порядок Мортона) [8] – это функция, задающая взаимно однозначное отображение многомерных данных в одномерное пространство с сохранением локальности данных.
После вычисления кодов Мортона необходимо выполнить их сортировку. Для этого используется гибридная сортировка, позволяющая максимально эффективно использовать ресурсы GPU. Первоначально выполняется поразрядная сортировка [9], позволяющая получить отдельные отсортированные группы кодов. После этого осуществляется сортировка слиянием [10], результатом которой является полностью отсортированная последовательность кодов Мортона. Сортировка выполняется за определенное число этапов, которое зависит от количества источников света в сцене.
Построение уровней иерархии ограничивающих объемов выполняется параллельной обработкой линейных участков отсортированной последовательности кодов Мортона благодаря свойству пространственной локальности данных.
С учетом вышеописанного алгоритм работы ускоренного метода кластерной визуализации имеет следующий вид, представленный на рис. 7.
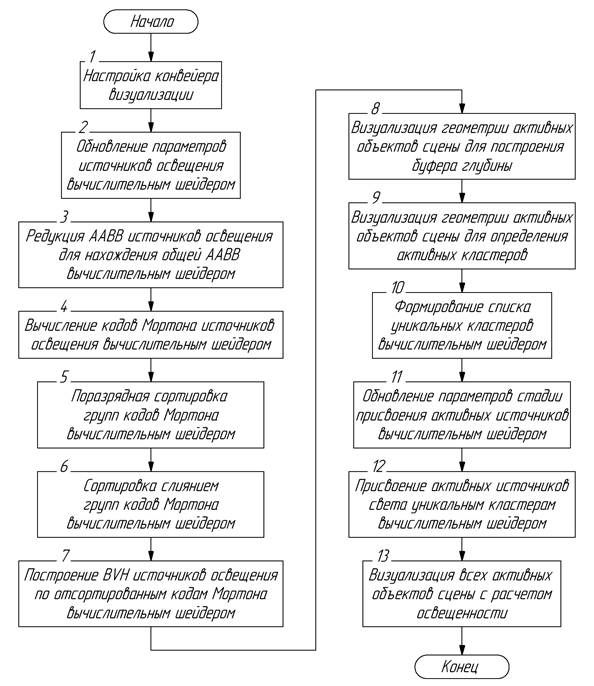
Рис. 7. Алгоритм работы ускоренного метода кластерной визуализации
Этапы 1 и 2, выполняющие настройку конвейера и обновление источников света, остались неизменными.
На 3 этапе запускается вычислительный шейдер, выполняющий параллельную редукцию AABB источников света для получения общей AABB, содержащей в себе все источники освещения. Данный этап необходим для дальнейшего вычисления кодов Мортона.
На 4 этапе запускается вычислительный шейдер, осуществляющий вычисление кодов Мортона для каждого источника освещения на основе его нормализованных координат относительно общей AABB источников света.
На 5 этапе запускается вычислительный шейдер, осуществляющий предварительную поразрядную сортировку кодов Мортона внутри отдельных групп.
На 6 этапе запускается вычислительный шейдер, осуществляющий параллельную сортировку слиянием групп отсортированных кодов Мортона для получения единой отсортированной последовательности.
На 7 этапе запускается вычислительный шейдер, осуществляющий построение BVH источников освещения. За счет свойства пространственной локальности кодов Мортона построение выполняется объединением кусочков отсортированной последовательности в узлы BVH. Изначально формируются «листья» BVH, после чего они объединяются, формируя родительские узлы. Количество запусков вычислительного шейдера зависит от количества уровней итогового BVH, что напрямую зависит от количества источников освещения.
Этапы с 8 по 13 осуществляют тоже самое, что и в классическом алгоритме, однако стоит внимательнее рассмотреть 12 этап.
На 12 этапе запускается вычислительный шейдер, осуществляющий определение и присвоение источников света, влияющих на пиксели внутри кластеров. Именно на данном этапе выполняется параллельный обход BVH с использованием стека в разделяемой памяти для определения узлов, пересекающихся с ограничивающим объемом кластера. После этого возможно осуществление проверки пересечения с AABB источников освещения, содержащихся в узлах.
Листинг кода программной реализации ускоренного метода представлен в приложении В.
4 Сравнение разработанных реализаций
4.1 Характеристики тестового оборудования
Тестирование и оценка времени выполнения отдельных этапов полученной программной реализации будет выполнятся с использованием классической сцены Crytek Sponza на следующем оборудовании:
- GPU: NVIDIA GeForce GTX 1050 Ti 4 ГБ GDDR5, 768 CUDA Cores, разрядность шины 128 бита.
- CPU: Intel Core i5-7300HQ @ 2.50 ГГц
- ОЗУ: SODIMM (2400 МГц) 8 ГБ
- Разрешение экрана: 1920х1080.
На рис. 8 представлена визуализируемая сцена, отображаемся с использованием классического метода кластерной визуализации. Также представлен пользовательский интерфейс программы.

Рис. 8. Визуализация тестовой сцены Crytek Sponza в разрешении 1920x1080 с большим количеством источников света
4.2 Временные характеристики методов
При измерении временных характеристик методов использовались источники света с радиусом действия 0.3 единиц и от 1 до 2 единиц.
На рис. 9 и 10 представлены зависимости времени работы стадий классического метода кластерной визуализации, реализованного ранее.
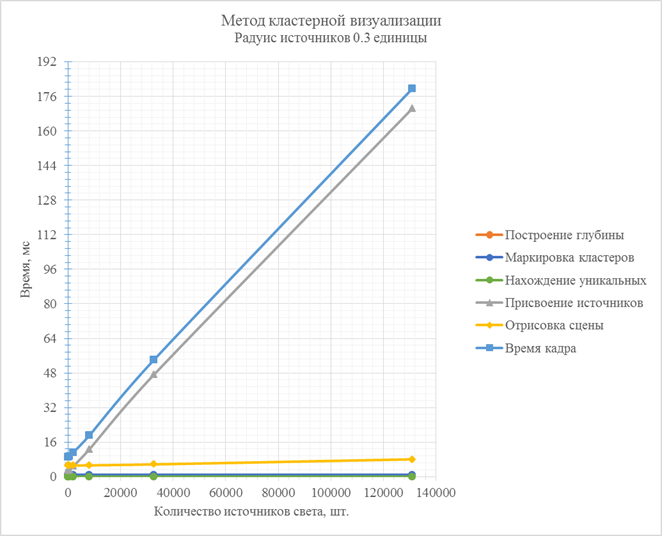
Рис. 9. Зависимости времени работы стадий метода кластерной визуализации от количества источников света в сцене (радиус источников 0.3 единицы)
При использовании источников света малого радиуса действия основной стадией, наиболее сильно влияющей на общее время визуализации кадра, становится стадия присвоения источников света кластерам.
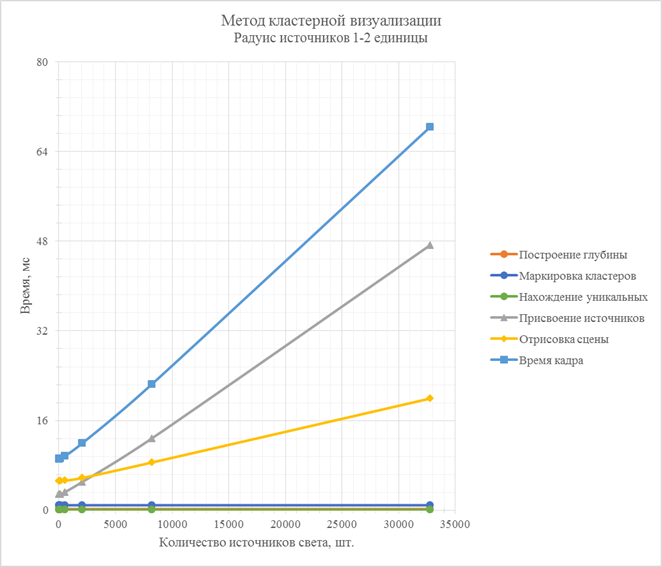
Рис. 10. Зависимости времени работы стадий метода кластерной визуализации от количества источников света в сцене (радиус источников 1-2 единицы)
При использовании источников света большего радиуса действия основной стадией, наиболее сильно влияющей на общее время визуализации кадра, становится стадия отрисовки сцены. Из-за большего радиуса действия в кластеры, на стадии присвоения источников, попадает большее количество источников света, для которых приходится выполнять расчет освещенности на этапе отрисовки сцены. Время работы стадии присвоения источников света незначительно зависит от радиуса источников света, однако сильно зависимо от их количества.
Рассмотри характеристики ускоренного метода кластерной визуализации с использованием BVH.
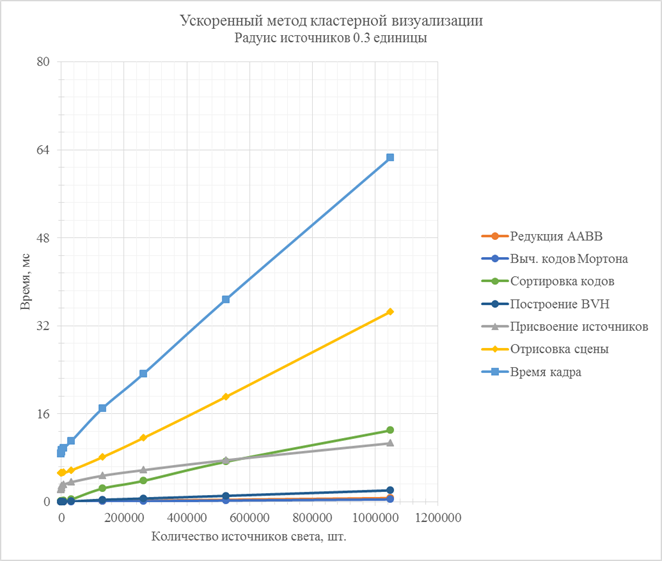
Рис. 11. Зависимости времени работы стадий ускоренного метода кластерной визуализации от количества источников света в сцене (радиус источников 0.3 единицы)
Ускоренный метод справляется с обработкой и расчетом освещенности от намного большего числа источников света. Стоит заметить, что при времени кадра в 32 мс и использовании источников света с малым радиусом (сопоставимым с размером ближайших к камере кластеров), ускоренный метод обрабатывает более 400 тысяч источников освещения, тогда как классический метод, затрачивая столько же времени на кадр, способен обрабатывать лишь около 20 тысяч источников освещения, что в 20 раз меньше.
Рост количества источников света оказывает наибольшее влияние на этап отрисовки сцены. Однако среди других этапов можно выделить этап сортировки кодов Мортона, время работы которого также растет и обгоняет другие этапы.
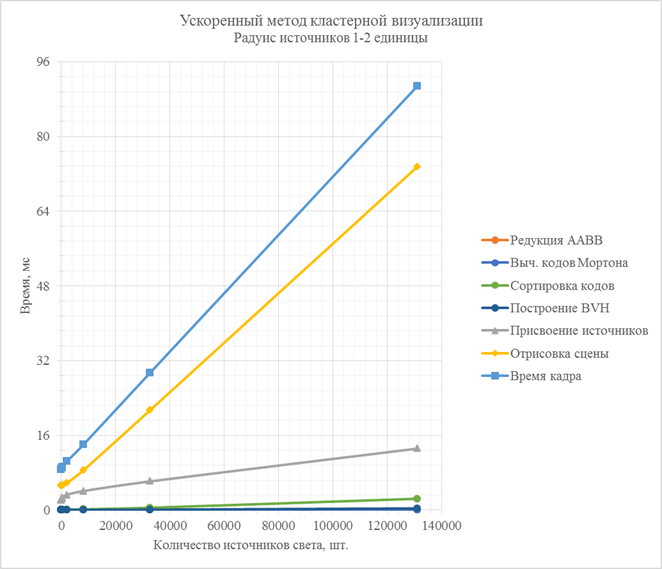
Рис. 11. Зависимости времени работы стадий ускоренного метода кластерной визуализации от количества источников света в сцене (радиус источников 1-2 единицы)
Рост количества источников большего радиуса действия оказывает существенное влияние на стадии отрисовки сцены и присвоения источников освещения, что является абсолютно закономерным процессом в силу того, что источники освещения с большим радиусом оказывают влияние сразу на большее количество кластеров.
При времени кадра в 32 мс ускоренный метод обрабатывает около 40 тысяч источников освещения, тогда как классический метод лишь 13 тысяч.
Заключение
В настоящее время визуализация с использованием кластерного подхода к освещению является наиболее перспективным методом для решения проблемы расчета освещенности при визуализации сцен с очень большим количеством источников освещения.
В работе были рассмотрены узкие места ранее реализованного классического метода кластерной визуализации, предложен способ ускорения метода. На основе предложенного способа был разработан алгоритм ускоренного метода кластерной визуализации с использованием BVH источников освещения. Также была разработана программная реализация ускоренного алгоритма и проведен сравнительный анализ с классическим методом.
Исходя из полученных результатов можно сделать вывод, что разработанная модификация действительно в разы лучше справляется с большим количеством источников освещения в сцене. Соответственно, предложенный алгоритм действительно является ускоренным.
Стоит заметить, что при увеличении радиуса действия источников освещения, временные характеристики методов немного сближаются, однако ускоренный метод все равно отрабатывает быстрее. Этап присвоения источников освещения кластерам является наиболее медленным этапом в классическом методе кластерной визуализации, что говорит о его неэффективности. Тогда как в ускоренном методе наиболее медленным этапом становится этап отрисовки сцены, что связано исключительно с вычислительной сложностью расчета освещенности. Также это говорит о том, что этап присвоения источников освещенности выполняется максимально эффективно благодаря построению и использованию BVH источников освещенности.
1. Akenine-Moller T., Haines E., Hoffman N., Pesce A., Iwanicki M., Hillaire S. Real-Time Rendering, Fourth Edition // A K Peters/CRC Press, 2018. – 1198 pg. – ISBN-13: 978-1-1386-2700-0
2. Khronos Group OpenGL Wiki: Rendering Pipeline Overview
https://www.khronos.org/opengl/wiki/Rendering_Pipeline_Overview
3. Вольф Д. OpenGL 4. Язык шейдеров. Книга рецептов / пер. с англ. Киселева А.Н. – М.: ДМК Пресс, 2015. – 368 с.
4. Olsson O., Assarsson U. Tiled Shading. // Journal of Graphics, GPU and Game Tools, 2011, vol. 15, no. 4, pp. 235-251. – DOI: 10.1080/2151237x.2011.621761
5. Takahiro H., McKee J., Yang J. Forward+: Bringing Deferred Lighting to the Next Level // Eurographics 2012 – Short Papers. Ed. By Carlos Andujar and Enrico Puppo. The Eurographics Association. – DOI: 10.2312/conf/EG2012/short/005-008
6. Olsson O., Billeter M., Assarsson U. Clustered Deferred and Forward Shading // Proceedings of ACM SIGGRAPH Symposium on High Performance Graphics 2012. C. 1-10.
7. Olsson O. Clustered shading in the wild
http://efficientshading.com/2016/09/18/clustered-shading-in-the-wild/
8. Morton G. A computer Oriented Geodetic Data Base; and a New Technique in File Sequencing // Ottawa, Canada 1ed: IBM Ltd. – 1966.
9. Harris M., Sengupta S., Owens J. Parallel Prefix Sum (Scan) with CUDA // GPU Gems 3. Ed. By Hubert Nguyen. – 2007 – 1st ed. Addison-Wesley, pp. 871-873.
10. Green O., McColl R., Bader D. GPU Merge Path – A GPU Merging Algorithm // Proceeding of the 26th ACM international conference on Supercomputing – ICS ‘12. – DOI: 10.1145/2304576.2304621