BC/NW 2006, №2, (9) :12.8
ПОДСИСТЕМА
УТОЧНЯЕМОГО ПОИСКА СЕМАНТИЧЕСКОЙ ИНФОРМАЦИИ В ФОРМЕ ГРАФОВЫХ МОДЕЛЕЙ
В.А. Кохов, А.А. Незнанов, С.В. Ткаченко
(Москва, Московский энергетический институт
(Технический университет), Россия)
В настоящее время актуальна
задача быстрого поиска структурной информации с учетом семантики запроса.
Разнообразные документы (даже текстовые) при семантическом поиске все чаще
представляются в виде семантических сетей. Это связано с развитием языков
представления информации в структурированной и атрибутированной форме с учётом
семантики (XML, RDF, OWL, OIL и др.), развитием graph mining
и актуальным переходом от World Wide Web
к Semantic Web
[1]. В докладе предложен оригинальный
программный комплекс структурного поиска по структурному запросу, реализованный
в АСНИ «Graph Model Workshop» (www.graphmodel.com).
АСНИ «Graph Model Workshop» [2] расширена новыми
средствами структурного поиска. Их особенностью является иерархическое многоэтапное сужение области поиска с использованием ранжированных по сложности числовых и
структурных инвариантов графовых моделей систем (ГМС). Это позволяет не
только существенно повысить эффективность, но и достичь значительной гибкости
проведения поиска. Так, в случае неудовлетворительного результата поискового
запроса появляется возможность не проводить весь процесс сначала, а изменить
критерии поиска только на последнем этапе. Исходной областью поиска является
вся база структурной информации, загруженная в АСНИ.
Способ задания критерия
поиска для каждого этапа поиска разбит на три части (что обеспечивает гибкость
и эффективность реализации, а также упрощает программные интерфейсы для
расширения средств поиска).
1. Используемый инвариант ГМС,
то есть вычисляющее его программное
расширение АСНИ (ПР) и параметры его запуска. При этом если для базы ГМС
уже вычислялся данный инвариант, то его повторное вычисление не выполняется, а
только сравнивается его значение со значением для графа-шаблона. В качестве
инварианта может выступать сама ГМС (подструктурный поиск), её числовые и
структурные инварианты (например,
g-
или b-модель [3]), метаинформация о ГМС (название, описание и др.).
2. Метод сравнения инвариантов
и получения коэффициента сходства ГМС, также в виде ПР и параметров его запуска
(рис. 1).
3. Ограничения на значения
инварианта и коэффициента сходства.
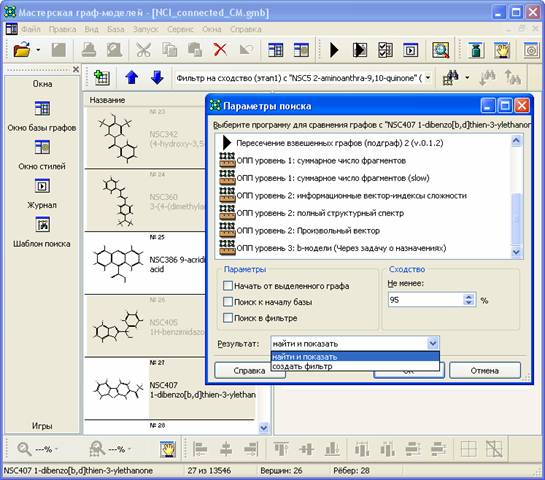
Рис. 1. Выбор расширения для сравнения инвариантов
в АСНИ «GMW»
В новой версии АСНИ исходная
база ГМС не изменяется в процессе иерархического поиска. Механизм поиска
изменяет только связанную с базой ГМС базу
данных результатов экспериментов (БДР). Основными объектами БДР при этом
являются фильтры базы ГМС
(определяющие области поиска), таблицы
со значениями инвариантов (связанные с ГМС отношением 1:1) и таблицы
попарного сходства. Количество ГМС может достигать десятков миллионов (объём
базы ГМС – не более 2ГБ), общий объём БДР не ограничен (объём одной таблицы –
не более 2ГБ). Переход к многоуровневой системе представления информации о
структурах в БДР, которая обрабатывается ПР, набор которых расширяем (и которые
могут создаваться пользователями), позволяет предложить более общие и
эффективные схемы работы с диском, чем предлагавшиеся ранее [4].
Проведение многоэтапного
иерархического поиска включает: (1) выбор типа используемых инвариантов; (2)
расчёт значений инвариантов на данном этапе; (3) задание критериев сравнения
(выбор ПР) и выполнение поиска с созданием нового фильтра; (4) повторение
выполнения пунктов 1-3 для новой области поиска (фильтра) или интерактивный
анализ результатов на последнем этапе. Число этапов не ограничено.
Многокритериальный структурный поиск реализуется в АСНИ путём выбора на очередном
этапе другой ГМС в качестве шаблона поиска. Примером может служить поиск ГМС, содержащих заданный набор фрагментов
(сложных объектов в семантических сетях): каждый этап – определение изоморфного
вложения одного из фрагментов в ГМС, оставшиеся после проведения предыдущего
этапа. Для повышения эффективности
поиска набор фрагментов предварительно сортируется по возрастанию какого-либо
индекса сложности (в простейшем случае – число вершин). Другой пример – поиск
ГМС, сходных с заданным набором структур.
Варьируя лимит значения коэффициента сходства на различных этапах, можно
повышать или понижать значимость отдельных структур из набора.
Для построения и
исследования широкого класса структурных инвариантов (g‑моделей и их
подмоделей) создана новая подсистема «gs-модели». Она поддерживает обобщённый подструктурный подход к анализу
сходства, и, соответственно, наиболее сложный вариант структурного поиска по
уточняемому сходству с одной из ГМС исследуемой базы. Основной частью
подсистемы является расширение для построения gs‑моделей, использующее редактор профилей моделей GSPED (рис. 2).
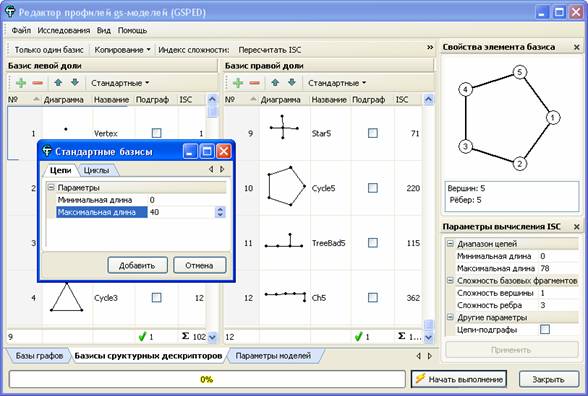
Рис. 2. Интерфейс расширения АСНИ для создания g‑моделей
Подсистема позволяет строить
более широкие классы подмоделей g‑моделей
в произвольных априори заданных базисах структурных дескрипторов, что
обеспечивает возможность проведения более целенаправленного структурного поиска
с учётом сходства расположения фрагментов
заданных типов в топологии ГМС. Подсистема разработана в среде Borland Developer Studio 2006, содержит более 350 КБ
исходного кода новых алгоритмов (всего более 1,5 МБ исходного кода) и занимает
6 МБ на жёстком диске.
Использование g-моделей позволяет использовать
критерии поиска, отличные от стандартных подструктурных (exact and inexact matching), при анализе семантических
сетей, определяющих онтологию и эпистемологию документов [5]. При этом
актуализируется поиск по нечёткому сходству весов, то есть по g‑моделям с учётом
весов вершин, что определяет направление дальнейших исследований (рис. 3).
Рис. 3. Примеры семантических сетей
ЛИТЕРАТУРА
1. W3C Semantic Web Activity. (www.w3.org/2001/sw)
2. Кохов В.А., Незнанов А.А., Ткаченко С.В. Новые программные средства
для поиска структурной информации. // Труды МНТК «Информационные средства и
технологии». (МФИ-2005), Т.2, Москва, 2005.
(http://network-journal.mpei.ac.ru/cgi-bin/main.pl?l=ru&n=7&pa=11&ar=11)
3. Кохов
В.А. Модели и методы для анализа
сходства структур систем с учетом сходства расположения фрагментов. Тезисы
докладов научной сессии МИФИ-2006. Т3. Интеллектуальные системы и технологии. М. МИФИ. 2006.
Wei Wang, Chen Wang, Yongtai Zhu, Baile Shi, Jian Pei, Xifeng Yan,
Jiawei Han. GraphMiner: a structural pattern-mining system for large disk-based
graph databases and its applications, Proceedings of the 2005 ACM SIGMOD
international conference on Management of data, June 14-16, 2005, Baltimore,
Maryland.
4. The DARPA Agent Markup Language Homepage. (http://www.daml.org