BC/NW 2019№ 2 (35):5.2
РАЗРАБОТКА ПРОГРАММНОЙ РЕАЛИЗАЦИИ АЛГОРИТМА ДЛЯ РАСПОЗНАВАНИЯ РУКОПИСНЫХ ЦИФР
Якушенкова Ю.Е.
1. Анализ задания и постановка задачи
Требуется разработать программную реализацию алгоритма для распознавания рукописных цифр. Реализация данного алгоритма должна происходить с помощью построения нейронной сети.
Для обучения и тестирования предоставлена база данных MNIST, из которой будет взято 42 000 образов для обучения и 28 000 образов для тестирования. Каждый образ представлен картинкой 28х28 пикселей с 256 градациями серого цвета.
Пример нескольких неоднозначных в идентификации цифр представлен на рисунке 1.

Рисунок 1 - Пример неоднозначных в идентификации цифр
MNIST — объёмная база данных образцов рукописного написания цифр. База данных является стандартом, предложенным Национальным институтом стандартов и технологий США с целью калибрации и сопоставления методов распознавания изображений с помощью машинного обучения в первую очередь на основе нейронных сетей. Данные состоят из заранее подготовленных примеров изображений, на основе которых проводится обучение и тестирование систем.
База данных MNIST содержит 60 000 изображений для обучения и 10 000 изображений для тестирования. Таким образом из 60 000 изображений 28 000 будет использовано для обучений, а остальные 18 000 и 10 000 из другой выборки, для тестирования. Так как по содержанию они эквивалентны.
Для решения поставленной задачи были применены следующие инструменты:
· Keras – это библиотека, позволяющая на более высоком уровне работать с нейросетями. Она упрощает множество задач, используется в быстрых экспериментах и сильно уменьшает количество однообразного кода. В качестве бекендной библиотеки для вычислений keras может использовать theano и tenzorfow;
· Jupyter Notebook – это веб-приложение с открытым исходным кодом, которое позволяет создавать документы, которые содержат код, уравнения, визуализацию и текст описания;
· Python – высокоуровневый язык программирования общего назначения, ориентированный на повышение производительности разработчика и читаемости кода;
· NumPy – библиотека являющейся инструментом более низкого уровня;
Для ускорения обучения использовалось Nvidia GPU MX150, для работы с которой были установлена соответствующая программа CUDA. CUDA является программно-аппаратная архитектура параллельных вычислений, которая позволяет существенно увеличить вычислительную производительность благодаря использованию графических процессоров фирмы Nvidia. Для обучения нейронной сети с использованием CUDA была установлена библиотека cuDNN, которая содержит оптимизированные для GPU реализации сверточных и рекуррентных сетей, различных функций активации, алгоритма обратного распространения ошибки и т.п.
2. Разработка алгоритма решения задачи
В качестве архитектуры нейронной сети была выбрана свёрточная нейронная сеть (convolutional neural network, CNN).
Свёрточные нейронные сети представляют собой особый класс нейронных сетей, в которых посредством ограничений на веса нейронов попеременно реализуются операции свёртки (convolution) и подразбиения (subsampling). Пример разницы между обычной нейронной сети и сверточной сети представлен на Рисунке 2 и Рисунке 3.
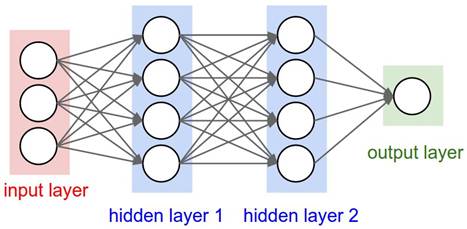
Рисунок 2 - Простая нейронная сеть
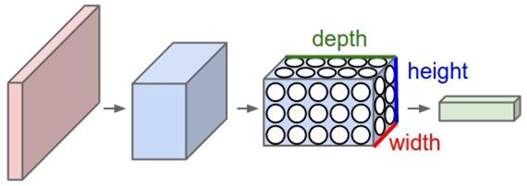
Рисунок 3 - Простая сверточная сеть
Предлагается конструкция нейронной сети из 4 слоёв: входной, принимающий изображения 28x28 пикселей со значениями от -1 до 1, выходной из 10 элементов и 2 скрытых слоя.
Алгоритм состоит из трех подзадач:
· выборка данных, которые будут использоваться для обучения и тестирования;
· обучение нейронной сети;
· тестирование нейронной сети.
Для данной сети был выбран метод обучения основанный на методе обучения с учителем (на маркированных данных) — метод обратного распространения ошибки.
Принцип работы
отдельно взятого искусственного нейрона в сущности очень прост: он вычисляет
взвешенную сумму всех элементов входного вектора ![]() , используя вектор весов
, используя вектор весов ![]() (а также аддитивную составляющую
смещения
(а также аддитивную составляющую
смещения ![]() ), а затем к результату может
применяться функция активации σ.
), а затем к результату может
применяться функция активации σ.
В последние годы в глубоком обучении получили широкое распространение полулинейные функции и их вариации — они появились в качестве простого способа сделать модель нелинейной (“если значение отрицательно, обнулим его”), но в конце концов оказались успешнее, чем исторически более популярные сигмоидальные функции, к тому же они больше соответствуют тому, как биологический нейрон передает электрический импульс. По этой причине в данной нейронной сети будет применена полулинейная функция (Rectified linear, ReLU).
Каждый нейрон однозначно определяется его весовым вектором, и главная цель обучающегося алгоритма – на основе обучающей выборки известных пар входных и выходных данных присвоить нейрону набор весов таким образом, чтобы минимизировать ошибку предсказания.
При разработке программы были определены такие понятия:
Batch – количество обучающих образцов, обрабатываемых одновременно за одну итерацию алгоритма градиентного спуска;
epochs – количество итераций обучающего алгоритма по всему обучающему множеству;
hidden_size – количество нейронов в каждом из двух скрытых слоев MLP.
Для определения обучения нейронной сети с помощью, встроенной в библиотеку Keras функции model.fit можно определить после каждой эпохи процентную величину, которая отличает различия между выходными результатами и ожидаемыми результатами.
После обучения нейронной сети происходит ее тестирования, результаты предсказаний записываются в соответствующий файл.
Тестовая и обучающая выборки представляют собой файл с расширением .cvs, где значений записаны в таблицу. С помощью соответствующих библиотек, на которых написана функция show_images можно построить каждую картинку, пример которой представлен на Рисунке 4.
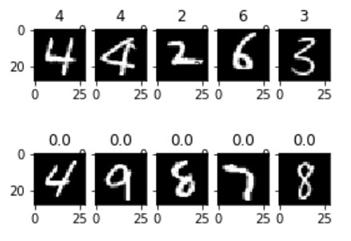
Рисунок 4 - Пример обучающей и тестовой выборки
Алгоритм работы программы, обучающей нейронную сеть представлен на Рисунке 5.
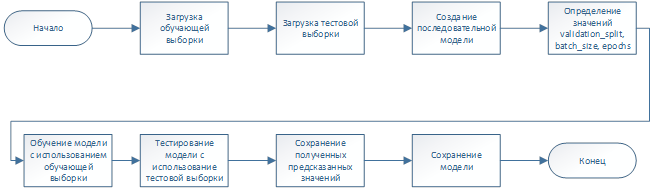
Рисунок 5 - Алгоритм работы программы
Алгоритм работы дополнительной программы, тестирующей обученную нейронную сеть и определяющей оценку обучения нейронной сети представлен на Рисунке 6.
![]()
Рисунок 6 - Алгоритм работы дополнительной программы
3. Разработка программной реализации алгоритма
Разработка программной реализации алгоритма велась на языке Python с использованием открытой программной библиотеки для машинного обучения Keras.
Основная программа представлена в листинге 1. В Листинге 2 представлен вид данных, составляющих обучающую и тестовую выборки. Листинг 3 представляет собой дополнительную программу, где тестируется уже обученная нейронная сеть и вычисляется точность предсказаний.
Листинг 1. Основная программа
#!/usr/bin/env python
# coding: utf-8
# In[1]:
import numpy as np
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.utils import np_utils
import sys
import os.path
# In[2]:
# Устанавливаем seed для повторяемости результатов
np.random.seed(42)
TRAIN_FILE = "./data/train.csv"
TEST_FILE = "./data/test.csv"
OUTPUT_FILE = "./data/submission.csv"
# Размер изображения
img_rows, img_cols = 28, 28
if not os.path.isfile(TRAIN_FILE) or not os.path.isfile(TEST_FILE):
print("""Загрузите с kaggle данные
для обучения и тестирования
(файлы train.csv и
test.csv) и запишите их в текущий каталог
""")
sys.exit()
# In[3]:
# Загружаем данные для обучения
train_dataset = np.loadtxt(TRAIN_FILE, skiprows=1, dtype='int',
delimiter=",")
# Выделяем данные для обучения
x_train = train_dataset[:, 1:]
# Переформатируем данные в 2D, бэкенд Tensorflow
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
# Нормализуем данные
x_train = x_train.astype("float32")
x_train /= 255.0
# Выделяем правильные ответы
y_train = train_dataset[:, 0]
# Преобразуем правильные ответы в категоризированное представление
y_train = np_utils.to_categorical(y_train)
# In[4]:
# Загружаем данные для предсказания
test_dataset = np.loadtxt(TEST_FILE, skiprows=1, delimiter=",")
# Переформатируем данные в 2D, бэкенд TensorFlow
x_test = test_dataset.reshape(test_dataset.shape[0], img_rows, img_cols, 1)
x_test /= 255.0
# In[5]:
# Создаем последовательную модель
model = Sequential()
model.add(Conv2D(75, kernel_size=(5, 5),
activation='relu',
input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(100, (5, 5), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(500, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
# In[6]:
# Компилируем модель
model.compile(loss="categorical_crossentropy", optimizer="adam",
metrics=["accuracy"])
print(model.summary())
# In[7]:
# Обучаем сеть
history = model.fit(x_train, y_train, validation_split=0.3, batch_size=50,
epochs=10, verbose=2)
# In[15]:
# Making predictions
predictions = model.predict(x_test)
# Converting from categorical to classed
predictions = np.argmax(predictions, axis=1)
# Saving predictions to the file
out = np.column_stack((range(1, predictions.shape[0]+1), predictions))
np.savetxt(OUTPUT_FILE, out, header="ImageId,Label",
comments="", fmt="%d,%d")
# In[16]:
import matplotlib.pyplot as plt
print(history.history.keys())
accuracy = history.history['acc']
val_accuracy = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(accuracy))
plt.plot(epochs, accuracy, 'bo', label='Training accuracy')
plt.plot(epochs, val_accuracy, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.show()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
# In[17]:
# Сохраняем сеть
model_json = model.to_json()
with open("./model/mnist_model.json", "w") as json_file:
json_file.write(model_json)
# In[18]:
import pprint
import json
# In[19]:
with open("./model/mnist_model.json", "r") as json_file:
pprint.pprint(json.loads(json_file.read()))
# In[20]:
model.save_weights("./model/mnist_model.h5")
Листинг 2. Вывод вида выборок
# In[15]:
import pandas as pd
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
trainer = pd.read_csv("./train.csv")
test = pd.read_csv("./test.csv")
# In[16]:
trainer.head(), test.head()
# In[17]:
train_features, train_labels = trainer.drop("label",
axis=1).values.astype('float32'),
trainer["label"].values.astype('int32')
train_features_images = train_features.reshape(train_features.shape[0], 28, 28)
train_labels = trainer["label"].values.astype('int32')
test_features = test.values.astype('float32')
test_features_images = test_features.reshape(test_features.shape[0], 28, 28)
def show_images(features_images, labels, length):
start = 42
for i in range(start, start+length):
plt.subplot(330 + (i+1))
plt.imshow(features_images[i], cmap=plt.get_cmap('gray'))
plt.title(labels[i])
plt.show()
show_images(train_features_images, train_labels, 5)
show_images(test_features_images, np.zeros(test_features_images.shape[0]), 5)
Листинг 3. Дополнительная программа
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import model_from_json
print("Загружаю сеть из файлов")
# Загружаем данные об архитектуре сети
json_file = open("./model/mnist_model.json", "r")
loaded_model_json = json_file.read()
json_file.close()
# Создаем модель
loaded_model = model_from_json(loaded_model_json)
# Загружаем сохраненные веса в модель
loaded_model.load_weights("./model/mnist_model.h5")
print("Загрузка сети завершена")
# Загружаем данные (X_train, y_train), (X_test, y_test) = mnist.load_data()
(_, _), (X_test, y_test) = mnist.load_data()
# Размер изображения
img_rows, img_cols = 28, 28
# Преобразование размерности изображений
X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols, 1)
#X_test = X_test.reshape(img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
# Нормализация данных
X_test = X_test.astype('float32')
X_test /= 255
# Преобразуем метки в категории
Y_test = np_utils.to_categorical(y_test, 10)
# Компилируем загруженную модель
loaded_model.compile(loss="categorical_crossentropy", optimizer="SGD", metrics=["accuracy"])
# Оцениваем качество обучения сети загруженной сети на тестовых данных
scores = loaded_model.evaluate(X_test, Y_test, verbose=0)
print("Точность работы загруженной сети на тестовых данных: %.2f%%" % ((scores[1]*100)))
Нейросеть была обучена на выборке из 42 000 изображений рукописный цифр и протестирована на выборке из 28 000 изображений. Тестирование проводилось на ноутбуке со следующими характеристиками:
· CPU: intel Сore i7-8550U CPU @1.80GHZ;
· ОЗУ: 8 ГБ;
· ОС: Windows 10 x64;
Версии установленного ПО:
· Python 3.6
· CUDA 9.0
· cUDNN 7.4.1.5
· Keras 2.2.4
Результаты тестирования выводятся в Jupyter Notebook и сохраняются в файл submission.csv.
Результат обучения нейронной сети представлен на Рисунке 7.
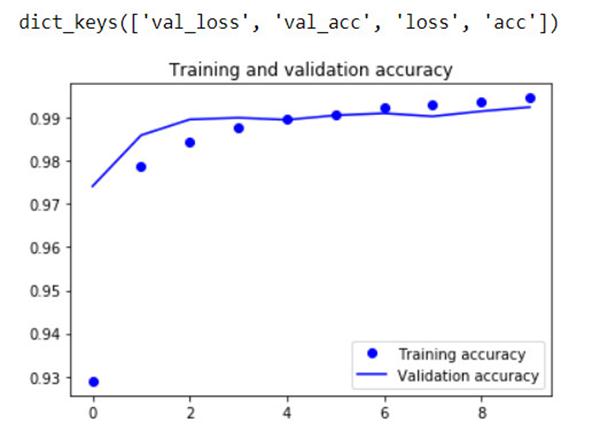
Рисунок 7а - Представление точности верных ответов и представление не предсказанных данных
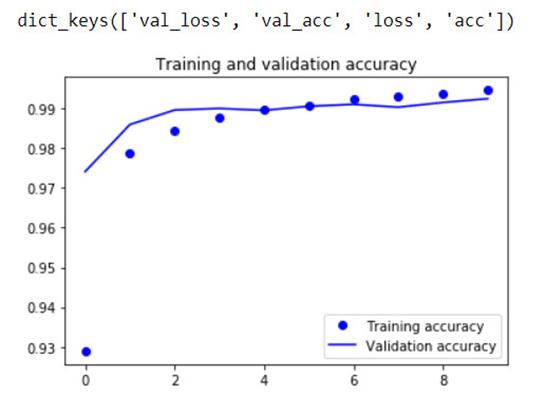
Рисунок 7б - Представление не предсказанных данных
Результаты тестирования сети приведены на Рисунке 8.
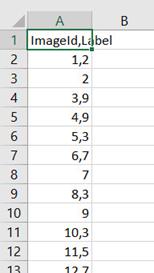
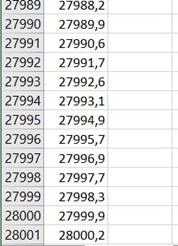
Рисунок 8 - Результаты предсказания на основе тестовой выборки
Результат вывода дополнительной программы представлены на рисунке 9.
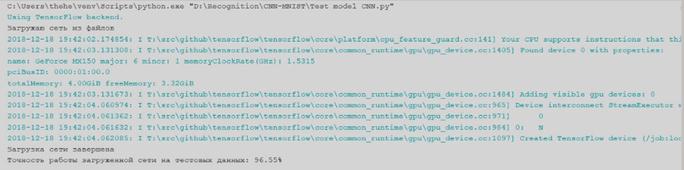
Рисунок 9 - Результаты работы дополнительной программы
В результате работы были построены сверточные нейронные сети с использованием библиотеки Keras. Были использованы способы построения сети, способы обучения и тестирования.
В результате тестирования данной нейронной сети был получен процент распознавания тестовой выборки равный 96,55%, что является удовлетворительным результатом.
Однако нельзя говорить, что данная конфигурация сети является оптимальной для решения этой задачи.
Возможным улучшением данной конфигурации сети будет построение не сверточной сети, а рекуррентной сети или изменения числа скрытых слоев. Так же возможно изменение количества нейронов в сетях.
1. Л. Шапиро и Дж. Стокман. «Компьютерное зрение». В: М.: Бином. Лаборатория знаний 752 с., (2006).
2. Т. Рашид. «Создаем нейронную сеть». Диалектика 274 с., (2017).
3. М. В. Сысоева, И. В. Сысоев. «Программирование для «нормальных» с нуля на языке Python». Базальт СПО 180 с., (2018).