применение
модели асинхроннЫх вычислЕНИЙ в программных системах распределенной обработки
данных
А.С. Казарицкий, Ю.Е. Мороховец
(Москва, Московский Энергетический Институт (ТУ), Россия)
В настоящее время существует большое число задач, решение которых основано на применении концепции распределенных вычислений. Это научные задачи, также задачи, связанные с предоставлением информационных услуг (например, осуществления электронных платежей), задачи контроля и управления объектами. Последние два вида задач для своего решения, как правило, требуют режима реального времени.
Для представления алгоритмов перечисленных задач существует целый ряд вычислительных моделей. Обычно механизмы, заложенные в эти модели, имеют либо достаточно общий характер (например, MPI [1]), либо наоборот узко специализированны (например, ScaLAPACK [2]). Обсуждаемая в докладе модель асинхронных вычислений, на наш взгляд, позиционирована именно как средство описания алгоритмов задач указанных выше типов. Исследованию возможностей ее применения в распределенных системах обработки информации и посвящена данная работа.
Асинхронные вычислительные модели – класс моделей параллельных вычислений, в которых алгоритмы задач разбиваются на функционально обособленные части, представляемые компонентами, а потоки данных между компонентами буферизируются. Компоненты модели – автоматы специального вида с конечным набором состояний и фиксированной диаграммой переходов.
Различают несколько подклассов асинхронных вычислительных моделей, среди них асинхронные вычислительные сети [3] и асинхронные вычислительные конвейеры [4].
Для асинхронных вычислительных сетей характерно наличие конечных, завершающих состояний – совокупности соответствующих состояний ее компонентов. Для сетей, ориентированных на однократное получение результата, достижение завершающего состояния является целью их функционирования. Для конвейеров, наоборот, целью являются непрерывные параллельные вычисления, связанные с получением и выдачей данных. Можно сказать, что первый случай применим для спецификации расчетных научных задач, второй – для спецификации интерактивных информационных систем, систем управления технологическими процессами и т.д.
Базовая модель асинхронных вычислений предусматривает наличие четырех типов объектов: компонента, буфера, источника и приемника данных. Связи между объектами – «точка-точка», направленные. Компонент является активным объектом, то есть имеет собственную логику работы и может инициировать обращение к другим объектам. Объекты остальных типов пассивны.
Для эффективного применения базовой модели в системах распределенной обработки данных предлагается ее расширение за счет введения нового типа объектов – сервисов. Сервисы являются пассивными объектами, однако они функционируют на уровне всей сети (конвейера) и к ним могут обращаться одновременно несколько активных компонентов. Сервисы в модели могут нести любую семантическую нагрузку, например, являться ассоциативными запоминающими устройствами, базами данных или их отдельными таблицами, каналами сообщений, генераторами уникальных идентификаторов, арбитрами доступа и т.д. Обычно сервисы выполняют системные функции, однако могут, например, просто генерировать псевдослучайные числа. Хотя функцию каждого сервиса можно реализовать с помощью компонентов, введение в модель некоторого количества стандартных сервисов позволяет расширить возможности прикладного уровня описания задачи.
Для описания алгоритма задачи с помощью асинхронной вычислительной сети необходимо специфицировать входной язык. К нему предъявляются следующие требования:
- язык должен быть простым, не требующих навыков программирования, например, являться макрорасширением одного из известных языков высокого уровня;
- язык должен быть близок по своим характеристикам к языку реализации программной системы распределенной обработки данных, а, в идеале, совпадать с ним.
Учитывая эти требования, предлагается использовать графический способ задания распределенных алгоритмов, например, с помощью схем и диаграмм систем автоматизированного проектирования ПО – CASE-систем. Среди них можно выделить два типа систем – структурные и объектные системы. И те, и другие включают множество нотаций и диалектов. Наиболее распространенными из них являются структурная нотация Гейн-Сарсон [5] и объектная UML-нотация (Unified Modeling Language – универсальный язык моделирования) [6]. Если использовать стандартные CASE-средства для описания алгоритма в терминах модели асинхронных вычислений, то с помощью стандартных механизмов построения отчетов можно получать готовые (или почти готовые) модели вычислений для каждой конкретной задачи. На наш взгляд для рассматриваемого класса задач целесообразно применять второй подход – объектную нотацию.
Рассмотрим пример применения модели асинхронных вычислений для построения системы распределенной обработки данных. Задача состоит в круглосуточной регистрации прихода и ухода сотрудников предприятия, накоплении регистрационных данных и построении соответствующих отчетов. Для решения этой задачи требуется аппаратно-программный комплекс, включающий средства идентификации сотрудника (такие, как считыватели магнитной карты или отпечатка пальца), а также средства регистрации событий, связанных с проходом сотрудников, обеспечивающие накопление информации и построение отчетов.
Как видно, для описания алгоритма этой задачи может быть применена модель асинхронного вычислительного конвейера. В этой модели присутствуют следующие типы компонентов: компоненты первого типа получают сообщения с датчиков, компоненты второго типа регистрируют эти события, компоненты третьего типа строят отчет с заданными характеристиками и выдают пользователю. Количество компонентов первого типа соответствует количеству устройств считывания. Количество компонентов второго типа зависит от механизма регистрации. Если она осуществляется путем добавления информации о проходе – времени, месте, сотруднике и т.д. – в базу данных, то в рассматриваемой модели регистрирующий компонент, равно как и компонент построения отчетов, может быть один. Конвейер имеет один сервис, обеспечивающий хранение и доступ к информации о проходах – упомянутая выше база данных. Возьмем, например, такую конфигурацию конвейера: два компонента первого типа (две проходные), один компонент второго типа (регистратор событий), один компонент третьего типа (построитель отчетов) и один сервис (хранение данных). Графическое представление этой модели в структурном виде (с использованием нотации, описанной в [4]) показано на рис. 1.
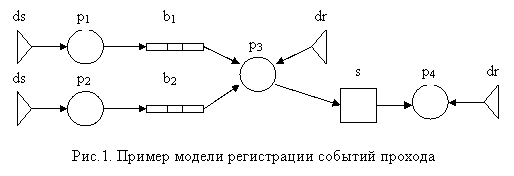
На рис.
1. используются обозначения: ds
– источники данных, dr
– приемники данных, b1
и b2 – буферизованные
связи, p1 и p2 – компоненты
первого типа, p3 –
компонент второго типа, p4
– компонент третьего типа,
s – сервис хранения
данных.
Предложенные подходы применяются в разработке программной системы распределенной обработки данных, выполняемой на кафедре ВМСиС МЭИ (ТУ).
В данной работе рассматривалось применение модели асинхронных вычислительных сетей в программных системах распределенной обработки данных, в частности для решения задач сбора и обработки данных. Было предложено уточнение базовой модели, а именно: расширение модели за счет введения объектов нового типа - сервисов. Также было предложено представление алгоритма конкретной задачи в графическом виде с помощью стандартных CASE-средств, с последующим получением модели распределенной обработки данных.
Разрабатываемая программная система позволит специфицировать алгоритмы распределенной обработки данных, подобные рассмотренному выше алгоритму, отлаживать и выполнять их, реализуя соответствующие процессы распределенной обработки, а также проводить анализ исходных алгоритмов с последующим их уточнением.
ЛИТЕРАТУРА
1. Немнюгин С.А., Стесик О.Л. Параллельное программирование для многопроцессорных вычислительных систем. – СПб.: БХВ-Петербург, 2002. –400 с.
2. Blackford L. S., Choi J., Cleary A.,
at alias. ScaLAPACK Users' Guide, Society for Industrial and Applied
Mathematics, 1997.
3. Строева
Т.М., Фальк В.Н. Асинхронные вычислительные сети: АВС-модель и АВС-система
параллельного программирования. // Кибернетика, 1981, № 3. – С. 90-96.
4. Калинина
Г.А., Ладыгин И.И., Мороховец Ю.Е. Редуцированная модель вычислительного
конвейера на регулярных компонентах. // Доклады МК «Информационные средства и технологии», том 1. – М.: Янус-К, 2002
– С. 14-17.
5. Калянов Г.Н. CASE: структурный системный анализ. – М.: ЛОРИ, 1996. – 364 с.
6. Якобсон А., Буч Г., Рамбо Дж. Унифицированный
процесс разработки программного обеспечения. – Спб.: Питер, 2002. – 496 с.